7.3 完全信息的价值 (The Value of Perfect Information)
在到目前为止我们涵盖的所有内容中,我们通常总是假设我们的智能体拥有特定问题所需的所有信息和/或无法获取新信息。在实践中,情况并非如此,决策中最重要的部分之一是知道是否值得收集更多证据来帮助决定采取哪种行动。观察新证据几乎总是有一些成本,无论是在时间、金钱还是其他某种媒介方面。在本节中,我们将讨论一个非常重要的概念——完全信息的价值 (value of perfect information, VPI)——它在数学上量化了如果智能体观察到一些新证据,其最大期望效用预计会增加多少。我们可以将学习某些新信息的 VPI 与观察该信息相关的成本进行比较,以决定是否值得观察。
7.3.1 通用公式 (General Formula)
与其简单地给出计算新证据的完全信息价值的公式,不如让我们通过一个直观的推导。我们从上面的定义中知道,完全信息的价值是我们决定观察新证据时期望最大期望效用增加的量。我们知道给定当前证据 \(e\) 的当前最大效用:
\[MEU(e) = \max_a\sum_sP(s \mid e)U(s, a)\]此外,我们知道如果在采取行动之前观察到一些新证据 \(e'\),此时我们行动的最大期望效用将变为
\[MEU(e, e') = \max_a\sum_sP(s \mid e, e')U(s, a)\]然而,请注意我们不知道我们会得到什么新证据。例如,如果我们事先不知道天气预报并选择观察它,我们观察到的预报可能是好或坏。因为我们不知道我们会得到什么新证据 \(e'\),我们必须将其表示为随机变量 \(E'\)。如果我们不知道从观察中获得的证据会告诉我们什么,我们如何表示如果我们选择观察一个新变量我们将获得的新 MEU?答案是计算最大期望效用的期望值,虽然这很拗口,但这是自然的方法:
\[MEU(e, E') = \sum_{e'}P(e' \mid e)MEU(e, e')\]观察一个新的证据变量会产生不同的 MEU,其概率对应于观察到证据变量每个值的概率,因此通过如上计算 \(MEU(e, E')\),我们计算如果我们选择观察新证据,我们期望的新 MEU 是多少。我们现在差不多完成了——回到我们对 VPI 的定义,我们想找到如果我们选择观察新证据,我们的 MEU 预计会增加多少。我们知道我们当前的 MEU 和如果我们选择观察的新 MEU 的期望值,所以预期的 MEU 增加仅仅是这两项的差!确实,
\[\boxed{VPI(E' \mid e) = MEU(e, E') - MEU(e)}\]其中我们可以将 \(VPI(E' \mid e)\) 读作“给定我们当前的证据 e,观察新证据 E’ 的价值”。让我们通过最后一次重温我们的天气场景来通过一个例子:
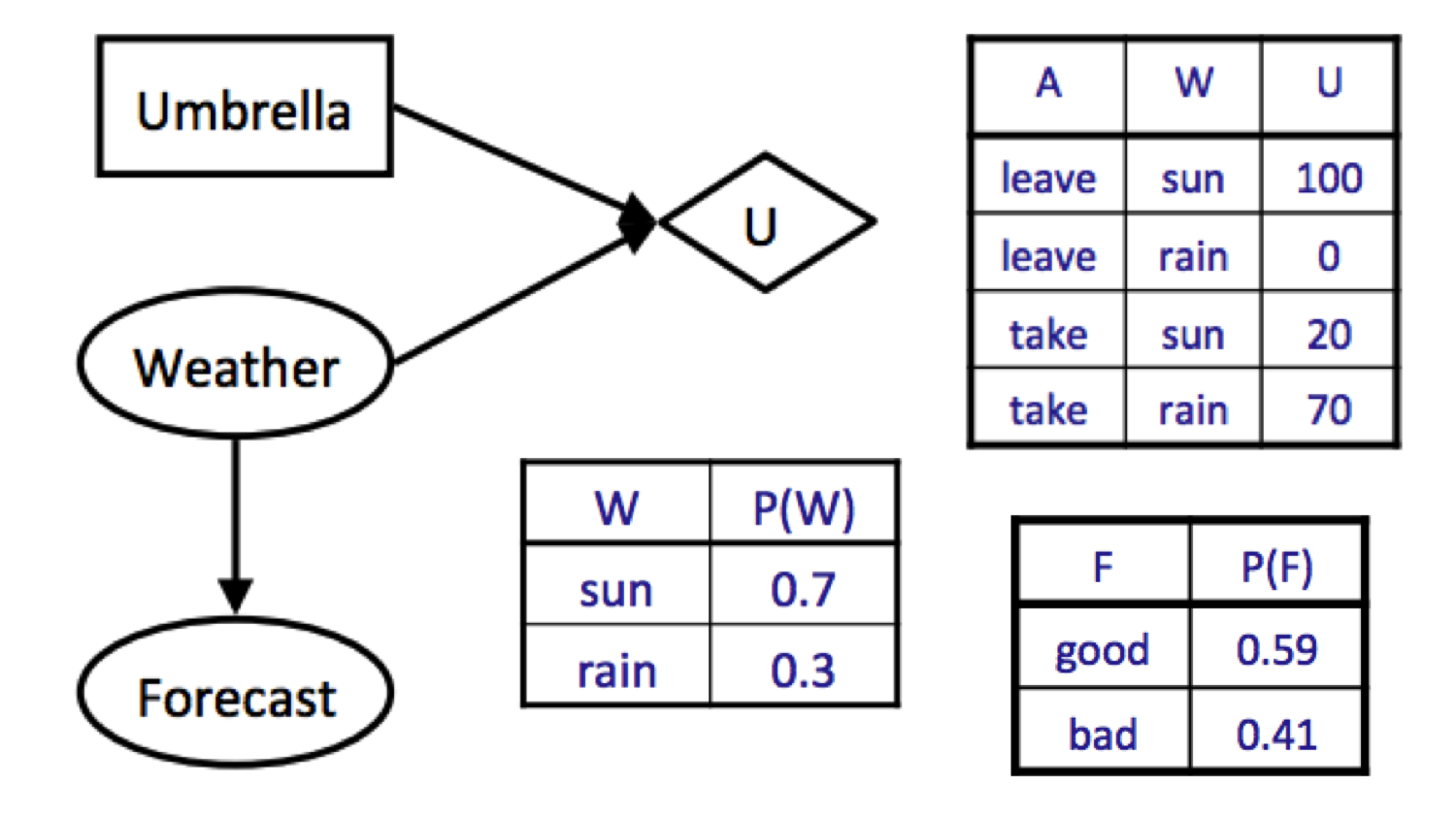
如果我们不观察任何证据,那么我们的最大期望效用可以计算如下:
\[\begin{aligned} MEU(\varnothing) &= \max_aEU(a) \\ &= \max_a\sum_wP(w)U(a, w) \\ &= \max\{0.7 \cdot 100 + 0.3 \cdot 0, 0.7 \cdot 20 + 0.3 \cdot 70\} \\ &= \max\{70, 35\} \\ &= 70 \end{aligned}\]注意,当我们没有证据时的惯例是写 \(MEU(\varnothing)\),表示我们的证据是空集。现在假设我们正在决定是否观察天气预报。我们已经计算出 \(MEU(F = \text{bad}) = 53\),并且让我们假设对 \(F = \text{good}\) 运行相同的计算得出 \(MEU(F = \text{good}) = 95\)。我们现在准备计算 \(MEU(e, E')\):
\[\begin{aligned} MEU(e, E') &= MEU(F) \\ &= \sum_{e'}P(e' \mid e)MEU(e, e') \\ &= \sum_{f}P(F = f)MEU(F = f) \\ &= P(F = \text{good})MEU(F = \text{good}) + P(F = \text{bad})MEU(F = \text{bad}) \\ &= 0.59 \cdot 95 + 0.41 \cdot 53 \\ &= 77.78 \end{aligned}\]因此我们得出结论 \(VPI(F) = MEU(F) - MEU(\varnothing) = 77.78 - 70 = \boxed{7.78}\)。
7.3.2 VPI 的属性 (Properties of VPI)
完全信息的价值有几个非常重要的属性,即:
-
非负性 (Nonnegativity). \(\forall E', e\:\: VPI(E' \mid e) \geq 0\)
观察新信息总是允许你做出更明智的决定,因此你的最大期望效用只会增加(或者如果信息与你必须做出的决定无关,则保持不变)。 -
非可加性 (Nonadditivity). 一般来说 \(VPI(E_j, E_k \mid e) \neq VPI(E_j \mid e) + VPI(E_k \mid e)\)。
这可能是这三个属性中最难直观理解的一个。这是真的,因为通常观察一些新证据 \(E_j\) 可能会改变我们对 \(E_k\) 的关心程度;因此,我们不能简单地将观察 \(E_j\) 的 VPI 加到观察 \(E_k\) 的 VPI 上以获得观察两者的 VPI。相反,观察两个新证据变量的 VPI 等同于观察一个,将其纳入我们当前的证据,然后观察另一个。这由 VPI 的顺序无关性属性封装,下面将详细描述。 -
顺序无关性 (Order-independence). \(VPI(E_j, E_k \mid e) = VPI(E_j \mid e) + VPI(E_k \mid e, E_j) = VPI(E_k \mid e) + VPI(E_j \mid e, E_k)\)
无论观察顺序如何,观察多个新证据都会产生相同的最大期望效用增益。这应该是一个相当直接的假设——因为我们在观察任何新证据变量之前实际上并没有采取任何行动,所以我们是一起观察新证据变量还是以某种任意顺序观察并不重要。