5.3 无模型学习 (Model-Free Learning)
继续进行无模型学习!有几种无模型学习算法,我们将介绍其中的三种:直接评估、时间差分学习和 Q-学习。直接评估和时间差分学习属于一类称为被动强化学习 (passive reinforcement learning) 的算法。在被动强化学习中,代理被赋予一个要遵循的策略,并在经历情节时学习该策略下状态的值,这正是当 \(T\) 和 \(R\) 已知时 MDP 的策略评估所做的。Q-学习属于第二类无模型学习算法,称为主动强化学习 (active reinforcement learning),在此期间,学习代理可以使用它收到的反馈在学习时迭代更新其策略,直到经过充分探索后最终确定最优策略。
5.3.1 直接评估 (Direct Evaluation)
我们将介绍的第一种被动强化学习技术称为直接评估 (direct evaluation),这种方法就像它的名字听起来那样枯燥和简单。直接评估所做的就是固定某个策略 \(\pi\),并让代理在遵循 \(\pi\) 的同时经历几个情节。当代理通过这些情节收集样本时,它会维护从每个状态获得的总效用以及访问每个状态的次数的计数。在任何时候,我们都可以通过将从 \(s\) 获得的总效用除以 \(s\) 被访问的次数来计算任何状态 \(s\) 的估计值。让我们在之前的示例上运行直接评估,回想一下 \(\gamma = 1\)。
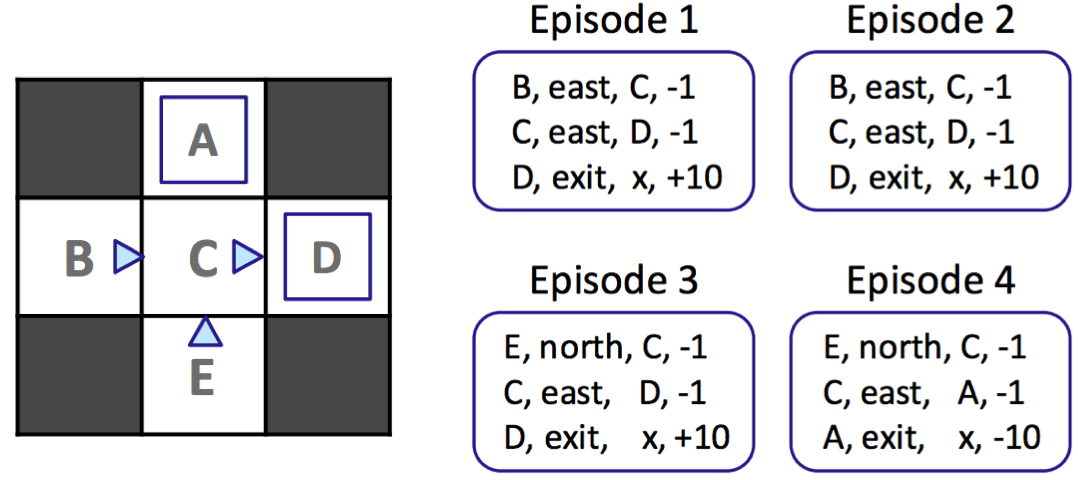
浏览第一个情节,我们可以看到从状态 \(D\) 到终止我们获得了总奖励 \(10\),从状态 \(C\) 我们获得了总奖励 \((-1) + 10 = 9\),从状态 \(B\) 我们获得了总奖励 \((-1) + (-1) + 10 = 8\)。完成此过程将得出每个状态跨情节的总奖励和生成的估计值,如下所示:
| \(\mathbf{s}\) | \(\mathbf{Total\ Reward}\) | \(\mathbf{Times\ Visited}\) | \(\mathbf{V^{\pi}(s)}\) |
|---|---|---|---|
| \(A\) | \(-10\) | \(1\) | \(-10\) |
| \(B\) | \(16\) | \(2\) | \(8\) |
| \(C\) | \(16\) | \(4\) | \(4\) |
| \(D\) | \(30\) | \(3\) | \(10\) |
| \(E\) | \(-4\) | \(2\) | \(-2\) |
虽然直接评估最终会学习每个状态的状态值,但它收敛通常不必要地慢,因为它浪费了关于状态之间转移的信息。
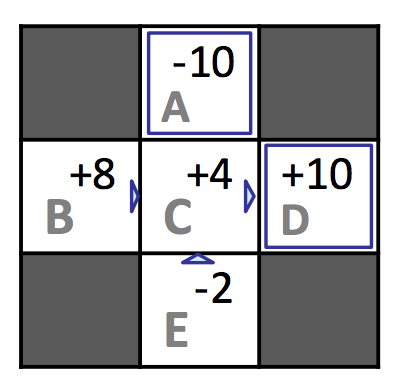
在我们的示例中,我们计算出 \(V^{\pi}(E) = -2\) 和 \(V^{\pi}(B) = 8\),尽管根据我们收到的反馈,这两个状态都只有 \(C\) 作为后继状态,并且在转移到 \(C\) 时产生相同的奖励 \(-1\)。根据贝尔曼方程,这意味着 \(B\) 和 \(E\) 在 \(\pi\) 下应该具有相同的值。然而,在我们的代理处于状态 \(C\) 的 4 次中,它有 3 次转移到 \(D\) 并获得奖励 \(10\),有 1 次转移到 \(A\) 并获得奖励 \(-10\)。纯属偶然,它收到 \(-10\) 奖励的那一次是从状态 \(E\) 而不是 \(B\) 开始的,但这严重歪曲了 \(E\) 的估计值。如果有足够的情节,\(B\) 和 \(E\) 的值将收敛到它们的真实值,但像这样的情况会导致过程比我们希望的要长。这个问题可以通过选择使用我们的第二种被动强化学习算法,时间差分学习来缓解。
5.3.2 时间差分学习 (Temporal Difference Learning)
时间差分学习 (TD learning) 使用了_从每次经验中学习_的想法,而不是像直接评估那样简单地跟踪总奖励和状态访问次数并在最后学习。在策略评估中,我们使用由我们的固定策略和贝尔曼方程生成的方程组来确定该策略下状态的值(或像值迭代那样使用迭代更新)。
\[V^{\pi}(s) = \sum_{s'}T(s, \pi(s), s')[R(s, \pi(s), s') + \gamma V^{\pi}(s')]\]这些方程中的每一个都将一个状态的值等同于该状态后继者的折扣值的加权平均值加上转移到它们所获得的奖励。TD 学习试图回答如何在没有权重的情况下计算这个加权平均值的问题,通过指数移动平均 (exponential moving average) 巧妙地做到了这一点。我们首先初始化 \(\forall s, \:\: V^{\pi}(s) = 0\)。在每个时间步,代理从状态 \(s\) 采取动作 \(\pi(s)\),转移到状态 \(s'\),并获得奖励 \(R(s, \pi(s), s')\)。我们可以通过将收到的奖励与 \(\pi\) 下 \(s'\) 的折扣当前值相加来获得一个样本值 (sample value):
\[\text{sample} = R(s, \pi(s), s') + \gamma V^{\pi}(s')\]这个样本是 \(V^{\pi}(s)\) 的新估计。下一步是将这个采样估计合并到我们现有的 \(V^{\pi}(s)\) 模型中,使用指数移动平均,它遵循以下更新规则:
\[V^{\pi}(s) \leftarrow (1-\alpha)V^{\pi}(s) + \alpha \cdot \text{sample}\]上面,\(\alpha\) 是一个受 \(0 \leq \alpha \leq 1\) 约束的参数,称为学习率 (learning rate),它指定了我们要分配给我们现有的 \(V^{\pi}(s)\) 模型 (\(1 - \alpha\)) 的权重,以及我们要分配给新采样估计 (\(\alpha\)) 的权重。通常以 \(\alpha = 1\) 的学习率开始,相应地将 \(V^{\pi}(s)\) 分配给第一个 \(\text{sample}\) 的任何值,并慢慢将其缩小到 0,此时所有后续样本将被归零并停止影响我们的 \(V^{\pi}(s)\) 模型。
让我们停下来分析一下更新规则。通过定义 \(V^{\pi}_k(s)\) 和 \(\text{sample}_k\) 分别为第 \(k\) 次更新和第 \(k\) 个样本后状态 \(s\) 的估计值,来标注我们模型在不同时间点的状态,我们可以重新表达我们的更新规则:
\[V^{\pi}_{k}(s) \leftarrow (1-\alpha)V^{\pi}_{k-1}(s) + \alpha \cdot \text{sample}_k\]\(V^{\pi}_k(s)\) 的这个递归定义展开起来非常有趣:
\[V^{\pi}_{k}(s) \leftarrow \alpha \cdot [(1-\alpha)^{k-1} \cdot \text{sample}_1 + ... + (1-\alpha) \cdot \text{sample}_{k-1} + \text{sample}_k]\]因为 \(0 \leq (1 - \alpha) \leq 1\),随着我们将数量 \((1 - \alpha)\) 提高到越来越大的幂,它越来越接近 0。根据我们推导出的更新规则展开,这意味着旧样本被赋予指数级更少的权重,这正是我们想要的,因为这些旧样本是使用我们 \(V^{\pi}(s)\) 模型的旧(因此更差)版本计算的!这就是时间差分学习的美妙之处——通过一个简单直接的更新规则,我们能够:
- 在每个时间步学习,从而在获得状态转移信息时使用它们,因为我们在样本中使用 \(V^{\pi}(s')\) 的迭代更新版本,而不是等到最后才执行任何计算。
- 给旧的、可能不太准确的样本赋予指数级更少的权重。
- 比直接评估用更少的情节更快地收敛到学习真实状态值。
5.3.3 Q-学习 (Q-Learning)
直接评估和 TD 学习最终都会学习到它们遵循的策略下所有状态的真实值。然而,它们都有一个主要的固有问题——我们想为我们的代理找到一个最优策略,这需要知道状态的 Q-值。要从我们拥有的值计算 Q-值,我们需要贝尔曼方程所规定的转移函数和奖励函数。
\[Q^*(s, a) = \sum_{s'} T(s, a, s')[R(s, a, s') + \gamma V^*(s')]\]因此,TD 学习或直接评估通常与某种基于模型的学习结合使用,以获取 \(T\) 和 \(R\) 的估计值,从而有效地更新学习代理遵循的策略。这可以通过一种称为 Q-学习 (Q-learning) 的革命性新思想来避免,该思想提出直接学习状态的 Q-值,绕过永远不需要知道任何值、转移函数或奖励函数的需求。因此,Q-学习完全是无模型的。Q-学习使用以下更新规则来执行所谓的 Q-值迭代 (Q-value iteration):
\[Q_{k+1}(s, a) \leftarrow \sum_{s'}T(s, a, s')[R(s, a, s') + \gamma \max_{a'} Q_k(s', a')]\]注意,此更新仅是对值迭代更新规则的轻微修改。实际上,唯一真正的区别是 \(\max\) 算子在动作上的位置发生了变化,因为我们在处于状态时在转移之前选择动作,但在处于 Q-状态时在选择新动作之前转移。
有了这个新的更新规则,Q-学习的推导方式与 TD 学习基本相同,通过获取 Q-值样本 (Q-value samples):
\[\text{sample} = R(s, a, s') + \gamma \max_{a'}Q(s', a')\]并将它们合并到指数移动平均中。
\[Q(s, a) \leftarrow (1-\alpha)Q(s, a) + \alpha \cdot \text{sample}\]只要我们在探索中花费足够的时间并以适当的速度降低学习率 \(\alpha\),Q-学习就会学习每个 Q-状态的最优 Q-值。这就是 Q-学习如此具有革命性的原因——虽然 TD 学习和直接评估通过遵循策略来学习策略下状态的值,然后再通过其他技术确定策略最优性,但 Q-学习甚至可以通过采取次优或随机动作直接学习最优策略。这称为离策略学习 (off-policy learning)(与直接评估和 TD 学习相反,它们是在策略学习 (on-policy learning) 的例子)。
5.3.4 近似 Q-学习 (Approximate Q-Learning)
Q-学习是一种令人难以置信的学习技术,它继续处于强化学习领域发展的中心。然而,它仍有一些改进空间。目前,Q-学习只是以表格形式存储状态的所有 Q-值,考虑到强化学习的大多数应用都有数千甚至数百万个状态,这并不是特别有效。这意味着我们无法在训练期间访问所有状态,即使我们可以,也因为缺乏内存而无法存储所有 Q-值。



上面,如果吃豆人在运行普通 Q-学习后了解到图 1 是不利的,它仍然不知道图 2 甚至图 3 也是不利的。近似 Q-学习 (Approximate Q-learning) 试图通过学习一些一般情况并推断到许多类似情况来解决这个问题。概括学习经验的关键是状态的基于特征的表示 (feature-based representation),它将每个状态表示为一个称为特征向量 (feature vector) 的向量。例如,吃豆人的特征向量可能编码:
- 到最近幽灵的距离。
- 到最近食物颗粒的距离。
- 幽灵的数量。
- 吃豆人被困住了吗?0 或 1。
有了特征向量,我们可以将状态和 Q-状态的值视为线性值函数 (linear value functions):
\[V(s) = w_1 \cdot f_1(s) + w_2 \cdot f_2(s) + ... + w_n \cdot f_n(s) = \vec{w} \cdot \vec{f}(s)\] \[Q(s, a) = w_1 \cdot f_1(s, a) + w_2 \cdot f_2(s, a) + ... + w_n \cdot f_n(s, a) = \vec{w} \cdot \vec{f}(s, a)\]其中
\[\vec{f}(s) = \begin{bmatrix}f_1(s)&f_2(s)&...&f_n(s)\end{bmatrix}^T\]和
\[\vec{f}(s, a) = \begin{bmatrix}f_1(s, a)&f_2(s, a)&...&f_n(s, a)\end{bmatrix}^T\]分别表示状态 \(s\) 和 Q-状态 \((s, a)\) 的特征向量,\(\vec{w} = \begin{bmatrix}w_1&w_2&...&w_n\end{bmatrix}\) 表示权重向量。定义差异 (difference) 为
\[\text{difference} = [R(s, a, s') + \gamma \max_{a'}Q(s', a')] - Q(s, a)\]近似 Q-学习的工作原理与 Q-学习几乎相同,使用以下更新规则:
\[w_i \leftarrow w_i + \alpha \cdot \text{difference} \cdot f_i(s, a)\]与存储每个状态的 Q-值不同,使用近似 Q-学习,我们只需要存储一个权重向量,并且可以根据需要按需计算 Q-值。因此,这不仅为我们提供了 Q-学习的更通用版本,而且还是一个内存效率高得多的版本。
作为关于 Q-学习的最后一点说明,我们可以使用差异重新表达精确 Q-学习的更新规则如下:
\[Q(s, a) \leftarrow Q(s, a) + \alpha \cdot \text{difference}\]这第二种表示法为我们提供了对更新的稍微不同但同样有价值的解释:它计算采样估计与当前 \(Q(s, a)\) 模型之间的差异,并将模型向估计的方向移动,移动的幅度与差异的幅度成正比。