8.3 Algoritmo de Viterbi
En el Algoritmo Forward, usamos la recursividad para resolver \(P(X_N|e_{1:N})\), la distribución de probabilidad sobre los estados que el sistema podría habitar dadas las variables de evidencia observadas hasta ahora. Otra pregunta importante relacionada con los Modelos Ocultos de Markov es: ¿Cuál es la secuencia más probable de estados ocultos que siguió el sistema dadas las variables de evidencia observadas hasta ahora? En otras palabras, nos gustaría resolver para \(\arg\max_{x_{1:N}} P(x_{1:N}|e_{1:N}) = \arg\max_{x_{1:N}} P(x_{1:N},e_{1:N})\). Esta trayectoria también se puede resolver utilizando programación dinámica con el algoritmo de Viterbi.
El algoritmo consta de dos pasadas: la primera corre hacia adelante en el tiempo y calcula la probabilidad de la mejor ruta a cada tupla (estado, tiempo) dada la evidencia observada hasta ahora. La segunda pasada corre hacia atrás en el tiempo: primero encuentra el estado terminal que se encuentra en la ruta con la probabilidad más alta, y luego atraviesa hacia atrás a través del tiempo a lo largo de la ruta que conduce a este estado (que debe ser la mejor ruta).
Para visualizar el algoritmo, considere el siguiente enrejado de estados, un grafo de estados y transiciones a lo largo del tiempo:
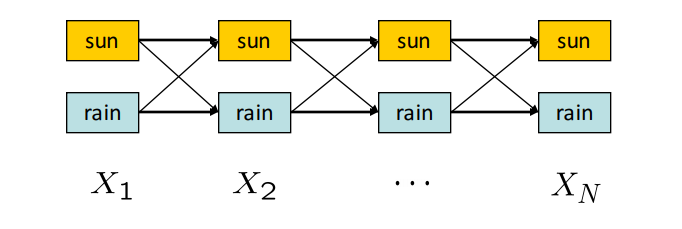
En este HMM con dos posibles estados ocultos, sol o lluvia, nos gustaría calcular la ruta de mayor probabilidad (asignación de un estado para cada paso de tiempo) de \(X_1\) a \(X_N\). Los pesos en un borde de \(X_{t-1}\) a \(X_t\) son iguales a \(P(X_t|X_{t-1})P(E_t|X_t)\), y la probabilidad de una ruta se calcula tomando el producto de sus pesos de borde. El primer término en la fórmula de peso representa qué tan probable es una transición particular y el segundo término representa qué tan bien se ajusta la evidencia observada al estado resultante.
Recuerde que: \(P(X_{1:N},e_{1:N}) = P(X_1)P(e_1|X_1)\prod_{t=2}^N P(X_t|X_{t-1})P(e_t|X_t)\) El Algoritmo Forward calcula (hasta la normalización) \(P(X_N,e_{1:N}) = \sum_{x_1,..,x_{N-1}} P(X_N, x_{1:N-1},e_{1:N})\) En el Algoritmo de Viterbi, queremos calcular \(\arg\max_{x_1,..,x_{N}}P(x_{1:N},e_{1:N})\)
para encontrar la estimación de máxima verosimilitud de la secuencia de estados ocultos. Observe que cada término en el producto es exactamente la expresión para el peso del borde entre la capa \(t-1\) y la capa \(t\). Entonces, el producto de los pesos a lo largo de la ruta en el enrejado nos da la probabilidad de la ruta dada la evidencia.
Podríamos resolver una tabla de probabilidad conjunta sobre todos los posibles estados ocultos, pero esto da como resultado un costo de espacio exponencial. Dada tal tabla, podríamos usar programación dinámica para calcular la mejor ruta en tiempo polinomial. Sin embargo, debido a que podemos usar programación dinámica para calcular la mejor ruta, no necesitamos necesariamente toda la tabla en un momento dado.
Defina \(m_t[x_t] = \max_{x_{1:t-1}} P(x_{1:t},e_{1:t})\), o la probabilidad máxima de una ruta que comienza en cualquier \(x_0\) y la evidencia vista hasta ahora a un \(x_t\) dado en el tiempo \(t\). Esto es lo mismo que la ruta de mayor peso a través del enrejado desde el paso \(1\) hasta \(t\). También tenga en cuenta que \begin{align} m_t[x_t] &= \max_{x_{1:t-1}} P(e_t|x_t)P(x_t|x_{t-1})P(x_{1:t-1},e_{1:t-1})
&= P(e_t|x_t)\max_{x_{t-1}} P(x_t|x_{t-1})\max_{x_{1:t-2}}P(x_{1:t-1},e_{1:t-1})
&= P(e_t|x_t)\max_{x_{t-1}} P(x_t|x_{t-1})m_{t-1}[x_{t-1}]. \end{align} Esto sugiere que podemos calcular \(m_t\) para todo \(t\) recursivamente a través de programación dinámica. Esto hace posible determinar el último estado \(x_N\) para la ruta más probable, pero aún necesitamos una forma de retroceder para reconstruir toda la ruta. Definamos \(a_t[x_t] = P(e_t|x_t)\arg\max_{x_{t-1}} P(x_t|x_{t-1})m_{t-1}[x_{t-1}] = \arg\max_{x_{t-1}} P(x_t|x_{t-1})m_{t-1}[x_{t-1}]\) para realizar un seguimiento de la última transición a lo largo de la mejor ruta a \(x_t\). Ahora podemos describir el algoritmo.
Resultado: Secuencia más probable de estados ocultos x1:N
/* Pase hacia adelante
para t=1 a N:
para xt en X:
si t=1:
mt[xt] = P(xt)P(e0|xt)
sino:
at[xt] = argmaxx{t-1} P(xt|xt-1)mt-1[xt-1];
mt[xt] = P(et|xt)P(xt|at[xt])mt-1[at[x_t]];
/* Encuentre el punto final de la ruta más probable
xN = argmaxxN mN[xN];
/* Trabaje hacia atrás a través de nuestra ruta más probable y encuentre los estados ocultos
Para t=N a 2:
xt-1 = at[xt];
Observe que nuestras matrices \(a\) definen un conjunto de \(N\) secuencias, cada una de las cuales es la secuencia más probable para un estado final particular \(x_N\). Una vez que terminamos el pase hacia adelante, miramos la probabilidad de las \(N\) secuencias, elegimos la mejor y la reconstruimos en el pase hacia atrás. Así hemos calculado la explicación más probable para nuestra evidencia en espacio y tiempo polinomiales.