4.2 解决马尔可夫决策过程 (Solving Markov Decision Processes)
回想一下,在确定性的、非对抗性的搜索中,解决搜索问题意味着找到一个到达目标状态的最优计划。另一方面,解决马尔可夫决策过程意味着找到一个最优策略 (policy) \(\pi^*: S \rightarrow A\),一个将每个状态 \(s \in S\) 映射到动作 \(a \in A\) 的函数。一个显式策略 \(\pi\) 定义了一个反射代理——给定一个状态 \(s\),在 \(s\) 处执行 \(\pi\) 的代理将选择 \(a = \pi(s)\) 作为要采取的适当动作,而不考虑其动作的未来后果。最优策略是指如果执行代理遵循该策略,将产生最大期望总奖励或效用的策略。
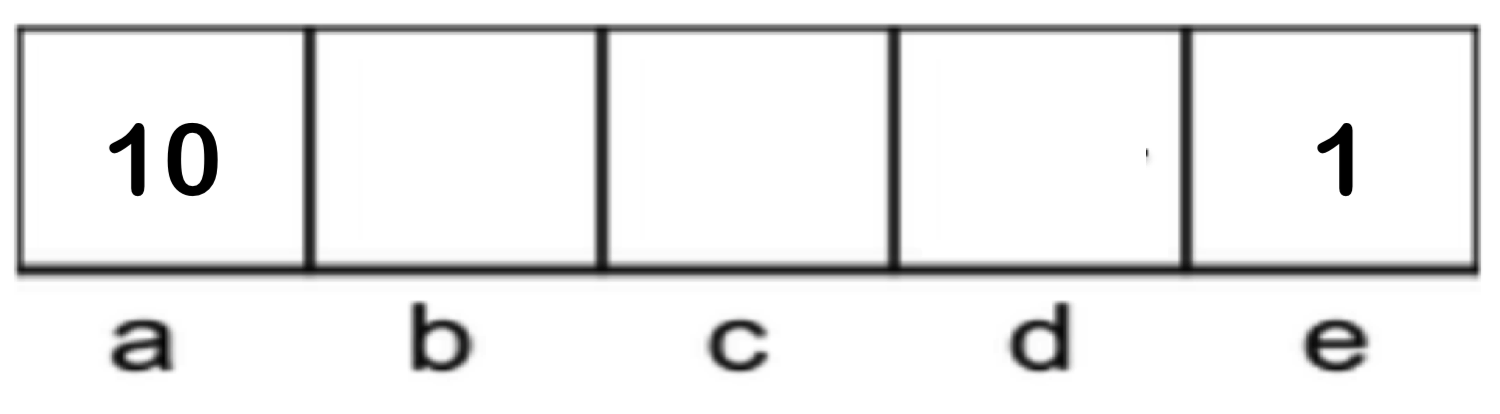
考虑以下 MDP,其中 \(S = \{a, b, c, d, e\}\),\(A = \{East, West, Exit\}\)(其中 \(Exit\) 仅在状态 \(a\) 和 \(e\) 中是有效动作,分别产生 10 和 1 的奖励),折扣因子 \(\gamma = 0.1\),且转移是确定性的:
此 MDP 的两个潜在策略如下:
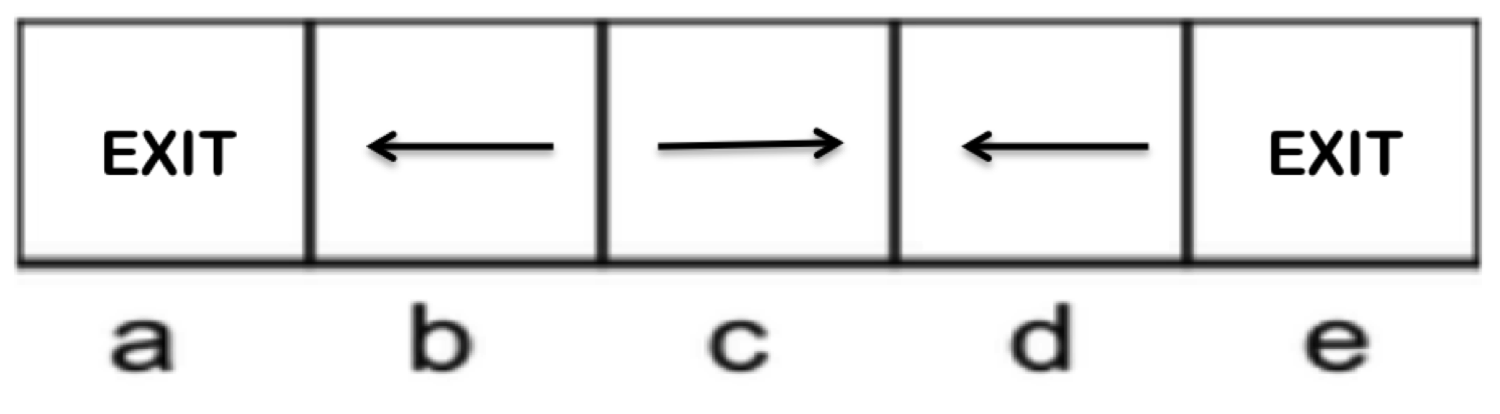 | 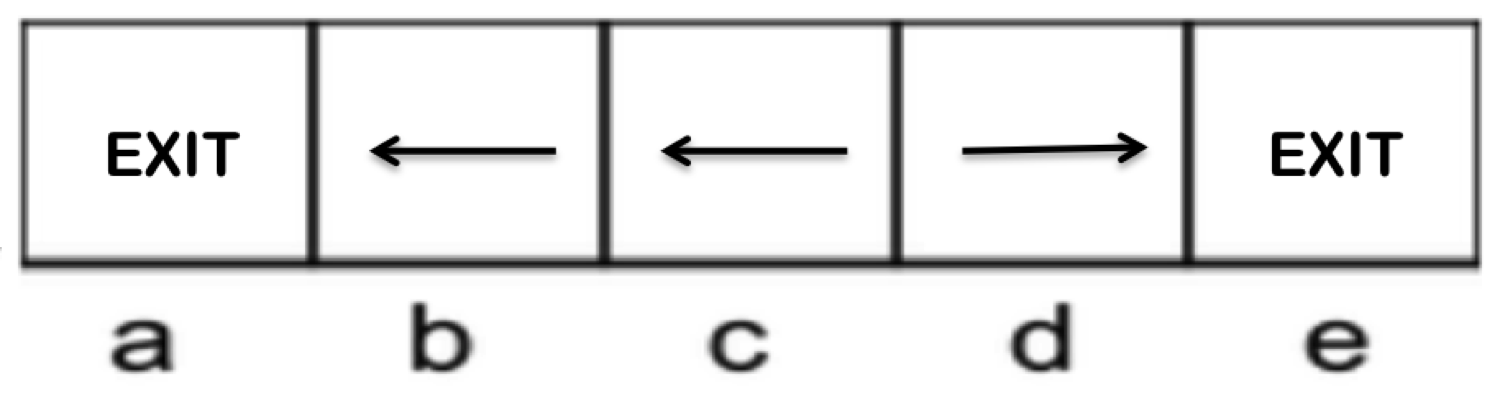 |
|---|---|
| Policy 1 | Policy 2 |
经过一番调查,不难确定策略 2 是最优的。遵循该策略直到采取动作 \(a = Exit\),每个起始状态产生的奖励如下:
| 起始状态 | 奖励 |
|---|---|
| a | 10 |
| b | 1 |
| c | 0.1 |
| d | 0.1 |
| e | 1 |
我们现在将学习如何使用马尔可夫决策过程的贝尔曼方程 (Bellman equation) 通过算法解决此类 MDP(以及更复杂的 MDP!)。
4.2.1 贝尔曼方程 (The Bellman Equation)
为了讨论 MDP 的贝尔曼方程,我们必须首先引入两个新的数学量:
- 状态 \(s\) 的最优值,\(V^*(s)\) — \(s\) 的最优值是从 \(s\) 开始的最优行为代理在其剩余寿命内将获得的效用的期望值。注意,在文献中经常用 \(V^*(s)\) 表示相同的量。
- Q-状态 \((s, a)\) 的最优值,\(Q^*(s, a)\) — \((s, a)\) 的最优值是代理在从 \(s\) 开始,采取 \(a\),并此后表现最优后获得的效用的期望值。
使用这两个新量和前面讨论的其他 MDP 量,贝尔曼方程定义如下:
\[V^*(s) = \max_a \sum_{s'}T(s, a, s')[R(s, a, s') + \gamma V^*(s')]\]在我们开始解释这意味着什么之前,让我们也定义 Q-状态的最优值(通常称为最优 Q-值 (Q-value))的方程:
\[Q^*(s, a) = \sum_{s'}T(s, a, s')[R(s, a, s') + \gamma V^*(s')]\]注意,这第二个定义允许我们将贝尔曼方程重新表达为
\[V^*(s) = \max_a Q^*(s, a)\]这是一个极其简单的量。贝尔曼方程是动态规划方程 (dynamic programming equation) 的一个例子,这种方程通过固有的递归结构将问题分解为更小的子问题。我们可以在状态的 Q-值方程中看到这种固有的递归,即 \([R(s, a, s') + \gamma V^*(s')]\) 项。该项表示代理通过首先从 \(s\) 采取 \(a\) 并到达 \(s'\),然后此后表现最优所获得的总效用。采取动作 \(a\) 的即时奖励 \(R(s, a, s')\) 加上从 \(s'\) 可获得的最佳折扣奖励总和 \(V^*(s')\),该总和按 \(\gamma\) 折扣以考虑采取动作 \(a\) 所经过的一个时间步。虽然在大多数情况下,从 \(s'\) 到某个终止状态存在大量可能的状态和动作序列,但所有这些细节都被抽象出来并封装在一个单一的递归值 \(V^*(s')\) 中。
我们现在可以向外迈出一步,考虑 Q-值的完整方程。知道 \([R(s, a, s') + \gamma V^*(s')]\) 表示从 Q-状态 \((s, a)\) 到达状态 \(s'\) 后表现最优所获得的效用,很明显,量
\[\sum_{s'}T(s, a, s')[R(s, a, s') + \gamma V^*(s')]\]只是效用的加权和,每个效用按其发生概率加权。根据定义,这就是从 Q-状态 \((s, a)\) 开始表现最优的期望效用!这完成了我们的分析,并给了我们足够的洞察力来解释完整的贝尔曼方程——状态的最优值 \(V^*(s)\) 只是从 \(s\) 出发的所有可能动作的最大期望效用。计算状态 \(s\) 的最大期望效用本质上与运行 expectimax 相同——我们首先计算每个 Q-状态 \((s, a)\) 的期望效用(相当于计算机会节点的值),然后计算这些节点的最大值以计算最大期望效用(相当于计算最大化节点的值)。
关于贝尔曼方程的最后一点说明——它的用途是作为最优性的条件。换句话说,如果我们能以某种方式为每个状态 \(s \in S\) 确定一个值 \(V(s)\),使得贝尔曼方程对每个状态都成立,我们就可以得出结论,这些值是其各自状态的最优值。实际上,满足此条件意味着 \(\forall s \in S, \: V(s) = V^*(s)\)。