1.3 Búsqueda no informada
El protocolo estándar para encontrar un plan para ir del estado inicial a un estado objetivo es mantener una frontera externa de planes parciales derivados del árbol de búsqueda. Continuamente expandimos nuestra frontera eliminando un nodo (que se selecciona usando nuestra estrategia dada) correspondiente a un plan parcial de la frontera, y reemplazándolo en la frontera con todos sus hijos. Eliminar y reemplazar un elemento en la frontera con sus hijos corresponde a descartar un plan de longitud n y considerar todos los planes de longitud \((n+1)\) que se derivan de él. Continuamos esto hasta que finalmente eliminamos un estado objetivo de la frontera, momento en el cual concluimos que el plan parcial correspondiente al estado objetivo eliminado es de hecho un camino para ir del estado inicial al estado objetivo.
En la práctica, la mayoría de las implementaciones de tales algoritmos codificarán información sobre el nodo padre, la distancia al nodo y el estado dentro del objeto nodo. Este procedimiento que acabamos de describir se conoce como búsqueda en árbol, y su pseudocódigo se presenta a continuación:
function TREE-SEARCH(problem, frontier) return a solution or failure
frontier ← INSERT(MAKE-NODE(INITIAL-STATE[problem]), frontier)
while not IS-EMPTY(frontier) do
node ← POP(frontier)
if problem.IS-GOAL(node.STATE) then return node
for each child-node in EXPAND(problem, node) do
add child-node to frontier
return failure
La función EXPAND que aparece en el pseudocódigo devuelve todos los nodos posibles que se pueden alcanzar desde un nodo dado considerando todas las acciones disponibles. El pseudocódigo de la función es el siguiente:
function EXPAND(problem, node) yields nodes
s ← node.STATE
for each action in problem.ACTIONS(s) do
s' ← problem.RESULT(s, action)
yield NODE(STATE=s', PARENT=node, ACTION=action)
Cuando no tenemos conocimiento de la ubicación de los estados objetivo en nuestro árbol de búsqueda, nos vemos obligados a seleccionar nuestra estrategia para la búsqueda en árbol de una de las técnicas que caen bajo el paraguas de la búsqueda no informada. Ahora cubriremos tres de estas estrategias sucesivamente: búsqueda en profundidad, búsqueda en anchura y búsqueda de costo uniforme. Junto con cada estrategia, también se presentan algunas propiedades rudimentarias de la estrategia, en términos de lo siguiente:
- La completitud de cada estrategia de búsqueda: si existe una solución al problema de búsqueda, ¿está garantizada la estrategia para encontrarla dados recursos computacionales infinitos?
- La optimalidad de cada estrategia de búsqueda: ¿está garantizada la estrategia para encontrar el camino de menor costo a un estado objetivo?
- El factor de ramificación \(b\): El aumento en el número de nodos en la frontera cada vez que un nodo de la frontera se saca de la cola y se reemplaza con sus hijos es \(O(b)\). En la profundidad k en el árbol de búsqueda, existen \(O(b^{k})\) nodos.
- La profundidad máxima m.
- La profundidad de la solución más superficial s.
1.3.1 Búsqueda en profundidad (Depth-First Search)
- Descripción - La búsqueda en profundidad (DFS) es una estrategia de exploración que siempre selecciona el nodo de frontera más profundo desde el nodo inicial para la expansión.
- Representación de la frontera - Eliminar el nodo más profundo y reemplazarlo en la frontera con sus hijos significa necesariamente que los hijos son ahora los nuevos nodos más profundos: su profundidad es uno mayor que la profundidad del nodo más profundo anterior. Esto implica que para implementar DFS, requerimos una estructura que siempre dé la máxima prioridad a los objetos agregados más recientemente. Una pila de último en entrar, primero en salir (LIFO) hace exactamente esto, y es lo que se usa tradicionalmente para representar la frontera al implementar DFS.
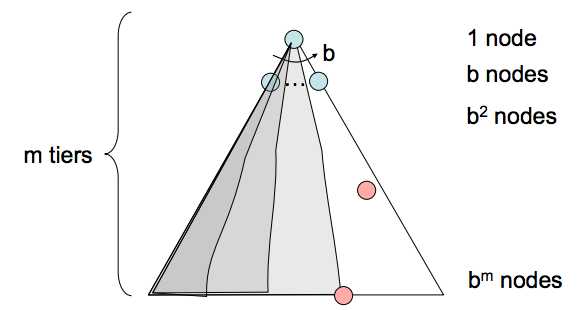
- Completitud - La búsqueda en profundidad no es completa. Si existen ciclos en el grafo del espacio de estados, esto significa inevitablemente que el árbol de búsqueda correspondiente será infinito en profundidad. Por lo tanto, existe la posibilidad de que DFS se quede “atascado” fiel pero trágicamente buscando el nodo más profundo en un árbol de búsqueda de tamaño infinito, condenado a nunca encontrar una solución.
- Optimalidad - La búsqueda en profundidad simplemente encuentra la solución “más a la izquierda” en el árbol de búsqueda sin tener en cuenta los costos del camino, por lo que no es óptima.
- Complejidad temporal - En el peor de los casos, la búsqueda en profundidad puede terminar explorando todo el árbol de búsqueda. Por lo tanto, dado un árbol con profundidad máxima \(m\), el tiempo de ejecución de DFS es \(O(b^{m})\).
- Complejidad espacial - En el peor de los casos, DFS mantiene b nodos en cada uno de los \(m\) niveles de profundidad en la frontera. Esta es una consecuencia simple del hecho de que una vez que se ponen en cola \(b\) hijos de algún padre, la naturaleza de DFS permite que solo uno de los subárboles de cualquiera de estos hijos sea explorado en un momento dado. Por lo tanto, la complejidad espacial de DFS es \(O(bm)\).
1.3.2 Búsqueda en anchura (Breadth-First Search)
- Descripción - La búsqueda en anchura es una estrategia de exploración que siempre selecciona el nodo de frontera más superficial desde el nodo inicial para la expansión.
- Representación de la frontera - Si queremos visitar nodos más superficiales antes que nodos más profundos, debemos visitar los nodos en su orden de inserción. Por lo tanto, deseamos una estructura que genere el objeto en cola más antiguo para representar nuestra frontera. Para esto, BFS utiliza una cola de primero en entrar, primero en salir (FIFO), que hace exactamente esto.
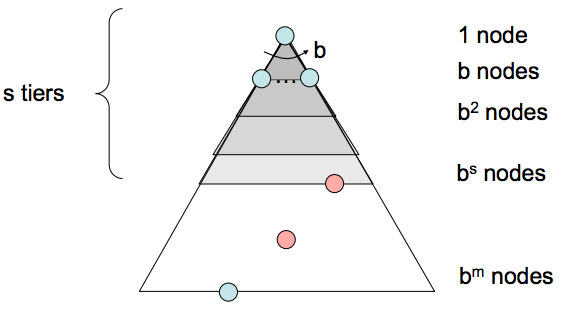
- Completitud - Si existe una solución, entonces la profundidad del nodo más superficial \(s\) debe ser finita, por lo que BFS debe buscar eventualmente esta profundidad. Por lo tanto, es completa.
- Optimalidad - BFS generalmente no es óptima porque simplemente no tiene en cuenta los costos al determinar qué nodo reemplazar en la frontera. El caso especial donde se garantiza que BFS es óptima es si todos los costos de los bordes son equivalentes, porque esto reduce BFS a un caso especial de búsqueda de costo uniforme, que se analiza a continuación.
- Complejidad temporal - Debemos buscar \(1 + b + b^{2} + ... + b^{s}\) nodos en el peor de los casos, ya que pasamos por todos los nodos en cada profundidad de 1 a \(s\). Por lo tanto, la complejidad temporal es \(O(b^s)\).
- Complejidad espacial - La frontera, en el peor de los casos, contiene todos los nodos en el nivel correspondiente a la solución más superficial. Dado que la solución más superficial se encuentra en la profundidad \(s\), hay \(O(b^{s})\) nodos en esta profundidad.
1.3.3 Búsqueda de costo uniforme (Uniform Cost Search)
- Descripción - La búsqueda de costo uniforme (UCS), nuestra última estrategia, es una estrategia de exploración que siempre selecciona el nodo de frontera de menor costo desde el nodo inicial para la expansión.
- Representación de la frontera - Para representar la frontera para UCS, la elección suele ser una cola de prioridad basada en montículos, donde la prioridad para un nodo en cola dado \(v\) es el costo del camino desde el nodo inicial hasta \(v\), o el costo hacia atrás de \(v\). Intuitivamente, una cola de prioridad construida de esta manera simplemente se reorganiza para mantener el orden deseado por costo de camino a medida que eliminamos el camino de costo mínimo actual y lo reemplazamos con sus hijos.
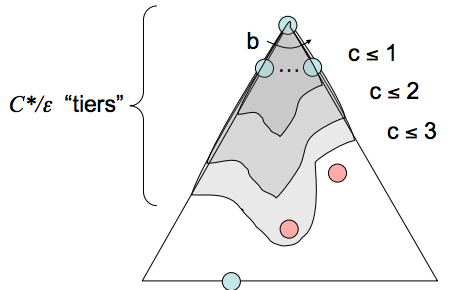
- Completitud - La búsqueda de costo uniforme es completa. Si existe un estado objetivo, debe tener algún camino más corto de longitud finita; por lo tanto, UCS debe encontrar eventualmente este camino de longitud más corta.
- Optimalidad - UCS también es óptima si asumimos que todos los costos de los bordes son no negativos. Por construcción, dado que exploramos nodos en orden de costo de camino creciente, estamos garantizados de encontrar el camino de menor costo a un estado objetivo. La estrategia empleada en la Búsqueda de Costo Uniforme es idéntica a la del algoritmo de Dijkstra, y la principal diferencia es que UCS termina al encontrar un estado de solución en lugar de encontrar el camino más corto a todos los estados. Tenga en cuenta que tener costos de borde negativos en nuestro grafo puede hacer que los nodos en un camino tengan una longitud decreciente, arruinando nuestra garantía de optimalidad. (Ver algoritmo de Bellman-Ford para un algoritmo más lento que maneja esta posibilidad)
- Complejidad temporal - Definamos el costo del camino óptimo como \(C*\) y el costo mínimo entre dos nodos en el grafo del espacio de estados como \(\varepsilon\). Entonces, debemos explorar aproximadamente todos los nodos en profundidades que van desde 1 hasta \(\frac{C*}{\varepsilon}\), lo que lleva a un tiempo de ejecución de \(O(b^{\frac{C*}{\varepsilon}})\).
- Complejidad espacial - Aproximadamente, la frontera contendrá todos los nodos en el nivel de la solución más barata, por lo que la complejidad espacial de UCS se estima como \(O(b^{\frac{C*}{\varepsilon}})\).
Como nota final sobre la búsqueda no informada, es fundamental tener en cuenta que las tres estrategias descritas anteriormente son fundamentalmente las mismas, difiriendo solo en la estrategia de expansión, y sus similitudes se capturan mediante el pseudocódigo de búsqueda en árbol presentado anteriormente.