4.1 Procesos de Decisión de Markov
Un Proceso de Decisión de Markov se define por varias propiedades:
- Un conjunto de estados \(S\). Los estados en los MDP se representan de la misma manera que los estados en los problemas de búsqueda tradicionales.
- Un conjunto de acciones \(A\). Las acciones en los MDP también se representan de la misma manera que en los problemas de búsqueda tradicionales.
- Un estado inicial.
- Posiblemente uno o más estados terminales.
- Posiblemente un factor de descuento \(\gamma\). Cubriremos los factores de descuento en breve.
- Una función de transición \(T(s, a, s')\). Dado que hemos introducido la posibilidad de acciones no deterministas, necesitamos una forma de delinear la probabilidad de los posibles resultados después de tomar una acción dada desde cualquier estado dado. La función de transición para un MDP hace exactamente esto: es una función de probabilidad que representa la probabilidad de que un agente que toma una acción \(a \in A\) desde un estado \(s \in S\) termine en un estado \(s' \in S\).
- Una función de recompensa \(R(s, a, s')\). Por lo general, los MDP se modelan con pequeñas recompensas de “vida” en cada paso para recompensar la supervivencia de un agente, junto con grandes recompensas por llegar a un estado terminal. Las recompensas pueden ser positivas o negativas dependiendo de si benefician o no al agente en cuestión, y el objetivo del agente es naturalmente adquirir la máxima recompensa posible antes de llegar a algún estado terminal.
Construir un MDP para una situación es bastante similar a construir un grafo de espacio de estados para un problema de búsqueda, con un par de advertencias adicionales. Considere el ejemplo motivador de un auto de carreras:
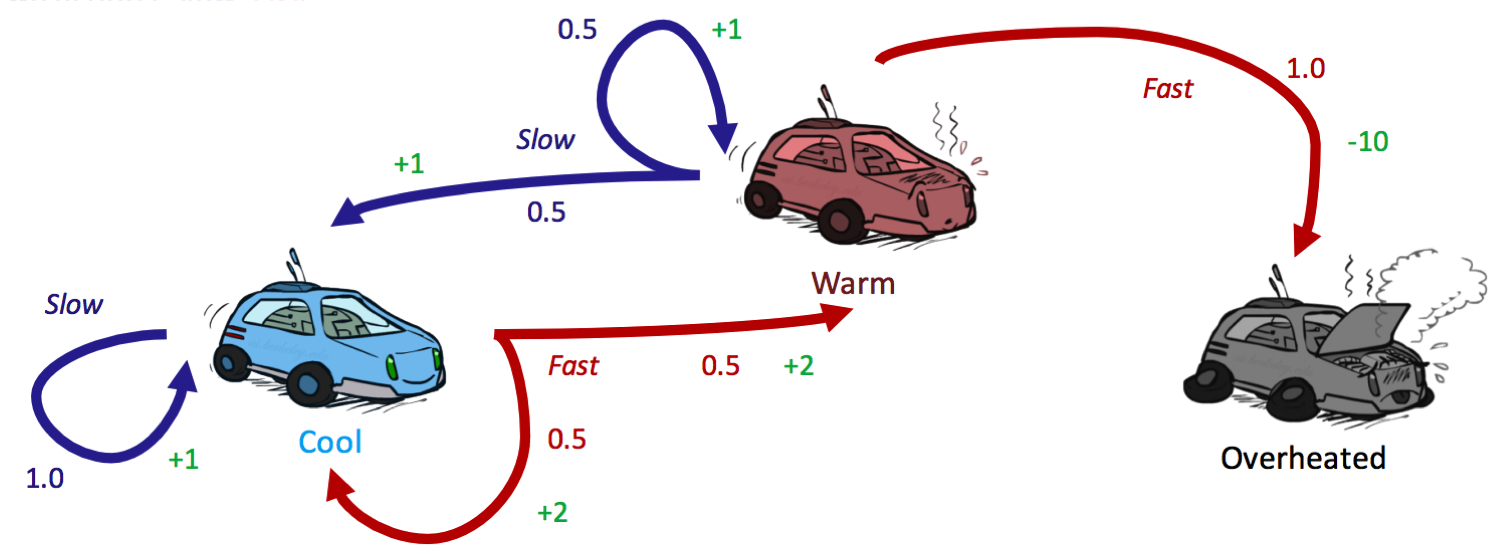
Hay tres estados posibles, \(S = \{frío, tibio, sobrecalentado\}\), y dos acciones posibles \(A = \{lento, rápido\}\). Al igual que en un grafo de espacio de estados, cada uno de los tres estados está representado por un nodo, con bordes que representan acciones. Sobrecalentado es un estado terminal, ya que una vez que un agente de auto de carreras llega a este estado, ya no puede realizar ninguna acción para obtener más recompensas (es un estado sumidero en el MDP y no tiene bordes salientes). En particular, para acciones no deterministas, hay múltiples bordes que representan la misma acción desde el mismo estado con diferentes estados sucesores. Cada borde está anotado no solo con la acción que representa, sino también con una probabilidad de transición y la recompensa correspondiente. Estos se resumen a continuación:
Función de Transición: \(T(s, a, s')\)
- \[T(frío, lento, frío) = 1\]
- \[T(tibio, lento, frío) = 0.5\]
- \[T(tibio, lento, tibio) = 0.5\]
- \[T(frío, rápido, frío) = 0.5\]
- \[T(frío, rápido, tibio) = 0.5\]
- \[T(tibio, rápido, sobrecalentado) = 1\]
Función de Recompensa: \(R(s, a, s')\)
- \[R(frío, lento, frío) = 1\]
- \[R(tibio, lento, frío) = 1\]
- \[R(tibio, lento, tibio) = 1\]
- \[R(frío, rápido, frío) = 2\]
- \[R(frío, rápido, tibio) = 2\]
- \[R(tibio, rápido, sobrecalentado) = -10\]
Representamos el movimiento de un agente a través de diferentes estados MDP a lo largo del tiempo con pasos de tiempo discretos, definiendo \(s_t \in S\) y \(a_t \in A\) como el estado en el que existe un agente y la acción que toma un agente en el paso de tiempo \(t\) respectivamente. Un agente comienza en el estado \(s_0\) en el paso de tiempo 0 y toma una acción en cada paso de tiempo. El movimiento de un agente a través de un MDP se puede modelar de la siguiente manera:
\[s_0 \xrightarrow{a_0} s_1 \xrightarrow{a_1} s_2 \xrightarrow{a_2} s_3 \xrightarrow{a_3}...\]Además, sabiendo que el objetivo de un agente es maximizar su recompensa en todos los pasos de tiempo, podemos expresar esto matemáticamente como una maximización de la siguiente función de utilidad:
\[U([s_0, a_0, s_1, a_1, s_2, ...]) = R(s_0, a_0, s_1) + R(s_1, a_1, s_2) + R(s_2, a_2, s_3) + ...\]Los procesos de decisión de Markov, como los grafos de espacio de estados, se pueden desenredar en árboles de búsqueda. La incertidumbre se modela en estos árboles de búsqueda con estados Q, también conocidos como estados de acción, esencialmente idénticos a los nodos de azar expectimax. Esta es una elección adecuada, ya que los estados Q usan probabilidades para modelar la incertidumbre de que el entorno aterrizará a un agente en un estado dado, al igual que los nodos de azar expectimax usan probabilidades para modelar la incertidumbre de que los agentes adversarios aterrizarán a nuestro agente en un estado dado a través del movimiento que seleccionan estos agentes. El estado Q representado por haber tomado la acción \(a\) desde el estado \(s\) se anota como la tupla \((s, a)\).
Observe el árbol de búsqueda desenredado para nuestro auto de carreras, truncado a profundidad 2:
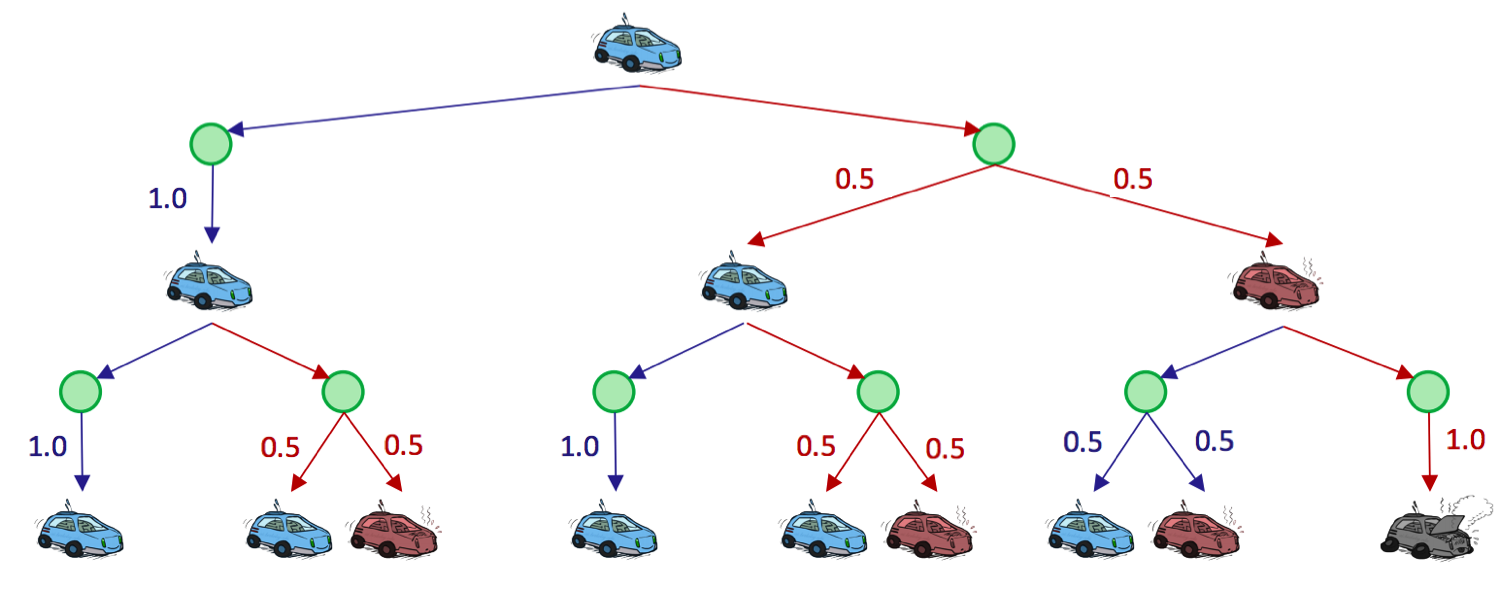
Los nodos verdes representan estados Q, donde se ha tomado una acción desde un estado pero aún no se ha resuelto en un estado sucesor. Es importante comprender que los agentes pasan cero pasos de tiempo en estados Q, y que son simplemente una construcción creada para facilitar la representación y el desarrollo de algoritmos MDP.
4.1.1 Horizontes finitos y descuento
Hay un problema inherente con nuestro MDP de auto de carreras: no hemos impuesto ninguna restricción de tiempo en el número de pasos de tiempo durante los cuales un auto de carreras puede tomar acciones y recolectar recompensas. Con nuestra formulación actual, podría elegir rutinariamente \(a = lento\) en cada paso de tiempo para siempre, obteniendo de manera segura y efectiva una recompensa infinita sin ningún riesgo de sobrecalentamiento. Esto se evita mediante la introducción de horizontes finitos y/o factores de descuento. Un MDP que impone un horizonte finito es simple: esencialmente define una “vida útil” para los agentes, lo que les da un número determinado de pasos de tiempo \(n\) para acumular tanta recompensa como puedan antes de ser terminados automáticamente. Volveremos a este concepto en breve.
Los factores de descuento son un poco más complicados y se introducen para modelar una disminución exponencial en el valor de las recompensas a lo largo del tiempo. Concretamente, con un factor de descuento de \(\gamma\), tomar la acción \(a_t\) desde el estado \(s_t\) en el paso de tiempo \(t\) y terminar en el estado \(s_{t+1}\) da como resultado una recompensa de \(\gamma^t R(s_t, a_t, s_{t+1})\) en lugar de solo \(R(s_t, a_t, s_{t+1})\). Ahora, en lugar de maximizar la utilidad aditiva
\[U([s_0, a_0, s_1, a_1, s_2, ...]) = R(s_0, a_0, s_1) + R(s_1, a_1, s_2) + R(s_2, a_2, s_3) + ...\]intentamos maximizar la utilidad descontada
\[U([s_0, a_0, s_1, a_1, s_2, ...]) = R(s_0, a_0, s_1) + \gamma R(s_1, a_1, s_2) + \gamma^2 R(s_2, a_2, s_3) + ...\]| Observando que la definición anterior de una función de utilidad descontada se parece a una serie geométrica con razón \(\gamma\), podemos probar que se garantiza que tendrá un valor finito siempre que se cumpla la restricción $$ | \gamma | < 1\((donde\) | n | $$ denota el operador de valor absoluto) a través de la siguiente lógica: |
donde \(R_{max}\) es la recompensa máxima posible alcanzable en cualquier paso de tiempo dado en el MDP. Por lo general, \(\gamma\) se selecciona estrictamente del rango \(0 < \gamma < 1\) ya que los valores en el rango \(-1 < \gamma \leq 0\) simplemente no son significativos en la mayoría de las situaciones del mundo real: un valor negativo para \(\gamma\) significa que la recompensa para un estado \(s\) alternaría entre valores positivos y negativos en pasos de tiempo alternos.
4.1.2 Propiedad de Markov
Los procesos de decisión de Markov son “markovianos” en el sentido de que satisfacen la propiedad de Markov, o propiedad sin memoria, que establece que el futuro y el pasado son condicionalmente independientes, dado el presente. Intuitivamente, esto significa que, si conocemos el estado actual, conocer el pasado no nos da más información sobre el futuro. Para expresar esto matemáticamente, considere un agente que ha visitado los estados \(s_0, s_1, ..., s_t\) después de tomar las acciones \(a_0, a_1, ..., a_{t-1}\) en algún MDP, y acaba de tomar la acción \(a_t\). La probabilidad de que este agente llegue al estado \(s_{t+1}\) dado su historial de estados visitados y acciones tomadas anteriormente se puede escribir de la siguiente manera: \(P(S_{t+1} = s_{t+1} \mid S_t = s_t, A_t = a_t, S_{t-1} = s_{t-1}, A_{t-1} = a_{t-1}, ..., S_0 = s_0)\)
donde cada \(S_t\) denota la variable aleatoria que representa el estado de nuestro agente y \(A_t\) denota la variable aleatoria que representa la acción que toma nuestro agente en el tiempo \(t\). La propiedad de Markov establece que la probabilidad anterior se puede simplificar de la siguiente manera: \(P(S_{t+1} = s_{t+1} \mid S_t = s_t, A_t = a_t, S_{t-1} = s_{t-1}, A_{t-1} = a_{t-1}, ..., S_0 = s_0) = P(S_{t+1} = s_{t+1} \mid S_t = s_t, A_t = a_t)\)
que es “sin memoria” en el sentido de que la probabilidad de llegar a un estado \(s'\) en el tiempo \(t+1\) depende solo del estado \(s\) y la acción \(a\) tomada en el tiempo \(t\), no de ningún estado o acción anterior. De hecho, son estas probabilidades sin memoria las que están codificadas por la función de transición: \(\boxed{T(s, a, s') = P(s' \mid s, a)}\).