9.9 神经网络:动机 (Neural Networks: Motivation)
在接下来的内容中,我们将介绍神经网络的概念。在此过程中,我们将使用我们为二元逻辑回归和多类逻辑回归开发的一些建模技术。
9.9.1 非线性分离器 (Non-linear Separators)
我们知道如何构建一个模型来学习二元分类任务的线性边界。这是一种强大的技术,当底层的最优决策边界本身是线性的时候,这种技术效果很好。然而,许多实际问题涉及本质上是非线性的决策边界,而我们的线性感知器模型不够强大,无法捕捉这种关系。
考虑以下数据集:

我们想要分离这两种颜色,显然无法在单一维度上做到这一点(一维决策边界将是一个点,将轴分为两个区域)。 为了解决这个问题,我们可以添加额外的(可能是非线性的)特征来构建决策边界。考虑添加了 \(x^2\) 作为特征的相同数据集:
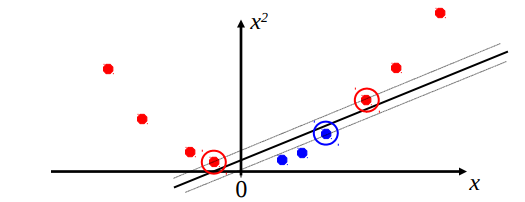
有了这个额外的信息,我们现在能够在包含这些点的二维空间中构建一个线性分离器。在这个例子中,我们通过手动向数据点添加有用的特征,将数据映射到更高维的空间,从而解决了这个问题。然而,在许多高维问题中,例如图像分类,手动选择有用的特征是乏味的。这需要特定领域的专业知识,并且不利于跨任务的泛化目标。一个自然的愿望是也学习这些特征变换,使用能够表示更广泛函数种类的非线性函数类。
9.9.2 多层感知器 (Multi-layer Perceptron)
让我们看看如何从我们原始的感知器架构中推导出一个更复杂的函数。考虑以下设置,一个两层感知器,它是一个将另一个感知器的输出作为输入的感知器。
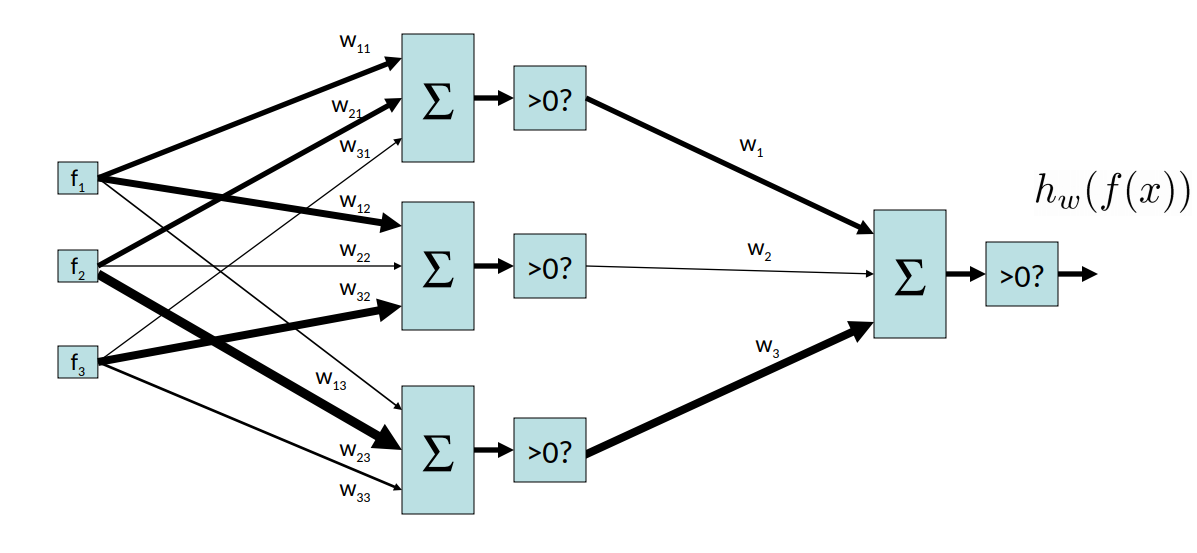
事实上,我们可以将其推广到 N 层感知器:
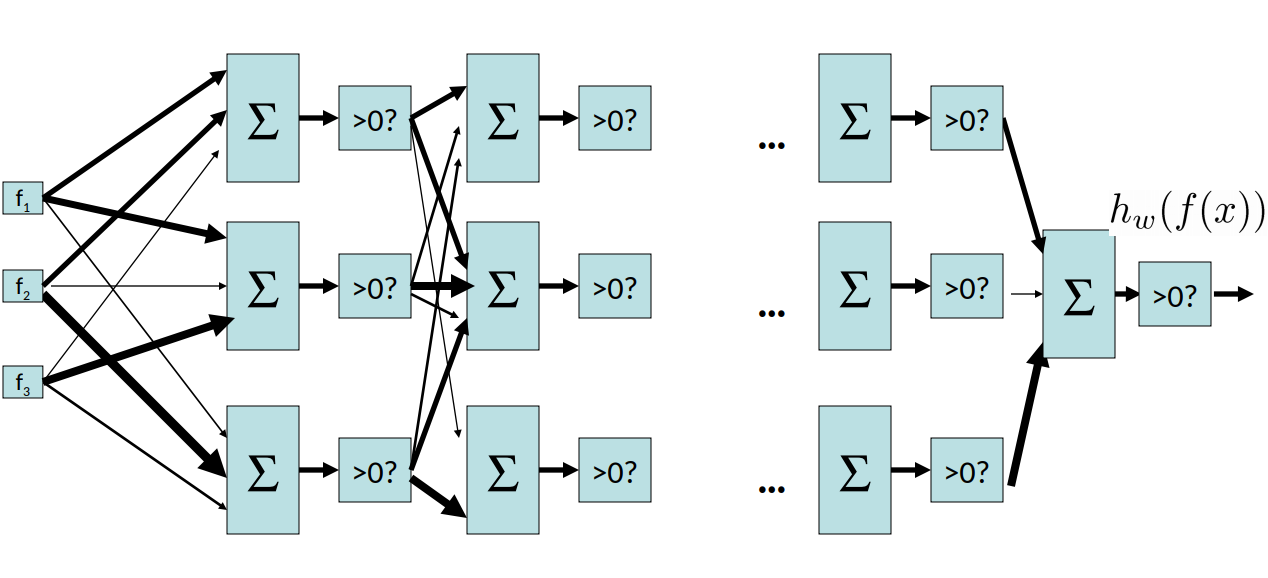
有了这种额外的结构和权重,我们可以表达更广泛的函数集。
通过增加模型的复杂性,我们大大增加了它的表达能力。多层感知器为我们提供了一种通用的方法来表示更广泛的函数集。事实上,多层感知器是一个通用函数逼近器 (universal function approximator),可以表示_任何_实函数,留给我们的唯一问题是选择最佳的权重集来参数化我们的网络。这在下面被正式陈述:
9.9.2.1 定理 (通用函数逼近器)
具有足够数量神经元的两层神经网络可以将任何连续函数逼近到任何所需的精度。
9.9.3 衡量准确性 (Measuring Accuracy)
二元感知器在进行 \(n\) 次预测后的准确性可以表示为:
\[l^{acc}(\mathbf{w}) = \frac{1}{n}\sum_{i=1}^n(\textrm{sgn}(\mathbf{w} \cdot \mathbf{f}(\mathbf{x}_{i}))== y_{i})\]其中 \(\mathbf{x}_{i}\) 是数据点 \(i\),\(\mathbf{w}\) 是我们的权重向量,\(\mathbf{f}\) 是我们从原始数据点导出特征向量的函数,\(y_{i}\) 是 \(\mathbf{x}_{i}\) 的实际类标签。在这个上下文中,\(\textrm{sgn}(x)\) 代表一个指示函数 (indicator function),当 \(x\) 为负时计算结果为 \(-1\),当 \(x\) 为正时计算结果为 \(1\)。我们的准确性函数等同于将_正确_预测的总数除以预测的总数。
有时,我们想要一个比二元标签更具表现力的输出。这时,为 ( N ) 个类别中的每一个生成一个概率变得很有用,反映了我们对数据点属于每个类别的确定程度。就像在多类逻辑回归中一样,我们为每个类别 ( j ) 存储一个权重向量,并使用 softmax 函数估计概率:
\[\sigma (\mathbf{x}_{i})_j = \frac{e^{\mathbf{f}(\mathbf{x}_{i})^T \mathbf{w}_j}}{\sum_{\ell=1}^Ne^{\mathbf{f}(\mathbf{x}_{i})^T \mathbf{w}_\ell}} = P(y_{i} = j | \mathbf{f}(\mathbf{x}_{i});\mathbf{w}).\]给定 \(\mathbf{f}\) 输出的一个向量,softmax 将其归一化以输出一个概率分布。为了推导出我们模型的通用损失函数,我们可以使用这个概率分布来生成一组权重的似然表达式:
\[\ell(\mathbf{w}) = \prod_{i=1}^nP(y_{i} | \mathbf{f}(\mathbf{x}_{i}); \mathbf{w}).\]这个表达式表示一组特定权重解释观察到的标签和数据点的可能性。我们寻求最大化这个数量的权重集。这等同于找到对数似然表达式的最大值:
\[\log\ell(\mathbf{w}) = \log \prod_{i=1}^n P(y_{i} | x_{i}; \mathbf{w}) = \sum_{i=1}^n \log P(y_{i} | \mathbf{f}(\mathbf{x}_{i}); \mathbf{w}).\]9.9.4 多层前馈神经网络 (Multi-layer Feedforward Neural Networks)
我们现在介绍人工神经网络的概念。像多层感知器一样,我们选择在每个感知器节点之后应用一个非线性。这些添加的非线性使整个网络成为非线性的,并且更具表现力。如果没有它们,多层感知器将仅仅是线性函数的组合,因此仍然是线性的。
在多层感知器的情况下,我们选择了一个阶跃函数:
\[f(x) = \begin{cases} 1 & \text{if } x \ge 0 \\ -1 & \text{otherwise} \end{cases}\]从图形上看,它是这样的:
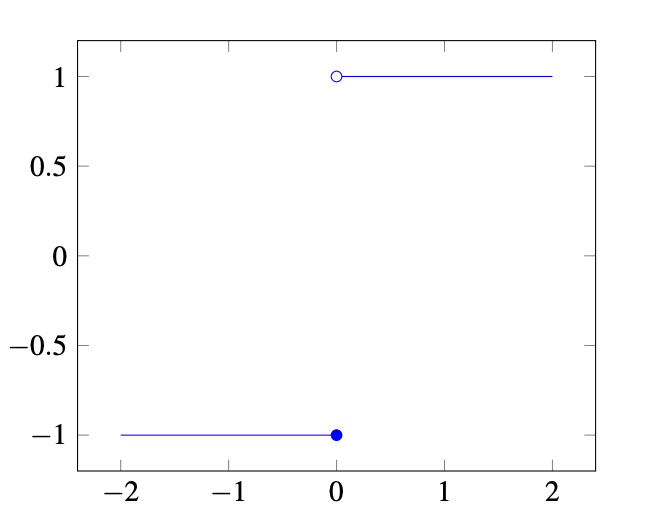
这很难优化,因为它不是连续的,并且在所有点的导数都为零。与其使用阶跃函数,更好的解决方案是选择一个连续函数,例如 Sigmoid 函数 或 线性整流单元 (ReLU)。
9.9.4.1 Sigmoid 函数:
\[\sigma(x) = \frac{1}{1 + e^{-x}}\]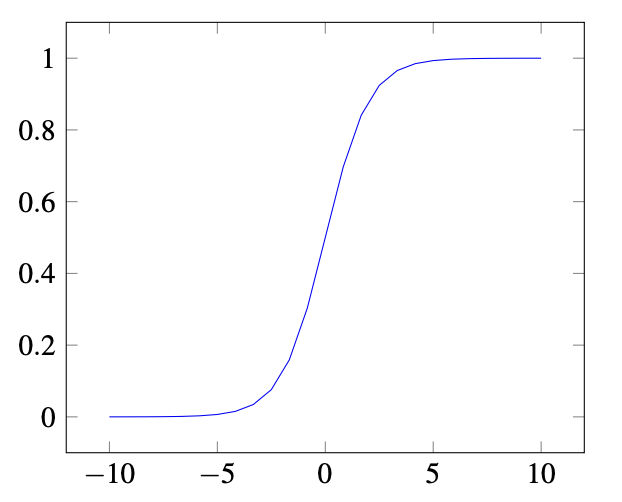
9.9.4.2 ReLU:
\[f(x) = \begin{cases} 0 & \text{if } x < 0 \\ x & \text{if } x \ge 0 \end{cases}\]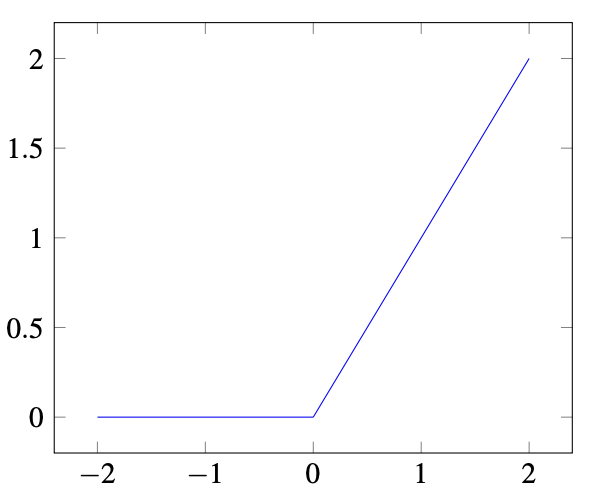
在多层感知器中,我们在每一层的输出处应用这些非线性之一。非线性的选择是一个通常需要实验的设计决策。
9.9.5 损失函数和多变量优化 (Loss Functions and Multivariate Optimization)
现在我们了解了前馈神经网络是如何构建的,我们需要一种方法来训练它。回到我们的对数似然函数,我们可以推导出一个直观的算法来优化我们的权重。
为了最大化我们的对数似然函数,我们对其进行微分以获得一个梯度向量 (gradient vector):
\[\nabla_w \ell (\mathbf{w}) = \left[\frac{\partial \ell(\mathbf{w})}{\partial \mathbf{w}_1}, ..., \frac{\partial \ell(\mathbf{w})}{\partial \mathbf{w}_n}\right].\]我们使用梯度上升方法找到参数的最佳值。鉴于数据集通常很大,批量梯度上升是神经网络优化中梯度上升的最流行变体。