9.4 二元感知器 (Binary Perceptron)
太好了,现在你知道线性分类器是如何工作的了,但是我们如何构建一个好的分类器呢?在构建分类器时,你从数据开始,这些数据被标记了正确的类别;我们称之为训练集 (training set)。你通过在训练数据上评估分类器,将其与你的训练标签进行比较,并调整分类器的参数直到达到目标,来构建分类器。
让我们探索一个简单线性分类器的具体实现:二元感知器。感知器是一个二元分类器——尽管它可以扩展到处理两个以上的类别。二元感知器的目标是找到一个完美分离训练数据的决策边界。换句话说,我们正在寻找尽可能好的权重——最好的 \(\mathbf{w}\)——使得任何特征化的训练点乘以权重都可以被完美分类。
算法 (The Algorithm)
感知器算法的工作原理如下:
-
将所有权重初始化为 0:w = 0
-
对于每个具有特征 \(f(x)\) 和真实类标签 \(y^* \in \{-1, +1\}\) 的训练样本,执行:
2.1 使用当前权重对样本进行分类,让 y 为你当前 w 预测的类别:
\[y = \text{classify}(x) = \begin{cases} +1 & \text{if } h_{\mathbf{w}}(\mathbf{x}) = \mathbf{w}^T \mathbf{f}(\mathbf{x}) > 0 \\ -1 & \text{if } h_{\mathbf{w}}(\mathbf{x}) = \mathbf{w}^T \mathbf{f}(\mathbf{x}) < 0 \end{cases}\]2.2 将预测标签 y 与真实标签 \(y^*\) 进行比较:
- 如果 y = \(y^*\),什么也不做
- 否则,如果 \(y \neq y^*\),则更新你的权重:\(w \leftarrow w + y^* f(x)\)
-
如果你遍历了每一个训练样本而无需更新你的权重(所有样本预测正确),则终止。否则,重复步骤 2
更新权重 (Updating weights)
让我们检查并证明更新权重的过程。回想一下,在上面的步骤 2b 中,当我们的分类器正确时,什么也没有改变。但是当我们的分类器错误时,权重向量更新如下:
\[\mathbf{w} \leftarrow \mathbf{w} + y^* \mathbf{f}(\mathbf{x})\]其中 \(y^*\) 是真实标签,为 1 或 -1,x 是我们错误分类的训练样本。你可以如下解释这个更新规则:
情况 1: 将正类误分类为负类
\[\mathbf{w} \leftarrow \mathbf{w} + \mathbf{f}(\mathbf{x})\]情况 2: 将负类误分类为正类
\[\mathbf{w} \leftarrow \mathbf{w} - \mathbf{f}(\mathbf{x})\]为什么这有效?看待这个问题的一种方式是将其视为一种平衡行为。误分类发生在训练样本的激活比它应该的小得多(导致情况 1 误分类)或比它应该的大得多(导致情况 2 误分类)时。
考虑情况 1,其中激活应该是正的,但却是负的。换句话说,激活太小了。我们调整 w 应该努力解决这个问题,并使该训练样本的激活变大。为了让你相信我们的更新规则 w ← w + f(x) 做到了这一点,让我们更新 w 并看看激活是如何变化的。
\[h_{\mathbf{w} + \mathbf{f}(\mathbf{x})}(\mathbf{x}) = (\mathbf{w} + \mathbf{f}(\mathbf{x}))^T \mathbf{f}(\mathbf{x}) = \mathbf{w}^T \mathbf{f}(\mathbf{x}) + \mathbf{f}(\mathbf{x})^T \mathbf{f}(\mathbf{x}) = h_{\mathbf{w}}(\mathbf{x}) + \mathbf{f}(\mathbf{x})^T \mathbf{f}(\mathbf{x})\]使用我们的更新规则,我们看到新的激活增加了 f(x)Tf(x),这是一个正数,因此表明我们的更新是有意义的。激活正在变大——更接近变为正数。你可以对分类器因为激活太大而误分类(激活应该是负的,但却是正的)的情况重复相同的逻辑。你会看到更新将导致新的激活减少 f(x)Tf(x),从而变小并更接近正确分类。
虽然这清楚地表明了为什么我们要加减某些东西,但为什么要加减我们样本点的特征呢?思考这个问题的一个好方法是,权重并不是决定这个分数的唯一因素。分数是通过将权重乘以相关样本来确定的。这意味着样本的某些部分比其他部分贡献更大。考虑以下情况,其中 x 是给我们的训练样本,真实标签 \(y^*\) = -1:
\[\mathbf{w}^T = \begin{bmatrix}2 & 2 & 2\end{bmatrix}, \quad \mathbf{f}(\mathbf{x}) = \begin{bmatrix}4 \\ 0 \\ 1\end{bmatrix} \quad h_{\mathbf{w}}(\mathbf{x}) = (2 \times 4) + (2 \times 0) + (2 \times 1) = 10\]我们知道我们的权重需要更小,因为激活需要为负才能正确分类。但我们不想对所有权重进行相同程度的更改。你会注意到我们样本的第一个元素 4 对我们 10 分的贡献比第三个元素大得多,而第二个元素根本没有贡献。因此,适当的权重更新将大幅改变第一个权重,少量改变第三个权重,而根本不改变第二个权重。毕竟,第二个和第三个权重甚至可能没有那么糟糕,我们不想修复没有损坏的东西!
当思考改变权重向量以满足上述愿望的好方法时,事实证明只使用样本本身确实能做到我们想要的;它大幅改变了第一个权重,少量改变了第三个权重,根本没有改变第二个权重!
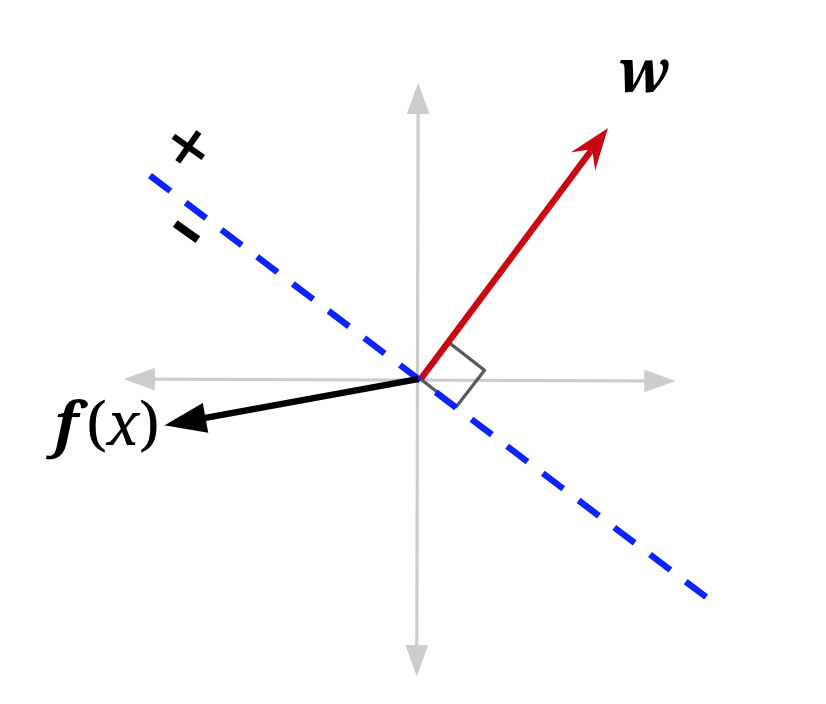
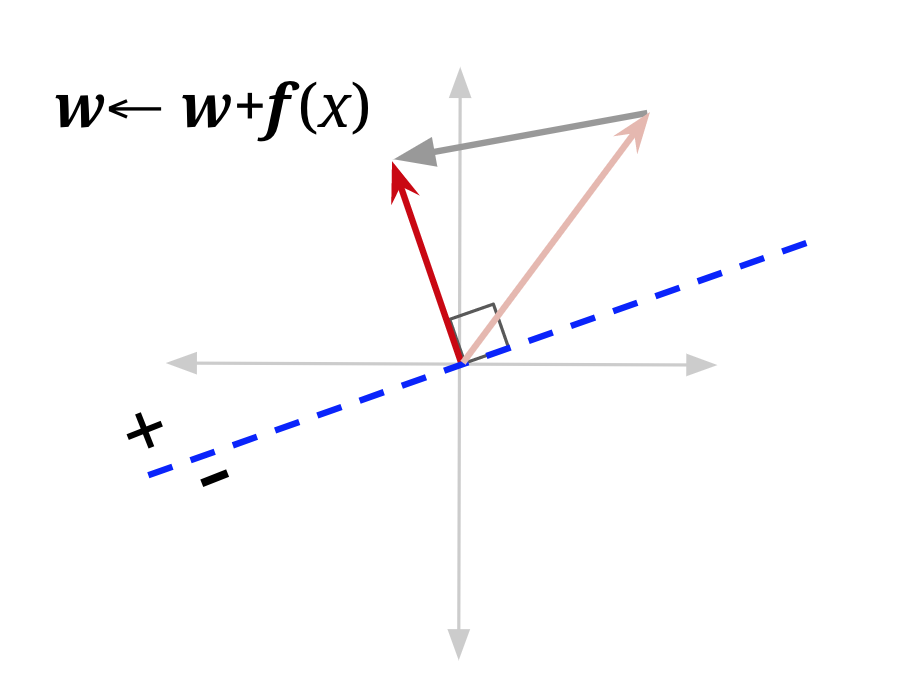
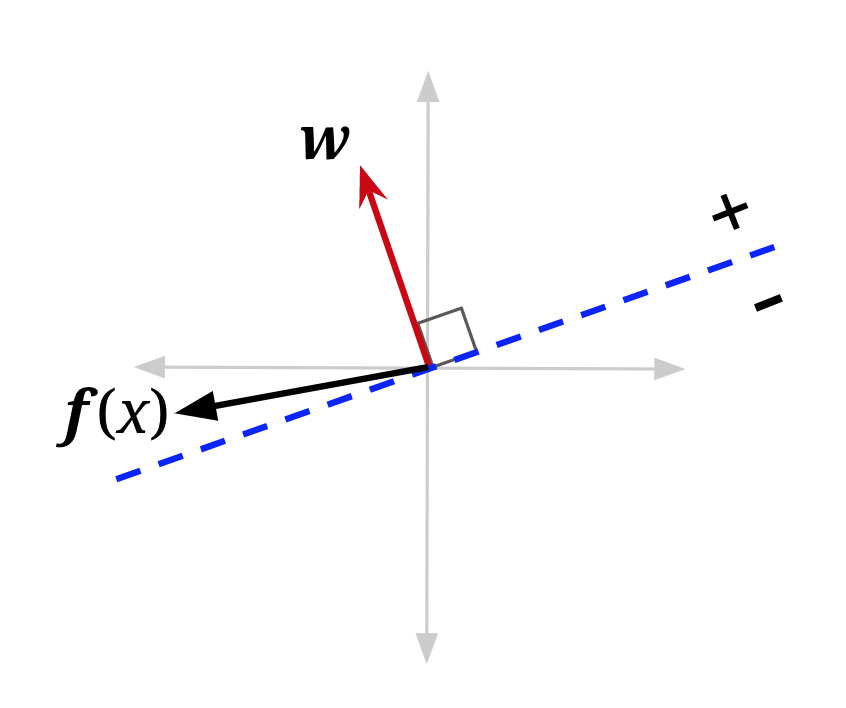
可视化也可能有帮助。在下图中,f(x) 是具有正类 (\(y^*\) = +1) 的数据点的特征向量,当前被误分类——它位于由“旧 w”定义的决策边界的错误一侧。将其添加到权重向量会产生一个新的权重向量,该向量与 f(x) 的角度更小。它也移动了决策边界。在这个例子中,它移动了决策边界足够多,使得 x 现在将被正确分类(注意错误并不总是会被修复——这取决于权重向量的大小,以及 f(x) 目前越过边界多远)。
偏置 (Bias)
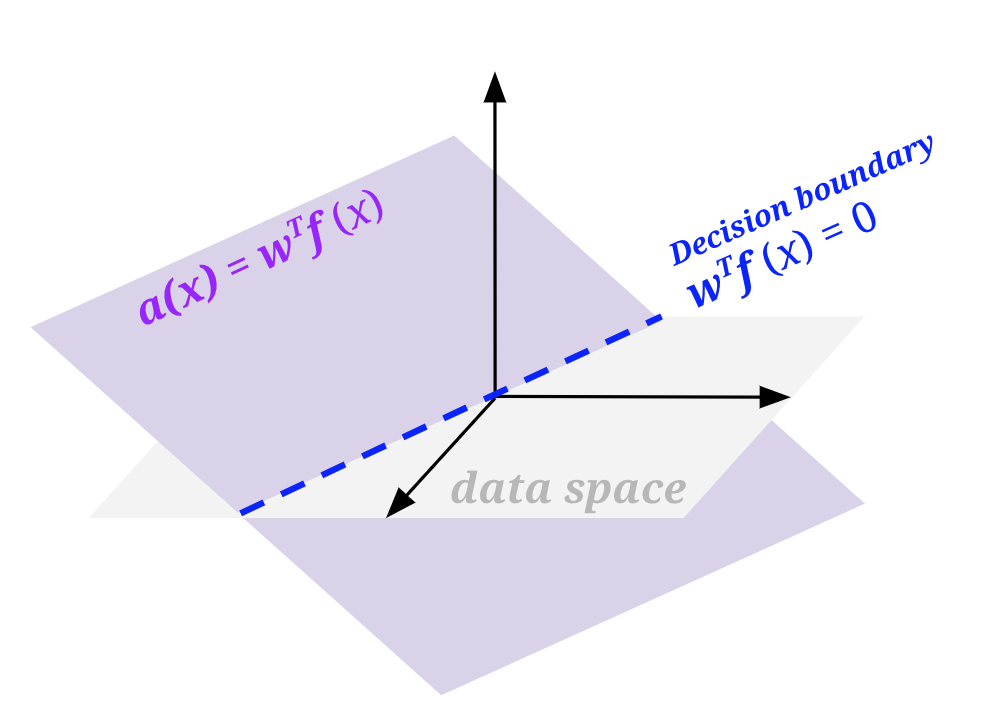
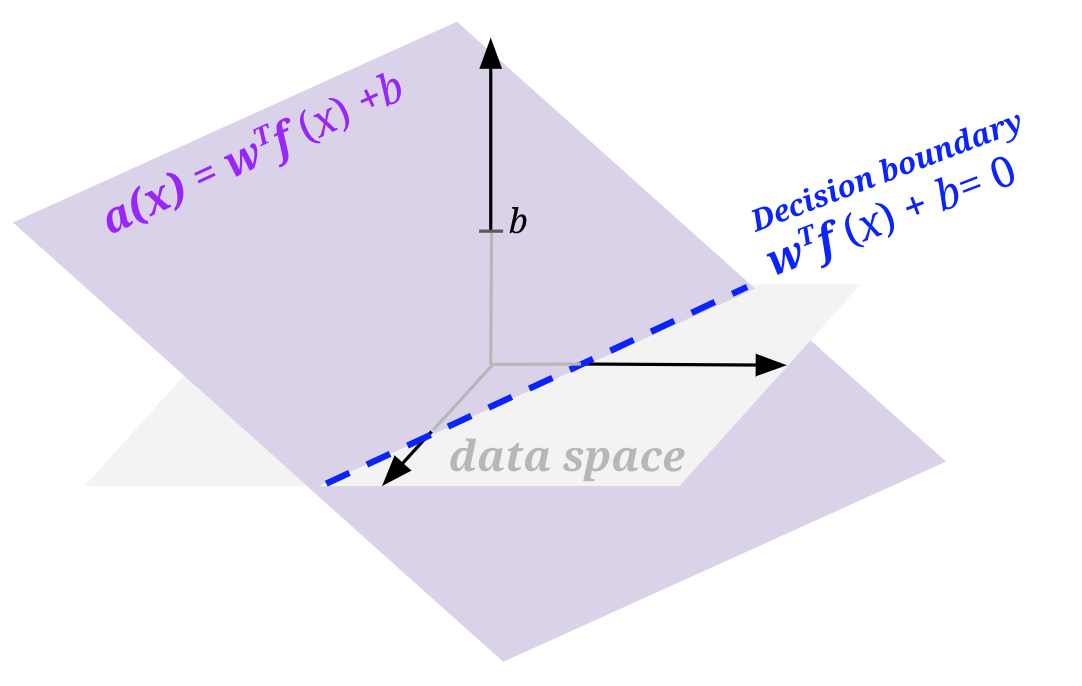
如果你尝试根据目前提到的内容实现感知器,你会注意到一个特别不友好的怪癖。你最终画出的任何决策边界都将穿过原点。基本上,你的感知器只能产生可以用函数 wTf(x) = 0 表示的决策边界,其中 w, f(x) \(\in \mathbb{R^n}\)。问题是,即使在数据中有线性决策边界分隔正类和负类的问题中,该边界也可能不经过原点,而我们希望能够画出这些线。
为此,我们将修改我们的特征和权重以添加偏置项:向你的样本特征向量添加一个始终为 1 的特征,并向你的权重向量添加该特征的额外权重。这样做本质上允许我们产生可以用 wTf(x) + b = 0 表示的决策边界,其中 b 是加权偏置项(即 1 * 权重向量中的最后一个权重)。
从几何上讲,我们可以通过思考激活函数是 wTf(x) 时和有偏置 wTf(x) + b 时的样子来可视化这一点。为此,我们需要比我们的特征化数据空间(下图中的标记数据空间)高一维。在所有上述部分中,我们只查看了数据空间的平面视图。
示例 (Example)
让我们看一个逐步运行感知器算法的示例。
让我们用感知器算法对数据进行一次遍历,按顺序获取每个数据点。我们将从权重向量 [w_0, w_1, w_2] = [-1, 0, 0] 开始(其中 w0 是我们偏置特征的权重,记住它总是 1)。
训练集
| # | f1 | f2 | \(y^*\) |
|---|---|---|---|
| 1 | 1 | 1 | - |
| 2 | 3 | 2 | + |
| 3 | 2 | 4 | + |
| 4 | 3 | 4 | + |
| 5 | 2 | 3 | - |
单次感知器更新遍历
| 步骤 | 权重 | 分数 | 正确? | 更新 |
|---|---|---|---|---|
| 1 | [-1, 0, 0] | -1 * 1 + 0 * 1 + 0 * 1 = -1 | 是 | 无 |
| 2 | [-1, 0, 0] | -1 * 1 + 0 * 3 + 0 * 2 = -1 | 否 | +[1, 3, 2] |
| 3 | [0, 3, 2] | 0 * 1 + 3 * 2 + 2 * 4 = 14 | 是 | 无 |
| 4 | [0, 3, 2] | 0 * 1 + 3 * 3 + 2 * 4 = 17 | 是 | 无 |
| 5 | [0, 3, 2] | 0 * 1 + 3 * 2 + 2 * 3 = 12 | 否 | -[1, 2, 3] |
| 6 | [-1, 1, -1] |
我们将在这里停止,但实际上,在单次遍历中所有数据点都被正确分类之前,该算法将对数据进行更多次遍历。
9.4.1 多类感知器 (Multiclass Perceptron)
上面介绍的感知器是一个二元分类器,但我们可以很容易地将其扩展到考虑多个类别。主要区别在于我们如何设置权重以及我们如何更新所述权重。对于二元情况,我们有一个权重向量,其维度等于特征的数量(加上偏置特征)。对于多类情况,我们将为每个类别拥有一个权重向量。所以,在 3 类情况下,我们有 3 个权重向量。为了对样本进行分类,我们通过计算特征向量与每个权重向量的点积来计算每个类别的分数。无论哪个类别产生最高分,都是我们选择作为预测的类别。
例如,考虑 3 类情况。让我们的样本具有特征 f(x) = [-2, 3, 1],我们对类别 0、1 和 2 的权重为:
\[\mathbf{w}_0 = \begin{bmatrix}-2 & 2 & 1\end{bmatrix}\] \[\mathbf{w}_1 = \begin{bmatrix}0 & 3 & 4\end{bmatrix}\] \[\mathbf{w}_2 = \begin{bmatrix}1 & 4 & -2\end{bmatrix}\]对每个类别进行点积给我们分数 \(s_0 = 11\), \(s_1 = 13\), \(s_2 = 8\)。因此我们将预测 x 属于类别 1。
需要注意的一件重要事情是,在实际实现中,我们不将权重作为单独的结构进行跟踪;我们通常将它们堆叠在一起以创建权重矩阵。这样,我们可以进行单次矩阵向量乘法,而不是进行与类别数量一样多的点积。这在实践中往往更有效(因为矩阵向量乘法通常具有高度优化的实现)。
在我们上面的情况下,那将是:
\[\mathbf{W} = \begin{bmatrix} -2 & 2 & 1 \\ 0 & 3 & 4 \\ 1 & 4 & -2 \end{bmatrix}, \quad \mathbf{x} = \begin{bmatrix}-2 \\ 3 \\ 1\end{bmatrix}\]我们的标签将是:
\[\arg\max (\mathbf{Wx}) = \arg\max \begin{bmatrix}11 \\ 13 \\ 8\end{bmatrix} = 1\]除了权重的结构外,当我们转移到多类情况时,我们的权重更新也会发生变化。如果我们正确分类了数据点,那么什么也不做,就像在二元情况下一样。如果我们选择错误,比如说我们选择了类别 \(y \neq y^*\),那么我们将特征向量加到真实类别 \(y^*\) 的权重向量上,并从对应于预测类别 \(y\) 的权重向量中减去特征向量。在我们上面的例子中,假设正确的类别是类别 2,但我们预测了类别 1。我们现在将取对应于类别 1 的权重向量并从中减去 x:
\[\mathbf{w}_1 = \begin{bmatrix}0 & 3 & 4\end{bmatrix} - \begin{bmatrix}-2 & 3 & 1\end{bmatrix} = \begin{bmatrix}2 & 0 & 3\end{bmatrix}\]接下来,我们取对应于正确类别(在我们的例子中是类别 2)的权重向量,并将 x 加到它上面:
\[\mathbf{w}_2 = \begin{bmatrix}1 & 4 & -2\end{bmatrix} + \begin{bmatrix}-2 & 3 & 1\end{bmatrix} = \begin{bmatrix}-1 & 7 & -1\end{bmatrix}\]这相当于“奖励”正确的权重向量,“惩罚”误导性的、不正确的权重向量,而不理会其他权重向量。考虑到权重和权重更新的差异,算法的其余部分本质上是相同的:循环遍历每个样本点,在犯错时更新权重,直到你不再犯错。
为了合并偏置项,做与我们为二元感知器所做的相同的事情——向每个特征向量添加一个额外的 1 特征,并向每个类别的权重向量添加该特征的额外权重(这相当于向矩阵形式添加额外的一列)。