1.4 Informed Search (有信息搜索)
一致代价搜索很好,因为它既完备又最优,但它可能相当慢,因为它在寻找目标时从开始状态向各个方向扩展。如果我们对应该集中搜索的方向有一些概念,我们可以显著提高性能并更快地“锁定”目标。这正是 informed search(有信息搜索)的重点。
1.4.1 Heuristics (启发式)
Heuristics(启发式)是允许估计到目标状态距离的驱动力——它们是将状态作为输入并输出相应估计值的函数。这种函数执行的计算特定于正在解决的搜索问题。由于我们将在下面的 A* 搜索中看到的原因,我们通常希望启发式函数是到目标的剩余距离的下界,因此启发式通常是 relaxed problems(松弛问题)(其中原始问题的一些约束已被移除)的解决方案。回到我们的 Pacman 示例,让我们考虑前面描述的寻路问题。用于解决此问题的一个常见启发式是 Manhattan distance(曼哈顿距离),对于两点 (\(x_1\), \(y_1\)) 和 (\(x_2\), \(y_2\)),其定义如下:
\[Manhattan(x_1, y_1, x_2, y_2) = |x_1 - x_2| + |y_1 - y_2|\]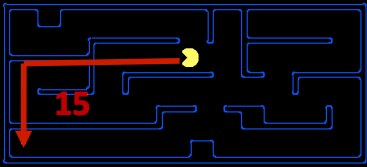
上面的可视化显示了曼哈顿距离有助于解决的松弛问题——假设 Pacman 想要到达迷宫的左下角,它计算从 Pacman 当前位置到 Pacman 期望位置的距离,假设迷宫中没有墙壁。这个距离是松弛搜索问题中的 exact(精确)目标距离,相应地是实际搜索问题中的 estimated(估计)目标距离。有了启发式,在我们的智能体中实现逻辑变得非常容易,使它们在决定执行哪个动作时能够“更喜欢”扩展估计更接近目标状态的状态。这种偏好概念非常强大,并被以下两种实现启发式函数的搜索算法所利用:贪婪搜索和 A*。
1.4.2 Greedy Search (贪婪搜索)
- Description(描述) - 贪婪搜索是一种探索策略,它总是选择具有 lowest heuristic value(最低启发式值)的边界节点进行扩展,这对应于它认为最接近目标的状态。
- Frontier Representation(边界表示) - 贪婪搜索的操作与 UCS 相同,具有优先级队列边界表示。区别在于,贪婪搜索不使用 computed backward cost(计算的向后成本)(到状态路径中的边权重之和)来分配优先级,而是使用启发式值形式的 estimated forward cost(估计的向前成本)。
- Completeness and Optimality(完备性和最优性) - 如果存在目标状态,贪婪搜索不保证找到它,也不保证是最优的,特别是在选择了非常糟糕的启发式函数的情况下。它通常在不同的场景中表现得相当不可预测,范围从直接到达目标状态到像被错误引导的 DFS 一样探索所有错误的区域。
1.4.3 A* Search (A* 搜索)
- Description(描述) - A* 搜索是一种探索策略,它总是选择具有 lowest estimated total cost(最低估计总成本)的边界节点进行扩展,其中总成本是从开始节点到目标节点的全部成本。
- Frontier Representation(边界表示) - 就像贪婪搜索和 UCS 一样,A* 搜索也使用优先级队列来表示其边界。同样,唯一的区别是优先级选择的方法。A* 将 UCS 使用的总向后成本(到状态路径中的边权重之和)与贪婪搜索使用的估计向前成本(启发式值)相结合,通过将这两个值相加,有效地产生从开始到目标的 estimated total cost(估计总成本)。鉴于我们要最小化从开始到目标的总成本,这是一个极好的选择。
- Completeness and Optimality(完备性和最优性) - 给定适当的启发式(我们将在稍后介绍),A* 搜索既是完备的又是最优的。它是我们目前涵盖的所有其他搜索策略优点的结合,结合了贪婪搜索通常的高速度与 UCS 的最优性和完备性!
1.4.4. Admissibility (可采纳性)
现在我们已经讨论了启发式以及它们如何应用于贪婪搜索和 A* 搜索,让我们花点时间讨论什么构成了好的启发式。为此,让我们首先使用以下定义重新制定用于确定 UCS、贪婪搜索和 A* 中优先级队列顺序的方法:
- \(g(n)\) - 表示 UCS 计算的总向后成本的函数。
- \(h(n)\) - 贪婪搜索使用的 heuristic value(启发式值)函数,或估计的向前成本。
- \(f(n)\) - 表示估计总成本的函数,由 A* 搜索使用。\(f(n) = g(n) + h(n)\)。
在解决什么构成“好”启发式的问题之前,我们必须首先回答 A* 是否无论我们使用什么启发式函数都能保持其完备性和最优性属性的问题。确实,很容易找到破坏这两个令人垂涎的属性的启发式。作为一个例子,考虑启发式函数 \(h(n) = 1 - g(n)\)。无论搜索问题如何,使用此启发式都会产生:
\[f(n) = g(n) + h(n) = g(n) + (1 - g(n)) = 1\]因此,这样的启发式将 A* 搜索简化为 BFS,其中所有边成本都相等。正如我们已经展示的那样,在边权重不恒定的一般情况下,BFS 不保证是最优的。
使用 A* 树搜索时最优性所需的条件称为 admissibility(可采纳性)。可采纳性约束指出,可采纳启发式估计的值既不是负数也不是高估。将 \(h^*(n)\) 定义为从给定节点 n 到达目标状态的真实最优向前成本,我们可以用数学公式表示可采纳性约束如下:
\[\forall n, 0 \leq h(n) \leq h^*(n)\]Theorem. 对于给定的搜索问题,如果启发式函数 h 满足可采纳性约束,则在该搜索问题上使用带有 h 的 A* 树搜索将产生最优解。
Proof. 假设给定搜索问题的搜索树中有两个可达的目标状态,一个最优目标 \(A\) 和一个次优目标 \(B\)。\(A\) 的某个祖先 \(n\)(可能包括 \(A\) 本身)目前必须在边界上,因为 \(A\) 是从开始状态可达的。我们声称 \(n\) 将在 \(B\) 之前被选择进行扩展,使用以下三个陈述:
- \(g(A) < g(B)\)。因为已知 \(A\) 是最优的而 \(B\) 是次优的,我们可以得出结论,\(A\) 到开始状态的向后成本低于 \(B\)。
- \(h(A) = h(B) = 0\),因为我们已知我们的启发式满足可采纳性约束。由于 \(A\) 和 \(B\) 都是目标状态,从 \(A\) 或 \(B\) 到目标状态的真实最优成本只是 \(h^*(n) = 0\);因此 \(0 \leq h(n) \leq 0\)。
- \(f(n) \leq f(A)\),因为通过 \(h\) 的可采纳性,\(f(n)=g(n)+h(n) \leq g(n) + h^*(n) = g(A) = f(A)\)。通过节点 \(n\) 的总成本最多是 \(A\) 的真实向后成本,这也是 \(A\) 的总成本。
我们可以结合陈述 1. 和 2. 得出 \(f(A) < f(B)\) 如下:
\[f(A) = g(A) + h(A) = g(A) < g(B) = g(B) + h(B) = f(B)\]结合上述推导的不等式与陈述 3. 的一个简单推论如下:
\[f(n) \leq f(A) \land f(A) < f(B) \rightarrow f(n) < f(B)\]因此,我们可以得出结论,\(n\) 在 \(B\) 之前被扩展。因为我们已经证明了任意 \(n\),我们可以得出结论,\(A\) 的 all(所有)祖先(包括 \(A\) 本身)都在 \(B\) 之前扩展。
我们在上面发现的树搜索的一个问题是,在某些情况下,它可能永远无法找到解决方案,陷入无限循环搜索状态空间图中的同一个循环。即使在我们的搜索技术不涉及这种无限循环的情况下,我们也经常多次重新访问同一个节点,因为有多种方法可以到达同一个节点。这导致指数级更多的工作,自然的解决方案是简单地跟踪你已经扩展了哪些状态,并且永远不要再次扩展它们。更明确地说,在使用你选择的搜索方法时维护一个已扩展节点的“reached”(已到达)集合。然后,确保每个节点在扩展之前不在集合中,如果不在,则在扩展后将其添加到集合中。带有这种添加优化的树搜索被称为 graph search(图搜索)。1 此外,还有一个维持最优性所需的关键因素。考虑下面简单的状态空间图和相应的搜索树,注释有权重和启发式值:
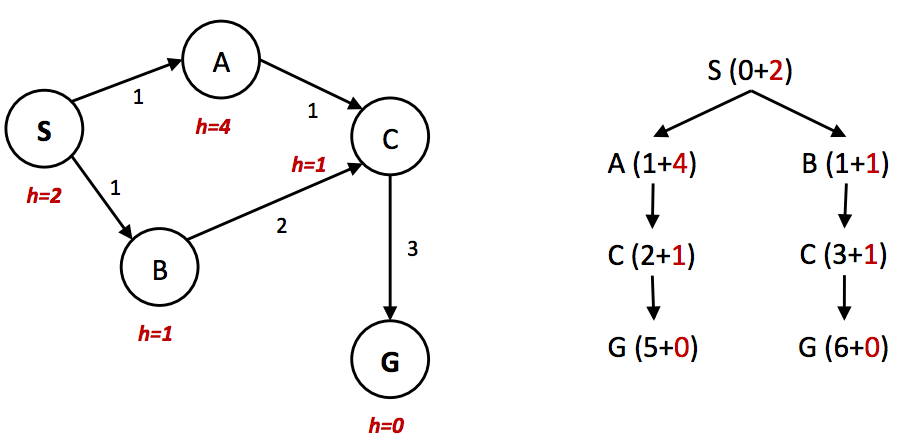
在上面的例子中,很明显最优路线是遵循 \(S → A → C → G\),产生的总路径成本为 1 + 1 + 3 = 5。通往目标的唯一另一条路径 \(S → B → C → G\) 的路径成本为 1 + 2 + 3 = 6。然而,因为节点 A 的启发式值比节点 \(B\) 的启发式值大得多,节点 \(C\) 首先作为节点 \(B\) 的子节点沿着第二条次优路径扩展。然后它被放入“已到达”集合中,因此 A* 图搜索在作为 \(A\) 的子节点访问它时未能重新扩展它,因此它永远找不到最优解。因此,为了在 A* 图搜索下保持最优性,我们不仅需要检查 A* 是否已经访问过一个节点,还需要检查它是否找到了通往它的更便宜的路径。
function A*-GRAPH-SEARCH(problem, frontier) return a solution or failure
reached ← an empty dict mapping nodes to the cost to each one
frontier ← INSERT((MAKE-NODE(INITIAL-STATE[problem]),0), frontier)
while not IS-EMPTY(frontier) do
node, node.CostToNode ← POP(frontier)
if problem.IS-GOAL(node.STATE) then return node
if node.STATE is not in reached or reached[node.STATE] > node.CostToNode then
reached[node.STATE] = node.CostToNode
for each child-node in EXPAND(problem, node) do
frontier ← INSERT((child-node, child-node.COST + CostToNode), frontier)
return failure
请注意,在实现中,将已到达集合存储为不相交集而不是列表至关重要。将其存储为列表需要 \(O(n)\) 操作来检查成员资格,这消除了图搜索旨在提供的性能改进。
在继续之前,上述讨论的几个重要亮点:对于有效的可采纳启发式,根据定义,对于任何目标状态 \(G\),必须是 \(h(G) = 0\)。
1.4.5 Dominance (优势)
既然我们已经建立了可采纳性的属性及其在维持 A* 搜索最优性中的作用,我们可以回到创建“好”启发式的原始问题,以及如何判断一个启发式是否比另一个更好。对此的标准度量是 dominance(优势)。如果启发式 \(a\) 优于启发式 \(b\),那么对于状态空间图中的每个节点,\(a\) 的估计目标距离大于 \(b\) 的估计目标距离。数学上,
\[\forall n: h_a(n) \geq h_b(n)\]优势非常直观地捕捉了一个启发式比另一个更好的想法——如果一个可采纳启发式优于另一个,它必须更好,因为它总是更接近地估计从任何给定状态到目标的距离。此外,trivial heuristic(平凡启发式)定义为 \(h(n) = 0\),使用它将 A* 搜索简化为 UCS。所有可采纳启发式都优于平凡启发式。平凡启发式通常包含在搜索问题的 semi-lattice(半格)的底部,这是一个优势层次结构,它位于底部。下面是一个半格的例子,它包含了各种启发式 \(h_a\), \(h_b\), 和 \(h_c\),范围从底部的平凡启发式到顶部的精确目标距离:
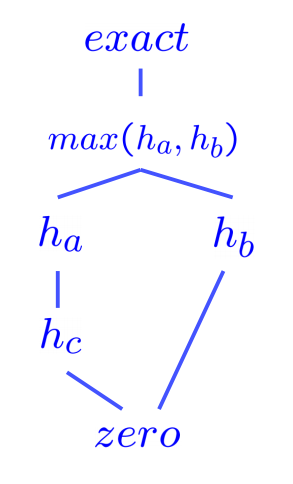
作为一般规则,应用于多个可采纳启发式的 max 函数也将始终是可采纳的。这只是所有启发式对任何给定状态输出的值都受到可采纳性条件 \(0 \leq h(n) \leq h^*(n)\) 约束的结果。此范围内数字的最大值也必须落在同一范围内。通常的做法是为任何给定的搜索问题生成多个可采纳启发式,并计算它们输出值的最大值,以生成一个优于(因此优于)它们中任何一个的启发式。
-
在其他课程中,如 CS70 和 CS170,你可能已经在图论背景下接触过“树”和“图”。具体来说,树是一种满足某些约束(连通且无环)的图。这不是我们在本课程中区分树搜索和图搜索的区别。 ↩