1.3 Uninformed Search (无信息搜索)
找到从开始状态到目标状态的计划的标准协议是维护从搜索树派生的部分计划的外部 frontier(边界)。我们不断 expand(扩展)我们的边界,方法是从边界中移除一个节点(该节点是使用我们给定的 strategy(策略)选择的),该节点对应于一个部分计划,并将其所有子节点替换到边界上。移除并用其子节点替换边界上的元素对应于丢弃单个长度为 n 的计划,并将所有源自它的长度为 \((n+1)\) 的计划纳入考虑范围。我们继续这样做,直到最终从边界移除一个目标状态,此时我们得出结论,对应于移除的目标状态的部分计划实际上是从开始状态到目标状态的路径。
实际上,此类算法的大多数实现都会在节点对象内编码有关父节点、到节点的距离和状态的信息。我们刚刚概述的这个过程被称为 tree search(树搜索),其伪代码如下所示:
function TREE-SEARCH(problem, frontier) return a solution or failure
frontier ← INSERT(MAKE-NODE(INITIAL-STATE[problem]), frontier)
while not IS-EMPTY(frontier) do
node ← POP(frontier)
if problem.IS-GOAL(node.STATE) then return node
for each child-node in EXPAND(problem, node) do
add child-node to frontier
return failure
出现在伪代码中的 EXPAND 函数通过考虑所有可用动作返回从给定节点可以到达的所有可能节点。该函数的伪代码如下:
function EXPAND(problem, node) yields nodes
s ← node.STATE
for each action in problem.ACTIONS(s) do
s' ← problem.RESULT(s, action)
yield NODE(STATE=s', PARENT=node, ACTION=action)
当我们不知道目标状态在搜索树中的位置时,我们被迫从属于 uninformed search(无信息搜索)保护伞下的技术之一中选择我们的树搜索策略。我们现在将连续介绍三种这样的策略:depth-first search(深度优先搜索)、breadth-first search(广度优先搜索)和 uniform cost search(一致代价搜索)。除了每种策略外,还根据以下方面介绍了策略的一些基本属性:
- 每个搜索策略的 completeness(完备性) - 如果搜索问题存在解决方案,该策略是否保证在给定无限计算资源的情况下找到它?
- 每个搜索策略的 optimality(最优性) - 该策略是否保证找到通往目标状态的最低成本路径?
- Branching factor(分支因子) \(b\) - 每次将边界节点出队并替换为其子节点时,边界上节点数量的增加为 \(O(b)\)。在搜索树的深度 k 处,存在 \(O(b^{k})\) 个节点。
- 最大深度 m。
- 最浅解决方案的深度 s。
1.3.1 Depth-First Search (深度优先搜索)
- Description(描述) - 深度优先搜索 (DFS) 是一种探索策略,它总是选择从开始节点算起 deepest(最深)的边界节点进行扩展。
- Frontier Representation(边界表示) - 移除最深的节点并将其子节点替换到边界上必然意味着子节点现在是新的最深节点——它们的深度比前一个最深节点的深度大一。这意味着要实现 DFS,我们需要一个始终给予最近添加的对象最高优先级的结构。后进先出 (LIFO) 堆栈正是这样做的,并且是实现 DFS 时传统上用于表示边界的结构。
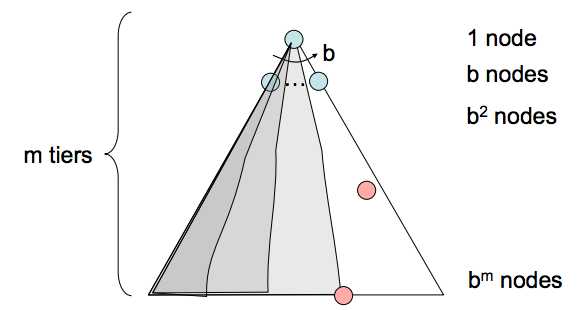
- Completeness(完备性) - 深度优先搜索不完备。如果状态空间图中存在循环,这不可避免地意味着相应的搜索树在深度上将是无限的。因此,存在 DFS 忠实但悲剧地“卡在”无限大小的搜索树中寻找最深节点的可能性,注定永远找不到解决方案。
- Optimality(最优性) - 深度优先搜索只是在搜索树中找到“最左边”的解决方案,而不考虑路径成本,因此不是最优的。
- Time Complexity(时间复杂度) - 在最坏的情况下,深度优先搜索最终可能会探索整个搜索树。因此,给定最大深度为 \(m\) 的树,DFS 的运行时间为 \(O(b^{m})\)。
- Space Complexity(空间复杂度) - 在最坏的情况下,DFS 在边界上的 \(m\) 个深度级别中的每一个级别维护 b 个节点。这是因为一旦某个父节点的 \(b\) 个子节点入队,DFS 的性质允许在任何给定时间点仅探索这些子节点之一的子树。因此,DFS 的空间复杂度为 \(O(bm)\)。
1.3.2 Breadth-First Search (广度优先搜索)
- Description(描述) - 广度优先搜索是一种探索策略,它总是选择从开始节点算起 shallowest(最浅)的边界节点进行扩展。
- Frontier Representation(边界表示) - 如果我们想在较深的节点之前访问较浅的节点,我们必须按插入顺序访问节点。因此,我们需要一个输出最老的入队对象来表示我们的边界的结构。为此,BFS 使用先进先出 (FIFO) 队列,它正是这样做的。
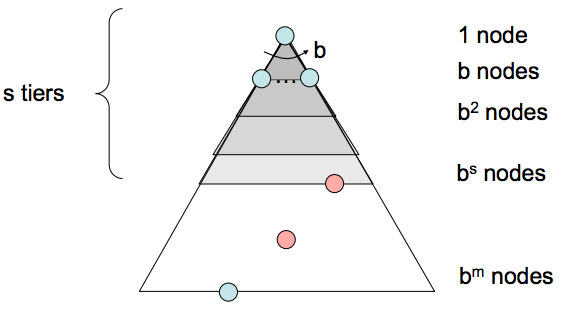
- Completeness(完备性) - 如果存在解决方案,那么最浅节点 \(s\) 的深度必须是有限的,因此 BFS 最终必须搜索此深度。因此,它是完备的。
- Optimality(最优性) - BFS 通常不是最优的,因为它在确定要替换边界上的哪个节点时根本不考虑成本。BFS 保证最优的特殊情况是如果所有边成本都相等,因为这将 BFS 简化为一致代价搜索的特例,如下所述。
- Time Complexity(时间复杂度) - 在最坏的情况下,我们必须搜索 \(1 + b + b^{2} + ... + b^{s}\) 个节点,因为我们遍历从 1 到 \(s\) 的每个深度的所有节点。因此,时间复杂度为 \(O(b^s)\)。
- Space Complexity(空间复杂度) - 在最坏的情况下,边界包含对应于最浅解决方案级别的所有节点。由于最浅的解决方案位于深度 \(s\),因此在此深度有 \(O(b^{s})\) 个节点。
1.3.3 Uniform Cost Search (一致代价搜索)
- Description(描述) - 一致代价搜索 (UCS),我们的最后一个策略,是一种探索策略,它总是选择从开始节点算起 lowest cost(最低成本)的边界节点进行扩展。
- Frontier Representation(边界表示) - 为了表示 UCS 的边界,通常选择基于堆的优先级队列,其中给定入队节点 \(v\) 的优先级是从开始节点到 \(v\) 的路径成本,或 \(v\) 的 backward cost(向后成本)。直观地说,以这种方式构建的优先级队列只是在我们移除当前最小成本路径并将其替换为其子节点时重新洗牌以保持所需的路径成本顺序。
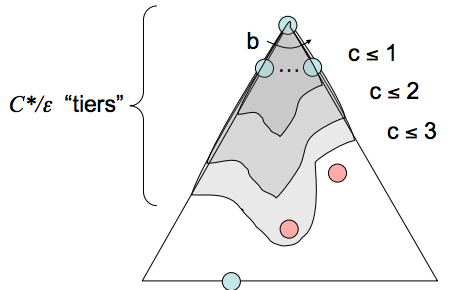
- Completeness(完备性) - 一致代价搜索是完备的。如果存在目标状态,它必须具有某种有限长度的最短路径;因此,UCS 最终必须找到这条最短长度路径。
- Optimality(最优性) - 如果我们假设所有边成本都是非负的,UCS 也是最优的。通过构造,由于我们按路径成本增加的顺序探索节点,我们保证找到通往目标状态的最低成本路径。一致代价搜索中采用的策略与 Dijkstra 算法的策略相同,主要区别在于 UCS 在找到解决方案状态时终止,而不是找到通往所有状态的最短路径。请注意,在我们的图中具有负边成本会使路径上的节点长度减少,从而破坏我们的最优性保证。(参见 Bellman-Ford 算法,这是一种处理这种可能性的较慢算法)
- Time Complexity(时间复杂度) - 让我们将最佳路径成本定义为 \(C*\),将状态空间图中两个节点之间的最小成本定义为 \(\varepsilon\)。然后,我们必须大致探索深度范围从 1 到 \(\frac{C*}{\varepsilon}\) 的所有节点,导致运行时间为 \(O(b^{\frac{C*}{\varepsilon}})\)。
- Space Complexity(空间复杂度) - 大致来说,边界将包含最便宜解决方案级别的所有节点,因此 UCS 的空间复杂度估计为 \(O(b^{\frac{C*}{\varepsilon}})\)。
作为关于无信息搜索的最后一点说明,重要的是要注意上面概述的三种策略在根本上是相同的——仅在扩展策略上有所不同,它们的相似之处由上面介绍的树搜索伪代码捕获。