4.3 值迭代 (Value Iteration)
既然我们有了一个框架来测试 MDP 中状态值的最优性,自然而然的后续问题是如何实际计算这些最优值。为了回答这个问题,我们需要时间限制值 (time-limited values)(强制执行有限视界的自然结果)。时间限制为 \(k\) 个时间步的状态 \(s\) 的时间限制值表示为 \(V_k(s)\),它表示在考虑的马尔可夫决策过程在 \(k\) 个时间步内终止的情况下,从 \(s\) 可获得的最大期望效用。等效地,这就是在 MDP 的搜索树上运行深度为 \(k\) 的 expectimax 所返回的值。
值迭代 (Value iteration) 是一种动态规划算法 (dynamic programming algorithm),它使用迭代增长的时间限制来计算时间限制值,直到收敛(即,直到 \(V\) 值对于每个状态都与过去迭代中的相同:\(\forall s, V_{k+1}(s) = V_{k}(s)\))。其操作如下:
- \(\forall s \in S,\) 初始化 \(V_0(s) = 0\)。这应该是直观的,因为设置 0 个时间步的时间限制意味着在终止之前不能采取任何动作,因此无法获得任何奖励。
-
重复以下更新规则直到收敛:
\[\forall s \in S, \:\: V_{k+1}(s) \leftarrow \max_a \sum_{s'}T(s, a, s')[R(s, a, s') + \gamma V_k(s')]\]在值迭代的第 \(k\) 次迭代中,我们使用每个状态的限制为 \(k\) 的时间限制值来生成限制为 \((k+1)\) 的时间限制值。本质上,我们使用已计算的子问题解(所有 \(V_k(s)\))来迭代地构建更大子问题的解(所有 \(V_{k+1}(s)\));这就是使值迭代成为动态规划算法的原因。
注意,虽然贝尔曼方程看起来与上面的更新规则本质上相同,但它们并不一样。贝尔曼方程给出了最优性的条件,而更新规则给出了一种迭代更新值直到收敛的方法。当达到收敛时,贝尔曼方程将对每个状态成立:\(\forall s \in S, \:\: V_k(s) = V_{k+1}(s) = V^*(s)\)。
为了简洁起见,我们经常用简写 \(V_{k+1} \leftarrow BU_k\) 表示 \(U_{k+1}(s) \leftarrow \max_a \sum_{s'}T(s, a, s')[R(s, a, s') + \gamma V_k(s')]\),其中 \(B\) 被称为贝尔曼算子 (Bellman operator)。贝尔曼算子是一个 \(\gamma\) 收缩。为了证明这一点,我们需要以下一般不等式:
\[| \max_z f(z) - \max_z h(z) | \leq \max_z |f(z) - h(z)|.\]现在考虑在同一状态评估的两个值函数 \(V(s)\) 和 \(V'(s)\)。我们证明贝尔曼更新 \(B\) 是关于最大范数的 \(\gamma \in (0, 1)\) 收缩,如下所示:
\(\begin{aligned} &|BV(s) - BV'(s)| \\ &= \left| \left( \max_a \sum_{s'}T(s, a, s')[R(s, a, s') + \gamma V(s')] \right) - \left( \max_a \sum_{s'}T(s, a, s')[R(s, a, s') + \gamma V'(s')] \right) \right| \\ &\leq \max_a \left| \sum_{s'}T(s, a, s')[R(s, a, s') + \gamma V(s')] - \sum_{s'}T(s, a, s')[R(s, a, s') + \gamma V'(s')] \right| \\ &= \max_a \left| \gamma \sum_{s'}T(s, a, s')V(s') - \gamma \sum_{s'}T(s, a, s')V'(s') \right| \\ &= \gamma \max_a \left| \sum_{s'}T(s, a, s')(V(s') - V'(s')) \right| \\ &\leq \gamma \max_a \left| \sum_{s'}T(s, a, s') \max_{s'} \left| V(s') - V'(s') \right| \right| \\ &= \gamma \max_{s'} \left| V(s') - V'(s') \right| \\ &= \gamma ||V(s') - V'(s')||_{\infty}, \end{aligned}\)
其中第一个不等式遵循上面介绍的一般不等式,第二个不等式遵循取 \(V\) 和 \(V'\) 之间差值的最大值,在倒数第二步中,我们使用了无论选择 \(a\) 如何,概率总和为 1 的事实。最后一步使用了向量 \(x = (x_1, \ldots, x_n)\) 的最大范数的定义,即 \(||x||_{\infty} = \max(|x_1|, \ldots, |x_n|)\)。
因为我们刚刚证明了通过贝尔曼更新进行的值迭代是 \(\gamma\) 收缩,我们知道值迭代会收敛,并且当达到满足 \(V^* = BU^*\) 的不动点时发生收敛。
让我们通过重温之前的赛车 MDP 来看看实践中的几次值迭代更新,引入折扣因子 \(\gamma = 0.5\):
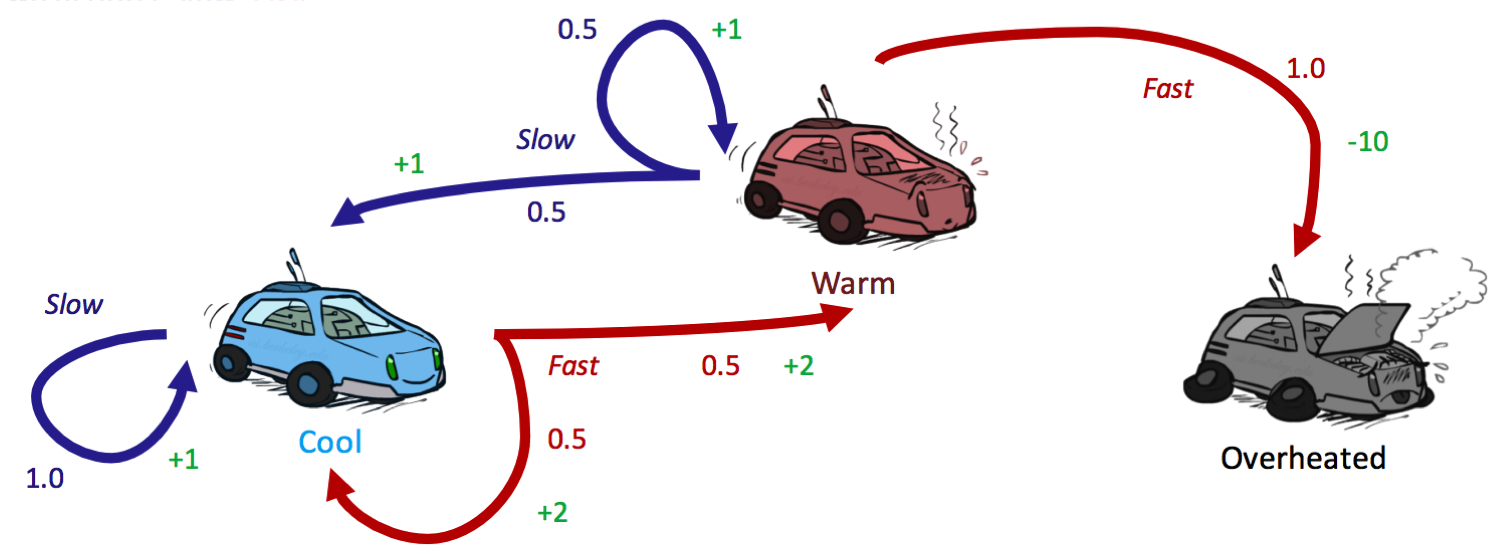
我们通过初始化所有 \(V_0(s) = 0\) 开始值迭代:
| cool | warm | overheated | |
|---|---|---|---|
| \(V_0\) | 0 | 0 | 0 |
在我们的第一轮更新中,我们可以如下计算 \(\forall s \in S, \:\: V_1(s)\):
\[\begin{aligned} V_1(cool) &= \max \{1 \cdot [1 + 0.5 \cdot 0],\:\: 0.5 \cdot [2 + 0.5 \cdot 0] + 0.5 \cdot [2 + 0.5 \cdot 0]\} \\ &= \max \{1, 2\} \\ &= \boxed{2} \\ V_1(warm) &= \max \{0.5 \cdot [1 + 0.5 \cdot 0] + 0.5 \cdot [1 + 0.5 \cdot 0],\:\: 1 \cdot [-10 + 0.5 \cdot 0]\} \\ &= \max \{1, -10\} \\ &= \boxed{1} \\ V_1(overheated) &= \max \{\} \\ &= \boxed{0} \end{aligned}\]| cool | warm | overheated | |
|---|---|---|---|
| \(U_0\) | 0 | 0 | 0 |
| \(U_1\) | 2 | 1 | 0 |
同样,我们可以重复该过程,使用我们新发现的 \(U_1(s)\) 值计算第二轮更新以计算 \(V_2(s)\):
\[\begin{aligned} V_2(cool) &= \max \{1 \cdot [1 + 0.5 \cdot 2],\:\: 0.5 \cdot [2 + 0.5 \cdot 2] + 0.5 \cdot [2 + 0.5 \cdot 1]\} \\ &= \max \{2, 2.75\} \\ &= \boxed{2.75} \\ V_2(warm) &= \max \{0.5 \cdot [1 + 0.5 \cdot 2] + 0.5 \cdot [1 + 0.5 \cdot 1],\:\: 1 \cdot [-10 + 0.5 \cdot 0]\} \\ &= \max \{1.75, -10\} \\ &= \boxed{1.75} \\ V_2(overheated) &= \max \{\} \\ &= \boxed{0} \end{aligned}\]| cool | warm | overheated | |
|---|---|---|---|
| \(V_0\) | 0 | 0 | 0 |
| \(V_1\) | 2 | 1 | 0 |
| \(V_2\) | 2.75 | 1.75 | 0 |
值得观察的是,任何终止状态的 \(V^*(s)\) 必须为 0,因为永远无法从任何终止状态采取任何动作来获得任何奖励。
4.3.1 策略提取 (Policy Extraction)
回想一下,我们解决 MDP 的最终目标是确定最优策略。一旦使用称为策略提取 (policy extraction) 的方法确定了状态的所有最优值,就可以做到这一点。策略提取背后的直觉非常简单:如果你在状态 \(s\),你应该采取产生最大期望效用的动作 \(a\)。不足为奇的是,\(a\) 是带我们进入具有最大 Q-值的 Q-状态的动作,允许对最优策略进行正式定义:
\[\forall s \in S, \:\: \pi^*(s) = \underset{a}{\operatorname{argmax}}\: Q^*(s, a) = \underset{a}{\operatorname{argmax}}\: \sum_{s'}T(s, a, s')[R(s, a, s') + \gamma V^*(s')]\]出于性能原因,记住这一点很有用:对于策略提取来说,拥有状态的最优 Q-值更好,在这种情况下,只需要单个 \(\operatorname{argmax}\) 操作即可确定状态的最优动作。仅存储每个 \(V^*(s)\) 意味着我们必须在应用 \(\operatorname{argmax}\) 之前用贝尔曼方程重新计算所有必要的 Q-值,这相当于执行深度为 1 的 expectimax。
4.3.2 Q-值迭代 (Q-Value Iteration)
在使用值迭代求解最优策略时,我们首先找到所有最优值,然后使用策略提取来提取策略。然而,你可能已经注意到我们也处理另一种编码关于最优策略信息的价值类型:Q-值。
Q-值迭代 (Q-value iteration) 是一种计算时间限制 Q-值的动态规划算法。它在以下方程中描述:
\[Q_{k+1}(s, a) \leftarrow \sum_{s'}T(s, a, s')[R(s, a, s') + \gamma \max_{a'} Q_k(s', a')]\]注意,此更新仅是对值迭代更新规则的轻微修改。实际上,唯一真正的区别是 \(\max\) 算子在动作上的位置发生了变化,因为我们在处于状态时在转移之前选择动作,但在处于 Q-状态时在选择新动作之前转移。一旦我们有了每个状态和动作的最优 Q-值,我们就可以通过简单地选择具有最高 Q-值的动作来找到状态的策略。