3.2 Minimax
我们考虑的第一个零和博弈 (zero-sum-game) 算法是 minimax,它基于这样一个假设:我们要面对的对手表现出最优行为,并且总是会采取对我们最不利的行动。为了介绍这个算法,我们必须首先形式化 terminal utilities(终止效用)和 state value(状态值)的概念。一个状态的值是控制该状态的代理 (agent) 可以获得的最佳分数。为了理解这意味着什么,观察下面这个简单的吃豆人 (Pacman) 游戏棋盘:

假设 Pacman 从 10 分开始,每移动一步失去 1 分,直到他吃到豆子,此时游戏到达 terminal state(终止状态)并结束。我们可以为这个棋盘构建一个 game tree(博弈树),如下所示,其中状态的子节点就是后继状态,就像普通搜索问题的搜索树一样:
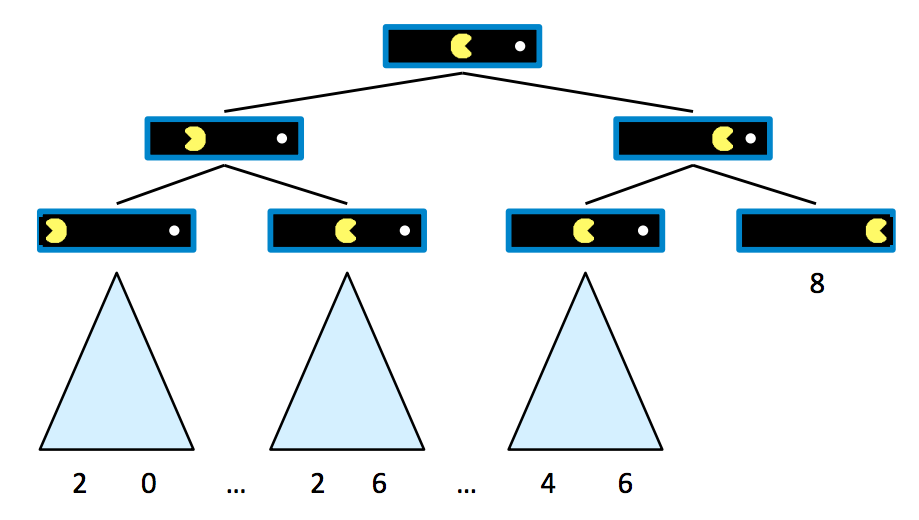
从这棵树可以明显看出,如果 Pacman 直接去吃豆子,他结束游戏时的分数为 8 分,而如果他在任何时候回头,他最终的分数会更低。现在我们已经生成了一个包含几个终止状态和中间状态的博弈树,我们准备形式化任何这些状态的值的含义。
一个状态的值定义为代理从该状态可以实现的最佳可能结果(utility,效用)。稍后我们将更具体地形式化效用的概念,但现在只需简单地将代理的效用视为其获得的分数或点数即可。终止状态的值,称为 terminal utility(终止效用),总是一个确定的已知值,也是游戏的固有属性。在我们的 Pacman 示例中,最右边的终止状态的值就是 8,即 Pacman 直接去吃豆子得到的分数。此外,在这个例子中,非终止状态的值定义为其子节点值的最大值。定义 \(V(s)\) 为定义状态 \(s\) 的值的函数,我们可以总结上面的讨论:
\[\forall \text{non-terminal states}, V(s) = \max_{s' \in \text{successors}(s)} V(s')\] \[\forall \text{terminal states}, V(s) = \text{known}\]这建立了一个非常简单的递归规则,从中可以理解根节点的直接右子节点的值将是 8,而根节点的直接左子节点的值将是 6,因为这些是代理如果分别从开始状态向右或向左移动所能获得的最大可能分数。由此可见,通过运行这样的计算,代理可以确定向右移动是最优的,因为右子节点的值大于开始状态的左子节点的值。
现在让我们引入一个新的游戏棋盘,上面有一个对抗性的幽灵,它想阻止 Pacman 吃到豆子。

游戏规则规定两个代理轮流行动,导致博弈树中两个代理在他们“控制”的树层上交替。代理控制一个节点仅仅意味着该节点对应于轮到该代理的状态,因此这是他们决定行动并相应地改变游戏状态的机会。这是由上面的新双代理游戏棋盘产生的博弈树:
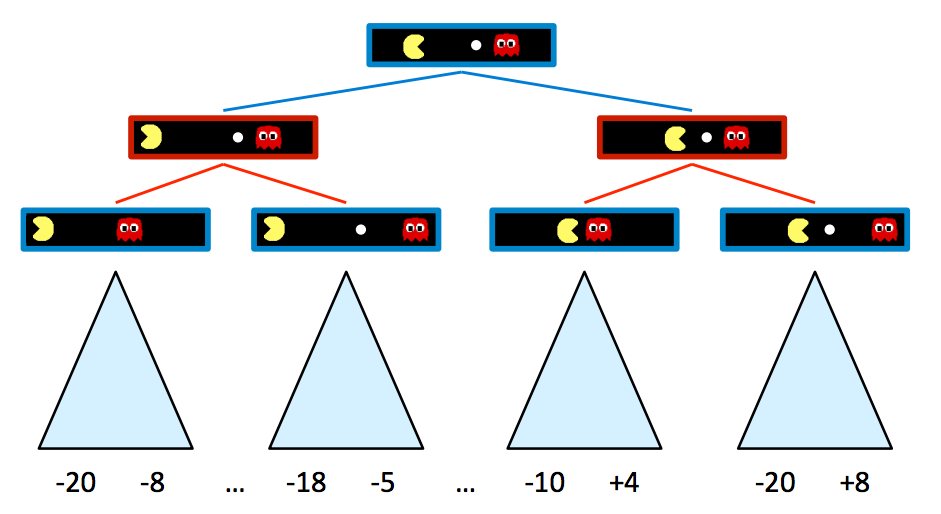
蓝色节点对应于 Pacman 控制的节点,可以决定采取什么行动,而红色节点对应于幽灵控制的节点。请注意,幽灵控制节点的所有子节点都是幽灵从其父节点状态向左或向右移动后的节点,反之亦然。为了简单起见,让我们将此博弈树截断为深度为 2 的树,并为终止状态分配伪造的值,如下所示:
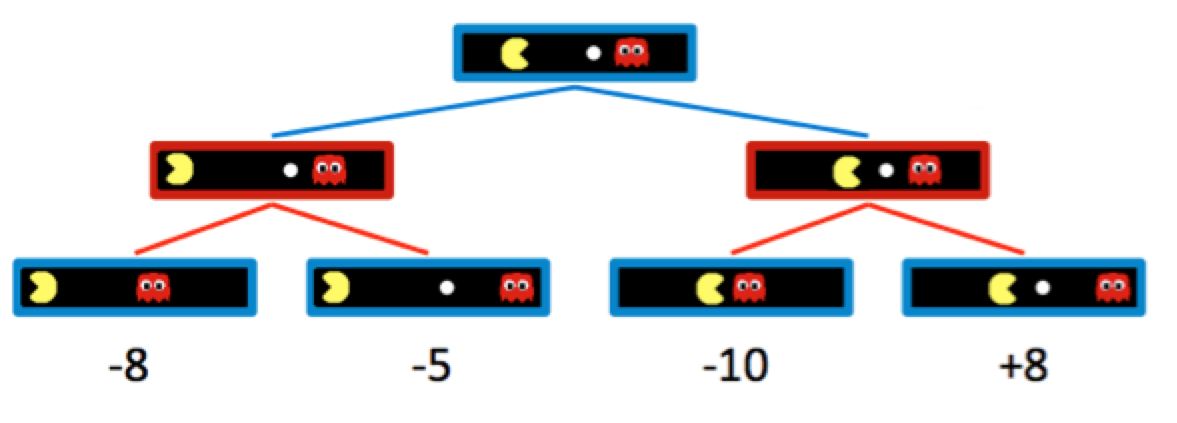
自然,增加幽灵控制的节点改变了 Pacman 认为最优的移动,新的最优移动由 minimax 算法确定。Minimax 算法不是在树的每一层最大化子节点的效用,而是只在 Pacman 控制的节点的子节点中最大化,而在幽灵控制的节点的子节点中最小化。因此,上面的两个幽灵节点的值分别为 \(\min(-8, -5) = -8\) 和 \(\min(-10, +8) = -10\)。相应地,由 Pacman 控制的根节点的值为 \(\max(-8, -10) = -8\)。因为 Pacman 想要最大化他的分数,他会向左走并获得 \(-8\) 的分数,而不是试图去吃豆子并获得 \(-10\) 分。这是通过计算产生行为的一个典型例子——虽然 Pacman 想要如果他最终到达最右边的子状态可以获得的 \(+8\) 分,但通过 minimax 他“知道”一个表现最优的幽灵不会允许他得到它。为了表现最优,Pacman 被迫对冲他的赌注,反直觉地远离豆子以最小化他失败的程度。我们可以将 minimax 为状态赋值的方式总结如下:
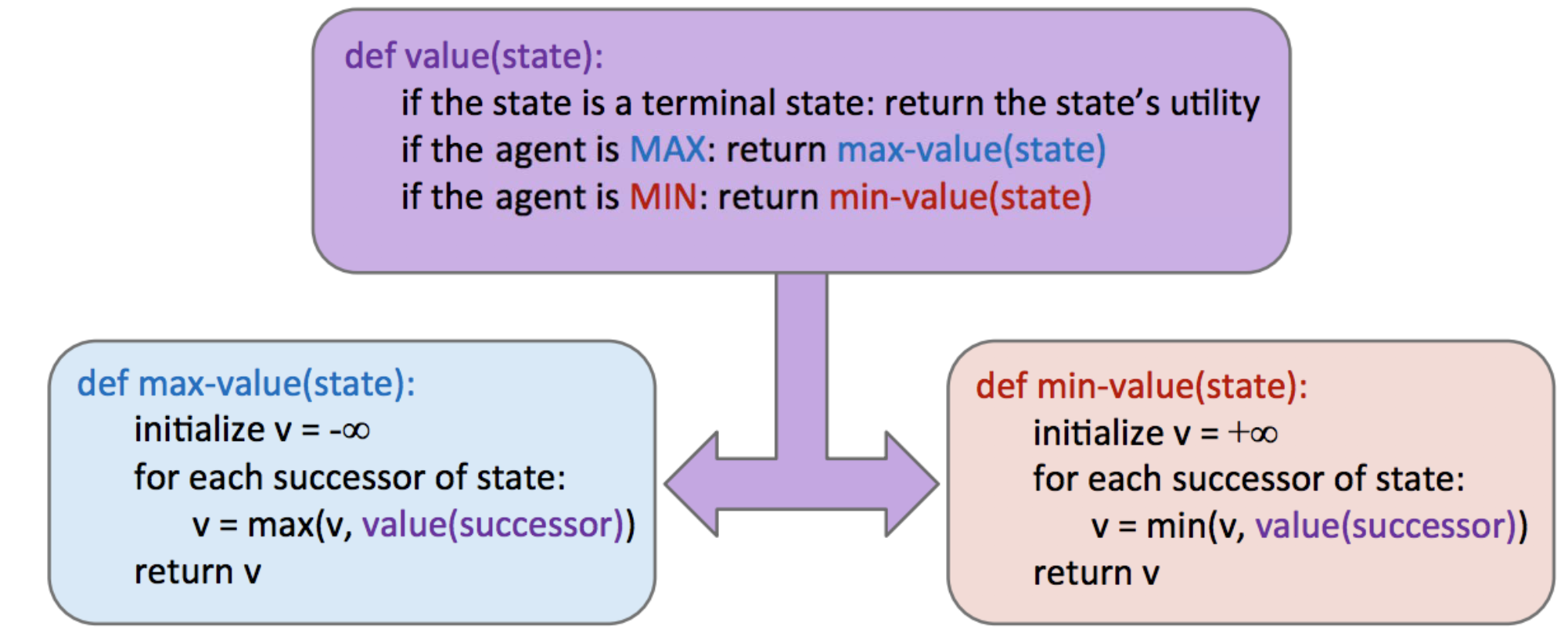
\[\forall \text{agent-controlled states}, V(s) = \max_{s'\in successors(s)} V(s')\] \[\forall \text{opponent-controlled states}, V(s) = \min_{s'\in successors(s)}V(s')\] \[\forall \text{terminal states}, V(s) = \text{known}\]在实现中,minimax 的行为类似于深度优先搜索 (DFS),以与 DFS 相同的顺序计算节点的值,从最左边的终止节点开始,通过迭代向右工作。更准确地说,它执行博弈树的 postorder traversal(后序遍历)。Minimax 的结果伪代码既优雅又直观简单,如下所示。请注意,minimax 将返回一个动作,该动作对应于根节点指向它取值的子节点的分支。
3.2.1 Alpha-Beta Pruning (Alpha-Beta 剪枝)
Minimax 看起来几乎完美——它简单、最优且直观。然而,它的执行与深度优先搜索非常相似,其时间复杂度是相同的,令人沮丧的 \(O(b^m)\)。回想一下,\(b\) 是分支因子,\(m\) 是可以找到终止节点的近似树深度,这对于许多游戏来说运行时间太长了。例如,国际象棋的分支因子 \(b \approx 35\),树深度 \(m \approx 100\)。为了帮助缓解这个问题,minimax 有一个优化——alpha-beta pruning(Alpha-Beta 剪枝)。
从概念上讲,alpha-beta 剪枝是这样的:如果你试图通过查看其后继节点来确定节点 \(n\) 的值,一旦你知道 \(n\) 的值充其量只能等于 \(n\) 的父节点的最优值,就停止查看。让我们通过一个例子来解开这个棘手的陈述意味着什么。考虑下面的博弈树,方形节点对应于终止状态,向下的三角形对应于最小化节点,向上的三角形对应于最大化节点:
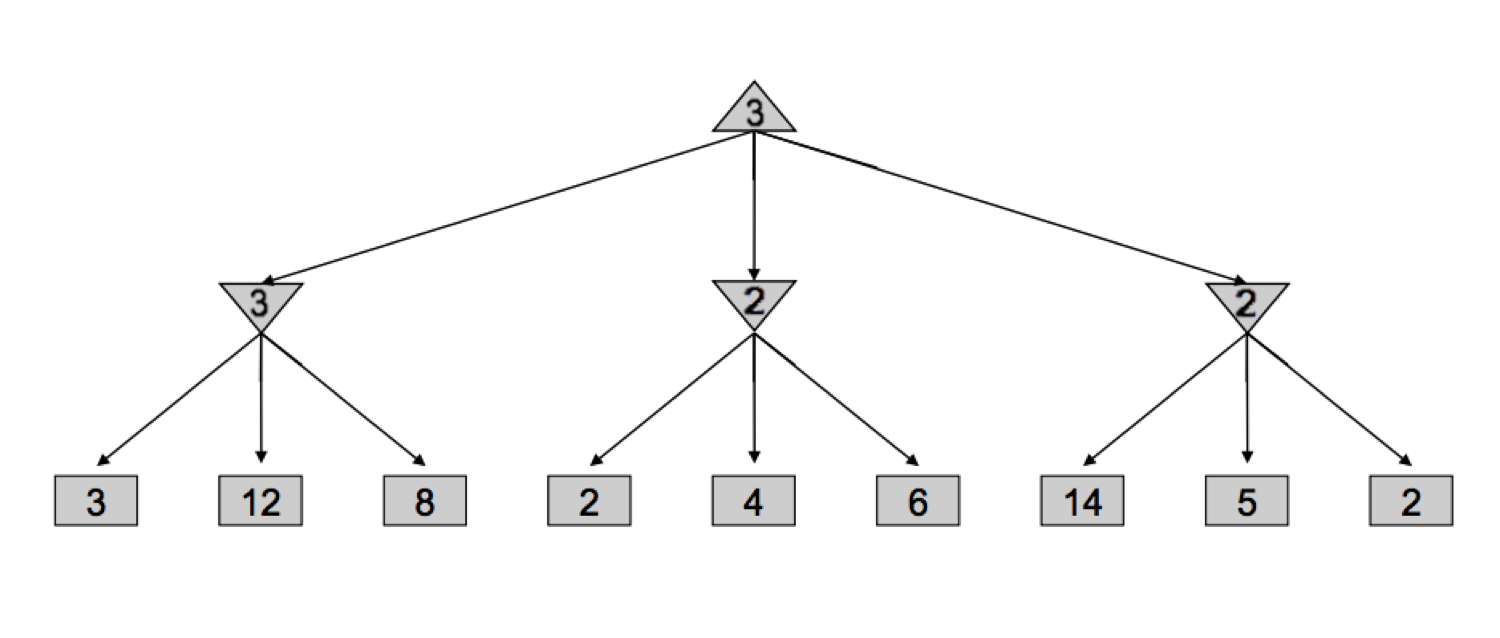
让我们通过 minimax 如何推导这棵树——它开始遍历值为 3、12 和 8 的节点,并将值 \(\min(3, 12, 8) = 3\) 分配给最左边的最小化器。然后,它将 \(\min(2, 4, 6) = 2\) 分配给中间的最小化器,将 \(\min(14, 5, 2) = 2\) 分配给最右边的最小化器,最后将 \(\max(3, 2, 2) = 3\) 分配给根部的最大化器。然而,如果我们思考这种情况,我们会意识到,一旦我们访问了中间最小化器的值为 \(2\) 的子节点,我们就不再需要查看中间最小化器的其他子节点了。为什么?因为我们已经看到了中间最小化器的一个值为 2 的子节点,我们知道无论其他子节点的值是多少,中间最小化器的值最多只能是 2。既然已经确定了这一点,让我们再想一步——根部的最大化器正在左边最小化器的值 3 和 \(\leq 2\) 的值之间做决定,它肯定会更喜欢左边最小化器返回的 3,而不是中间最小化器返回的值,无论其剩余子节点的值如何。这正是我们可以 prune(修剪)搜索树的原因,永远不再查看中间最小化器的剩余子节点:
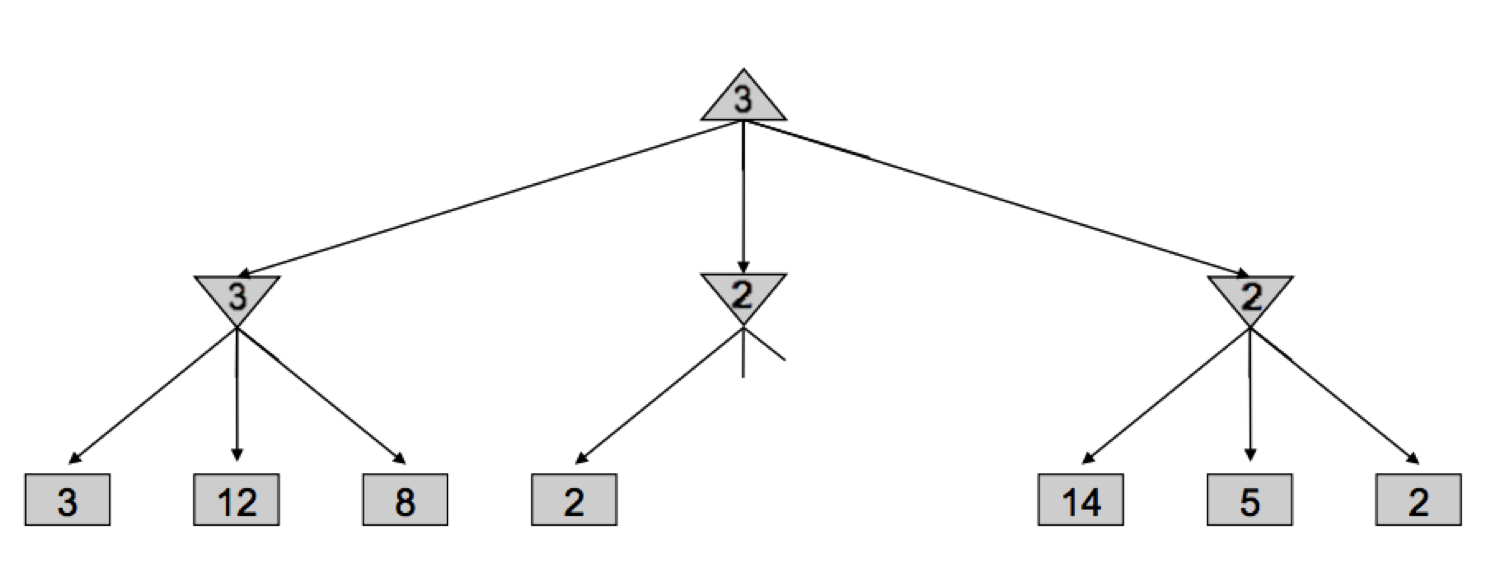
实现这种剪枝可以将我们的运行时间减少到 \(O(b^{m/2})\),有效地使我们的“可解”深度翻倍。在实践中,它通常要少得多,但通常可以使搜索至少再深一两层成为可能。这仍然非常重要,因为思考 3 步的玩家比思考 2 步的玩家更有可能获胜。这种剪枝正是带有 alpha-beta 剪枝的 minimax 算法所做的,实现如下:
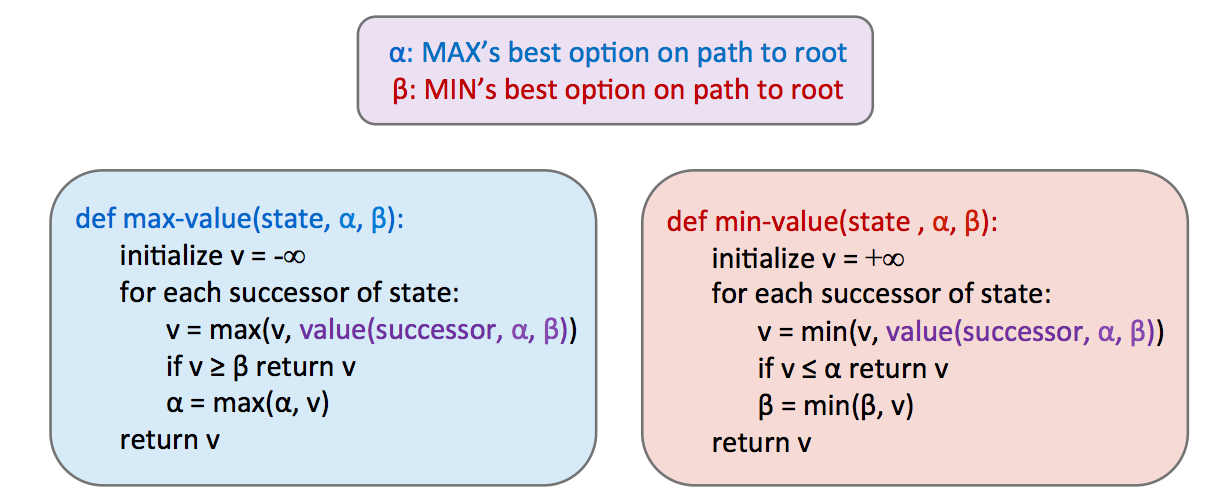
花点时间将其与普通 minimax 的伪代码进行比较,并注意我们现在可以提前返回,而无需搜索每个后继节点。
3.2.2 Evaluation Functions (评估函数)
虽然 alpha-beta 剪枝可以帮助增加我们可以可行地运行 minimax 的深度,但这通常仍然不足以到达大多数游戏搜索树的底部。因此,我们要通过 evaluation functions(评估函数),该函数接受一个状态并输出该节点真实 minimax 值的估计。通常,这被简单地解释为好的评估函数会将“更好”的状态分配比“更差”的状态更高的值。评估函数广泛用于 depth-limited minimax(深度受限 minimax),我们将位于最大可解深度的非终止节点视为终止节点,根据精心选择的评估函数为它们提供模拟终止效用。因为评估函数只能产生非终止效用值的估计,所以这消除了运行 minimax 时最优博弈的保证。
在设计运行 minimax 的代理时,通常会对评估函数的选择进行大量的思考和实验,评估函数越好,代理就越接近最优行为。此外,在使用评估函数之前深入树中也往往会给我们带来更好的结果——将计算埋在博弈树的更深处可以减轻对最优性的妥协。这些函数在游戏中的作用与启发式函数在标准搜索问题中的作用非常相似。
评估函数最常见的设计是 features(特征)的线性组合。
\[Eval(s) = w_1f_1(s) + w_2f_2(s) + ... + w_nf_n(s)\]每个 ( f_i(s) ) 对应于从输入状态 ( s ) 中提取的特征,每个特征被分配一个相应的 weight(权重)\(w_i\)。特征只是我们可以提取并分配数值的游戏状态的某些元素。例如,在跳棋游戏中,我们可以构建一个具有 4 个特征的评估函数:代理棋子数、代理王棋数、对手棋子数和对手王棋数。然后我们会根据它们的重要性大致选择合适的权重。在我们的跳棋示例中,为我们的代理的棋子/王棋选择正权重,为对手的棋子/王棋选择负权重是最合理的。此外,我们可能会决定,因为王棋在跳棋中比普通棋子更有价值,所以对应于我们代理/对手王棋的特征应该比关于普通棋子的特征具有更大幅度的权重。下面是一个符合我们刚刚头脑风暴的特征和权重的可能的评估函数:
\[Eval(s) = 2 \cdot agent\_kings(s) + agent\_pawns(s) - 2 \cdot opponent\_kings(s) - opponent\_pawns(s)\]正如你所看到的,评估函数的设计可以非常自由,也不一定非要是线性函数。例如,基于神经网络的非线性评估函数在强化学习应用中非常常见。最重要的是要记住,评估函数应尽可能频繁地为更好的位置产生更高的分数。这可能需要对使用具有多种不同特征和权重的评估函数的代理的性能进行大量的微调和实验。