5.2 Aprendizaje basado en modelos
En el aprendizaje basado en modelos, un agente genera una aproximación de la función de transición, \(\hat{T}(s, a, s')\), manteniendo recuentos del número de veces que llega a cada estado \(s'\) después de ingresar a cada estado Q \((s, a)\). Luego, el agente puede generar la función de transición aproximada \(\hat{T}\) a pedido normalizando los recuentos que ha recopilado: dividiendo el recuento de cada tupla observada \((s, a, s')\) por la suma de los recuentos de todas las instancias en las que el agente estaba en el estado Q \((s, a)\). La normalización de los recuentos los escala de tal manera que suman uno, lo que permite interpretarlos como probabilidades.
Considere el siguiente ejemplo de MDP con estados \(S = \{A, B, C, D, E, x\}\), con \(x\) representando el estado terminal, y factor de descuento \(\gamma = 1\):
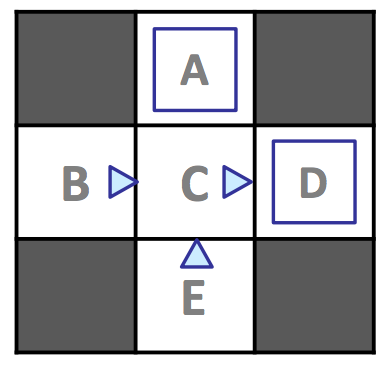
Supongamos que permitimos que nuestro agente explore el MDP durante cuatro episodios bajo la política \(\pi_{explore}\) delineada anteriormente (un triángulo direccional indica movimiento en la dirección que apunta el triángulo, y un cuadrado azul representa tomar exit como la acción de elección), produciendo los siguientes resultados:

Ahora tenemos un colectivo de 12 muestras, 3 de cada episodio con recuentos de la siguiente manera:
| \(s\) | \(a\) | \(s'\) | \(count\) |
|---|---|---|---|
| \(A\) | \(exit\) | \(x\) | 1 |
| \(B\) | \(east\) | \(C\) | 2 |
| \(C\) | \(east\) | \(A\) | 1 |
| \(C\) | \(east\) | \(D\) | 3 |
| \(D\) | \(exit\) | \(x\) | 3 |
| \(E\) | \(north\) | \(C\) | 2 |
| Recordando que $$T(s, a, s’) = P(s’ | a, s)\(, podemos estimar la función de transición con estos recuentos dividiendo los recuentos para cada tupla\)(s, a, s’)\(por el número total de veces que estuvimos en el estado Q\)(s, a)$$, y la función de recompensa directamente de las recompensas que obtuvimos durante la exploración: |
Función de Transición: \(\hat{T}(s, a, s')\)
\[\hat{T}(A, exit, x) = \frac{\#(A, exit, x)}{\#(A, exit)} = \frac{1}{1} = 1\] \[\hat{T}(B, east, C) = \frac{\#(B, east, C)}{\#(B, east)} = \frac{2}{2} = 1\] \[\hat{T}(C, east, A) = \frac{\#(C, east, A)}{\#(C, east)} = \frac{1}{4} = 0.25\] \[\hat{T}(C, east, D) = \frac{\#(C, east, D)}{\#(C, east)} = \frac{3}{4} = 0.75\] \[\hat{T}(D, exit, x) = \frac{\#(D, exit, x)}{\#(D, exit)} = \frac{3}{3} = 1\] \[\hat{T}(E, north, C) = \frac{\#(E, north, C)}{\#(E, north)} = \frac{2}{2} = 1\]Función de Recompensa: \(\hat{R}(s, a, s')\)
\[\hat{R}(A, exit, x) = -10\] \[\hat{R}(B, east, C) = -1\] \[\hat{R}(C, east, A) = -1\] \[\hat{R}(C, east, D) = -1\] \[\hat{R}(D, exit, x) = +10\] \[\hat{R}(E, north, C) = -1\]Por la ley de los grandes números, a medida que recopilamos más y más muestras haciendo que nuestro agente experimente más episodios, nuestros modelos de \(\hat{T}\) y \(\hat{R}\) mejorarán, con \(\hat{T}\) convergiendo hacia \(T\) y \(\hat{R}\) adquiriendo conocimiento de recompensas previamente no descubiertas a medida que descubrimos nuevas tuplas \((s, a, s')\). Siempre que lo consideremos oportuno, podemos finalizar el entrenamiento de nuestro agente para generar una política \(\pi_{exploit}\) ejecutando la iteración de valor o política con nuestros modelos actuales para \(\hat{T}\) y \(\hat{R}\) y usar \(\pi_{exploit}\) para la explotación, haciendo que nuestro agente atraviese el MDP, tomando acciones que buscan la maximización de recompensas en lugar de buscar el aprendizaje.
Pronto discutiremos métodos sobre cómo asignar tiempo entre exploración y explotación de manera efectiva. El aprendizaje basado en modelos es muy simple e intuitivo pero notablemente efectivo, generando \(\hat{T}\) y \(\hat{R}\) con nada más que conteo y normalización. Sin embargo, puede ser costoso mantener recuentos para cada tupla \((s, a, s')\) vista, por lo que en la siguiente sección sobre aprendizaje libre de modelos, desarrollaremos métodos para evitar mantener recuentos por completo y evitar la sobrecarga de memoria requerida por el aprendizaje basado en modelos.