6.7 贝叶斯网络中的近似推理:采样 (Approximate Inference in Bayes Nets: Sampling)
概率推理的另一种方法是通过简单地计算样本来隐式计算我们查询的概率。这不会像 IBE 或变量消元那样产生精确的解决方案,但这种近似推理通常已经足够好了,特别是考虑到计算量的巨大节省。
例如,假设我们想计算 \(P(+t \mid +e)\)。如果我们有一台神奇的机器可以从我们的分布中生成样本,我们可以收集所有 \(E = +e\) 的样本,然后计算这些样本中 \(T = +t\) 的比例。我们就能够仅仅通过查看样本来计算我们想要的任何推理。让我们看看生成样本的一些不同方法。
6.7.1 先验采样 (Prior Sampling)
给定一个贝叶斯网络模型,我们可以很容易地编写一个模拟器。例如,考虑下面给出的仅具有两个变量 T 和 C 的简化模型的 CPT。
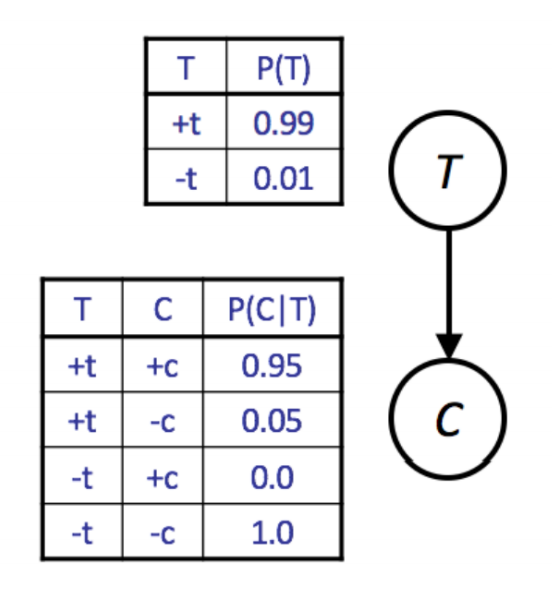
Python 中的一个简单模拟器如下所示:
import random
def get_t():
if random.random() < 0.99:
return True
return False
def get_c(t):
if t and random.random() < 0.95:
return True
return False
def get_sample():
t = get_t()
c = get_c(t)
return [t, c]
我们将这种简单的方法称为先验采样 (prior sampling)。这种方法的缺点是,为了对不太可能的情况进行分析,可能需要生成大量的样本。如果我们想计算 \(P(C \mid -t)\),我们将不得不丢弃 99% 的样本。
6.7.2 拒绝采样 (Rejection Sampling)
缓解上述问题的一种方法是修改我们的过程,提前拒绝任何与我们的证据不一致的样本。例如,对于查询 \(P(C \mid -t)\),除非 t 为假,否则我们避免为 C 生成值。这仍然意味着我们必须丢弃大部分样本,但至少我们生成的坏样本花费的时间更少。我们将这种方法称为拒绝采样 (rejection sampling)。
这两种方法之所以有效,原因相同:任何有效样本出现的概率与联合 PDF 中指定的概率相同。
6.7.3 似然加权 (Likelihood Weighting)
一种更奇特的方法是似然加权 (likelihood weighting),它确保我们永远不会生成坏样本。在这种方法中,我们手动将所有变量设置为等于我们查询中的证据。例如,如果我们想计算 \(P(C \mid -t)\),我们只需声明 \(t\) 为假。这里的问题是,这可能会产生与正确分布不一致的样本。
如果我们只是强制某些变量等于证据,那么我们的样本出现的概率仅等于非证据变量的 CPT 的乘积。这意味着联合 PDF 无法保证是正确的(尽管对于像我们的双变量贝叶斯网络这样的某些情况可能是正确的)。相反,如果我们有采样变量 \(Z_1\) 到 \(Z_p\) 和固定证据变量 \(E_1\) 到 \(E_m\),则样本由概率 \(P(Z_1 \ldots Z_p, E_1 \ldots E_m) = \prod_{i=1}^p P(Z_i \mid \text{Parents}(Z_i))\) 给出。缺少的是样本的概率不包括 \(P(E_i \mid \text{Parents}(E_i))\) 的所有概率,即并非每个 CPT 都参与。
似然加权通过为每个样本使用一个权重来解决这个问题,该权重是给定采样变量的证据变量的概率。也就是说,我们可以为样本 \(j\) 定义一个权重 \(w_j\),反映给定采样值时证据变量的观测值的可能性,而不是平等地计算所有样本。通过这种方式,我们确保每个 CPT 都参与。为此,我们遍历贝叶斯网络中的每个变量,就像我们进行正常采样一样,如果变量不是证据变量,则对值进行采样,或者如果变量是证据,则更改样本的权重。
例如,假设我们想计算 \(P(T \mid +c, +e)\)。对于第 \(j\) 个样本,我们将执行以下算法:
- 将 \(w_j\) 设置为 1.0,并且 \(c = \text{true}\) 和 \(e = \text{true}\)。
- 对于 \(T\):这不是证据变量,所以我们从 \(P(T)\) 中采样 \(t_j\)。
- 对于 \(C\):这是一个证据变量,所以我们将样本的权重乘以 \(P(+c \mid t_j)\),即 \(w_j = w_j \cdot P(+c \mid t_j)\)。
- 对于 \(S\):从 \(P(S \mid t_j)\) 中采样 \(s_j\)。
- 对于 \(E\):将样本的权重乘以 \(P(+e \mid +c, s_j)\),即 \(w_j = w_j \cdot P(+e \mid +c, s_j)\)。
然后当我们执行通常的计数过程时,我们用 \(w_j\) 而不是 1 对样本 \(j\) 进行加权,其中 \(0 \leq w_j \leq 1\)。这种方法之所以有效,是因为在概率的最终计算中,权重有效地用于替换缺失的 CPT。实际上,我们确保每个样本的加权概率由 \(P(z_1 \ldots z_p, e_1 \ldots e_m) = \left[\prod_{i=1}^p P(z_i \mid \text{Parents}(z_i))\right] \cdot \left[\prod_{i=1}^m P(e_i \mid \text{Parents}(e_i))\right]\) 给出。似然加权的伪代码如下所示。

对于我们所有的三种采样方法(先验采样、拒绝采样和似然加权),我们可以通过生成额外的样本来获得越来越高的准确性。然而,在这三种方法中,似然加权是计算效率最高的,原因超出了本课程的范围。
6.7.4 吉布斯采样 (Gibbs Sampling)
吉布斯采样 (Gibbs Sampling) 是第四种采样方法。在这种方法中,我们首先将所有变量设置为某个完全随机的值(不考虑任何 CPT)。然后我们重复地一次选择一个变量,清除它的值,并在给定当前分配给所有其他变量的值的情况下重新采样它。
对于上面的 \(T, C, S, E\) 示例,我们可能会分配 \(t = \text{true}\),\(c = \text{true}\),\(s = \text{false}\),和 \(e = \text{true}\)。然后我们选择我们的四个变量之一来重新采样,比如 \(S\),并清除它。然后我们从分布 \(P(S \mid +t, +c, +e)\) 中选择一个新变量。这需要我们知道这个条件分布。事实证明,我们可以很容易地计算给定所有其他变量的任何单个变量的分布。更具体地说,\(P(S \mid T, C, E)\) 只能使用连接 S 与其邻居的 CPT 来计算。因此,在一个典型的贝叶斯网络中,大多数变量只有少量的邻居,我们可以在线性时间内预先计算每个变量给定其所有邻居的条件分布。
我们不会证明这一点,但如果我们重复这个过程足够多次,我们后面的样本最终会收敛到正确的分布,即使我们可能从一个低概率的值分配开始。如果你好奇,有一些超出课程范围的注意事项,你可以在维基百科关于吉布斯采样的文章的失败模式部分阅读。
吉布斯采样的伪代码如下所示。
