4.3 Iteración de valor
Ahora que tenemos un marco para probar la optimalidad de los valores de los estados en un MDP, la pregunta de seguimiento natural es cómo calcular realmente estos valores óptimos. Para responder a esto, necesitamos valores de tiempo limitado (el resultado natural de imponer horizontes finitos). El valor de tiempo limitado para un estado \(s\) con un límite de tiempo de \(k\) pasos de tiempo se denota \(V_k(s)\), y representa la utilidad máxima esperada alcanzable desde \(s\) dado que el proceso de decisión de Markov bajo consideración termina en \(k\) pasos de tiempo. De manera equivalente, esto es lo que devuelve una ejecución expectimax de profundidad \(k\) en el árbol de búsqueda para un MDP.
La iteración de valor es un algoritmo de programación dinámica que utiliza un límite de tiempo iterativamente más largo para calcular valores de tiempo limitado hasta la convergencia (es decir, hasta que los valores \(V\) sean los mismos para cada estado que en la iteración anterior: \(\forall s, V_{k+1}(s) = V_{k}(s)\)). Funciona de la siguiente manera:
- \(\forall s \in S,\) inicialice \(V_0(s) = 0\). Esto debería ser intuitivo, ya que establecer un límite de tiempo de 0 pasos de tiempo significa que no se pueden tomar acciones antes de la terminación, por lo que no se pueden adquirir recompensas.
-
Repita la siguiente regla de actualización hasta la convergencia:
\[\forall s \in S, \:\: V_{k+1}(s) \leftarrow \max_a \sum_{s'}T(s, a, s')[R(s, a, s') + \gamma V_k(s')]\]En la iteración \(k\) de la iteración de valor, usamos los valores de tiempo limitado con límite \(k\) para cada estado para generar los valores de tiempo limitado con límite \((k+1)\). En esencia, usamos soluciones calculadas para subproblemas (todos los \(V_k(s)\)) para construir iterativamente soluciones para subproblemas más grandes (todos los \(V_{k+1}(s)\)); esto es lo que hace que la iteración de valor sea un algoritmo de programación dinámica.
Tenga en cuenta que aunque la ecuación de Bellman parece esencialmente idéntica a la regla de actualización anterior, no son lo mismo. La ecuación de Bellman da una condición para la optimalidad, mientras que la regla de actualización da un método para actualizar iterativamente los valores hasta la convergencia. Cuando se alcanza la convergencia, la ecuación de Bellman se mantendrá para cada estado: \(\forall s \in S, \:\: V_k(s) = V_{k+1}(s) = V^*(s)\).
Para mayor concisión, frecuentemente denotamos \(U_{k+1}(s) \leftarrow \max_a \sum_{s'}T(s, a, s')[R(s, a, s') + \gamma V_k(s')]\) con la abreviatura \(V_{k+1} \leftarrow BU_k\), donde \(B\) se llama el operador de Bellman. El operador de Bellman es una contracción por \(\gamma\). Para probar esto, necesitaremos la siguiente desigualdad general:
\[| \max_z f(z) - \max_z h(z) | \leq \max_z |f(z) - h(z)|.\]Ahora considere dos funciones de valor evaluadas en el mismo estado \(V(s)\) y \(V'(s)\). Mostramos que la actualización de Bellman \(B\) es una contracción por \(\gamma \in (0, 1)\) con respecto a la norma máxima de la siguiente manera:
\[\begin{aligned} &|BV(s) - BV'(s)| \\ &= \left| \left( \max_a \sum_{s'}T(s, a, s')[R(s, a, s') + \gamma V(s')] \right) - \left( \max_a \sum_{s'}T(s, a, s')[R(s, a, s') + \gamma V'(s')] \right) \right| \\ &\leq \max_a \left| \sum_{s'}T(s, a, s')[R(s, a, s') + \gamma V(s')] - \sum_{s'}T(s, a, s')[R(s, a, s') + \gamma V'(s')] \right| \\ &= \max_a \left| \gamma \sum_{s'}T(s, a, s')V(s') - \gamma \sum_{s'}T(s, a, s')V'(s') \right| \\ &= \gamma \max_a \left| \sum_{s'}T(s, a, s')(V(s') - V'(s')) \right| \\ &\leq \gamma \max_a \left| \sum_{s'}T(s, a, s') \max_{s'} \left| V(s') - V'(s') \right| \right| \\ &= \gamma \max_{s'} \left| V(s') - V'(s') \right| \\ &= \gamma ||V(s') - V'(s')||_{\infty}, \end{aligned}\]| donde la primera desigualdad se sigue de la desigualdad general introducida anteriormente, la segunda desigualdad se sigue de tomar el máximo de las diferencias entre \(V\) y \(V'\), y en el penúltimo paso, usamos el hecho de que las probabilidades suman 1 sin importar la elección de \(a\). El último paso utiliza la definición de la norma máxima para un vector \(x = (x_1, \ldots, x_n)\), que es $$ | x | _{\infty} = \max( | x_1 | , \ldots, | x_n | )$$. |
Debido a que acabamos de demostrar que la iteración de valor a través de actualizaciones de Bellman es una contracción en \(\gamma\), sabemos que la iteración de valor converge, y la convergencia ocurre cuando hemos alcanzado un punto fijo que satisface \(V^* = BU^*\).
Veamos algunas actualizaciones de la iteración de valor en la práctica revisando nuestro MDP de auto de carreras de antes, introduciendo un factor de descuento de \(\gamma = 0.5\):
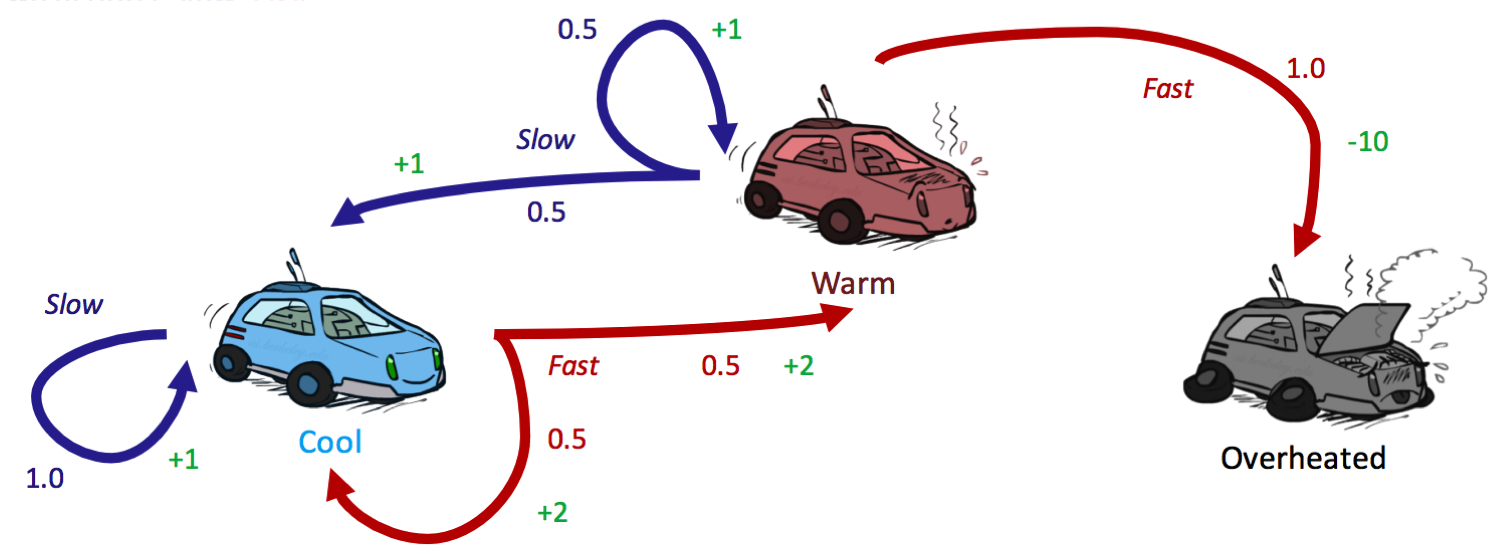
Comenzamos la iteración de valor inicializando todos \(V_0(s) = 0\):
| frío | tibio | sobrecalentado | |
|---|---|---|---|
| \(V_0\) | 0 | 0 | 0 |
En nuestra primera ronda de actualizaciones, podemos calcular \(\forall s \in S, \:\: V_1(s)\) de la siguiente manera:
\[\begin{aligned} V_1(frío) &= \max \{1 \cdot [1 + 0.5 \cdot 0],\:\: 0.5 \cdot [2 + 0.5 \cdot 0] + 0.5 \cdot [2 + 0.5 \cdot 0]\} \\ &= \max \{1, 2\} \\ &= \boxed{2} \\ V_1(tibio) &= \max \{0.5 \cdot [1 + 0.5 \cdot 0] + 0.5 \cdot [1 + 0.5 \cdot 0],\:\: 1 \cdot [-10 + 0.5 \cdot 0]\} \\ &= \max \{1, -10\} \\ &= \boxed{1} \\ V_1(sobrecalentado) &= \max \{\} \\ &= \boxed{0} \end{aligned}\]| frío | tibio | sobrecalentado | |
|---|---|---|---|
| \(U_0\) | 0 | 0 | 0 |
| \(U_1\) | 2 | 1 | 0 |
De manera similar, podemos repetir el procedimiento para calcular una segunda ronda de actualizaciones con nuestros nuevos valores para \(U_1(s)\) para calcular \(V_2(s)\):
\[\begin{aligned} V_2(frío) &= \max \{1 \cdot [1 + 0.5 \cdot 2],\:\: 0.5 \cdot [2 + 0.5 \cdot 2] + 0.5 \cdot [2 + 0.5 \cdot 1]\} \\ &= \max \{2, 2.75\} \\ &= \boxed{2.75} \\ V_2(tibio) &= \max \{0.5 \cdot [1 + 0.5 \cdot 2] + 0.5 \cdot [1 + 0.5 \cdot 1],\:\: 1 \cdot [-10 + 0.5 \cdot 0]\} \\ &= \max \{1.75, -10\} \\ &= \boxed{1.75} \\ V_2(sobrecalentado) &= \max \{\} \\ &= \boxed{0} \end{aligned}\]| frío | tibio | sobrecalentado | |
|---|---|---|---|
| \(V_0\) | 0 | 0 | 0 |
| \(V_1\) | 2 | 1 | 0 |
| \(V_2\) | 2.75 | 1.75 | 0 |
Vale la pena observar que \(V^*(s)\) para cualquier estado terminal debe ser 0, ya que nunca se pueden tomar acciones desde ningún estado terminal para obtener recompensas.
4.3.1 Extracción de políticas
Recuerde que nuestro objetivo final al resolver un MDP es determinar una política óptima. Esto se puede hacer una vez que se determinan todos los valores óptimos para los estados utilizando un método llamado extracción de políticas. La intuición detrás de la extracción de políticas es muy simple: si estás en un estado \(s\), debes tomar la acción \(a\) que produce la máxima utilidad esperada. No es sorprendente que \(a\) sea la acción que nos lleva al estado Q con el valor Q máximo, lo que permite una definición formal de la política óptima:
\[\forall s \in S, \:\: \pi^*(s) = \underset{a}{\operatorname{argmax}}\: Q^*(s, a) = \underset{a}{\operatorname{argmax}}\: \sum_{s'}T(s, a, s')[R(s, a, s') + \gamma V^*(s')]\]Es útil tener en cuenta por razones de rendimiento que es mejor para la extracción de políticas tener los valores Q óptimos de los estados, en cuyo caso una sola operación \(\operatorname{argmax}\) es todo lo que se requiere para determinar la acción óptima desde un estado. Almacenar solo cada \(V^*(s)\) significa que debemos volver a calcular todos los valores Q necesarios con la ecuación de Bellman antes de aplicar \(\operatorname{argmax}\), equivalente a realizar un expectimax de profundidad 1.
4.3.2 Iteración de valor Q
Al resolver una política óptima utilizando la iteración de valor, primero encontramos todos los valores óptimos, luego extraemos la política utilizando la extracción de políticas. Sin embargo, es posible que haya notado que también tratamos con otro tipo de valor que codifica información sobre la política óptima: valores Q.
La iteración de valor Q es un algoritmo de programación dinámica que calcula valores Q de tiempo limitado. Se describe en la siguiente ecuación:
\[Q_{k+1}(s, a) \leftarrow \sum_{s'}T(s, a, s')[R(s, a, s') + \gamma \max_{a'} Q_k(s', a')]\]Tenga en cuenta que esta actualización es solo una ligera modificación sobre la regla de actualización para la iteración de valor. De hecho, la única diferencia real es que la posición del operador \(\max\) sobre las acciones ha cambiado ya que seleccionamos una acción antes de la transición cuando estamos en un estado, pero hacemos la transición antes de seleccionar una nueva acción cuando estamos en un estado Q. Una vez que tenemos los valores Q óptimos para cada estado y acción, podemos encontrar la política para un estado simplemente eligiendo la acción que tiene el valor Q más alto.