4.4 策略迭代 (Policy Iteration)
| 值迭代可能相当慢。在每次迭代中,我们必须更新所有 $$ | S | \(个状态的值(其中\) | n | \(指的是基数运算符),当我们计算每个动作的 Q-值时,每个状态都需要遍历所有\) | A | \(个动作。而这些 Q-值中每一个的计算,反过来又需要再次遍历每个\) | S | \(状态,导致\)O( | S | ^2 | A | )$$ 的糟糕运行时间。此外,当我们只想确定 MDP 的最优策略时,值迭代往往会进行大量的过度计算,因为通过策略提取计算出的策略通常比值本身收敛得快得多。解决这些缺陷的方法是使用策略迭代 (policy iteration) 作为替代方案,这是一种在保持值迭代最优性的同时提供显著性能提升的算法。策略迭代的操作如下: |
- 定义一个初始策略。这可以是任意的,但初始策略越接近最终的最优策略,策略迭代收敛得越快。
- 重复以下步骤直到收敛:
- 使用策略评估 (policy evaluation) 评估当前策略。对于策略 \(\pi\),策略评估意味着计算所有状态 \(s\) 的 \(V^{\pi}(s)\),其中 \(V^{\pi}(s)\) 是遵循 \(\pi\) 时从状态 \(s\) 开始的期望效用: \(V^{\pi}(s) = \sum_{s'}T(s, \pi(s), s')[R(s, \pi(s), s') + \gamma V^{\pi}(s')]\) 将策略迭代第 \(i\) 次迭代的策略定义为 \(\pi_i\)。由于我们为每个状态固定了一个动作,我们不再需要 \(\max\) 算子,这实际上给我们留下了由上述规则生成的 \(|S|\) 个方程的系统。然后可以通过简单地求解该系统来计算每个 \(V^{\pi_i}(s)\)。 或者,我们也可以像在值迭代中一样,使用以下更新规则直到收敛来计算 \(V^{\pi_i}(s)\): \(V^{\pi_i}_{k+1}(s) \leftarrow \sum_{s'}T(s, \pi_i(s), s')[R(s, \pi_i(s), s') + \gamma V^{\pi_i}_k(s')]\) 然而,这种第二种方法在实践中通常较慢。
- 一旦我们评估了当前策略,使用策略改进 (policy improvement) 来生成更好的策略。策略改进使用策略评估生成的状态值的策略提取来生成这个新的和改进的策略: \(\pi_{i+1}(s) = \underset{a}{\operatorname{argmax}}\: \sum_{s'}T(s, a, s')[R(s, a, s') + \gamma V^{\pi_i}(s')]\) 如果 \(\pi_{i+1} = \pi_i\),则算法已收敛,我们可以得出结论 \(\pi_{i+1} = \pi_i = \pi^*\)。
让我们最后一次通过我们的赛车示例(还没厌倦吗?),看看使用策略迭代是否得到与值迭代相同的策略。回想一下,我们使用的折扣因子为 \(\gamma = 0.5\)。
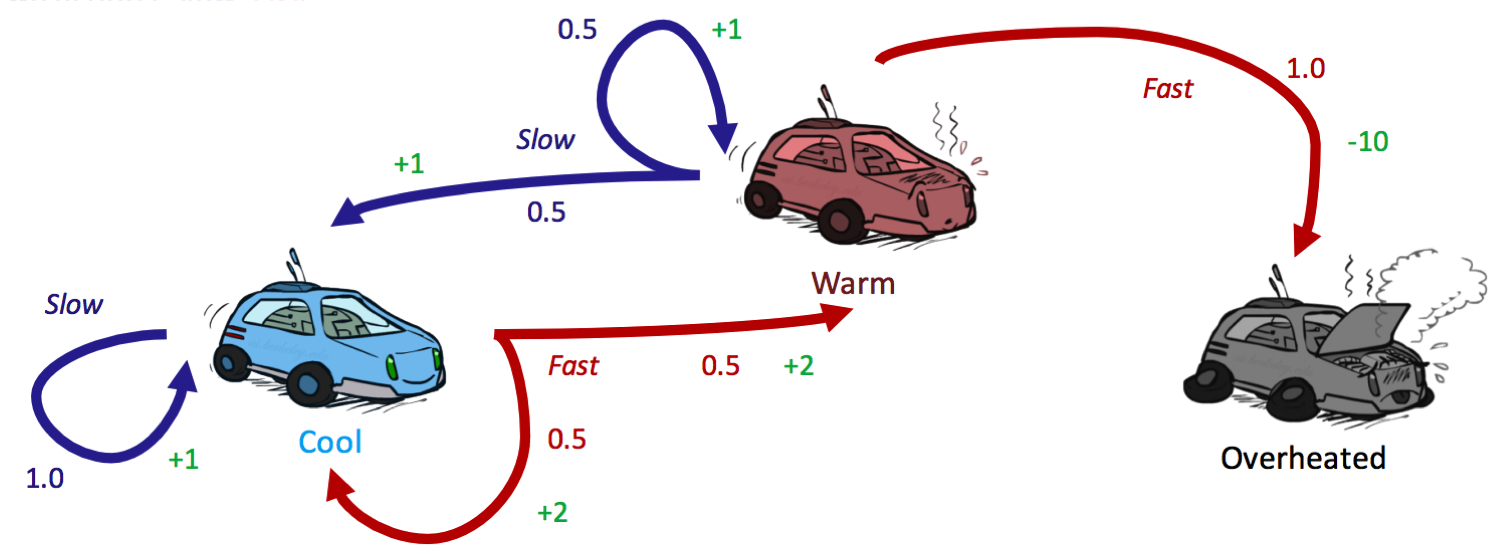
我们从总是慢行的初始策略开始:
| cool | warm | overheated | |
|---|---|---|---|
| \(\pi_0\) | slow | slow | — |
因为终止状态没有外出的动作,所以没有策略可以为终止状态赋值。因此,像我们所做的那样不考虑状态 overheated 是合理的,并且简单地为任何终止状态 \(s\) 分配 \(\forall i, \:\: V^{\pi_i}(s) = 0\)。下一步是对 \(\pi_0\) 运行一轮策略评估:
\[\begin{aligned} V^{\pi_0}(cool) &= 1 \cdot [1 + 0.5 \cdot V^{\pi_0}(cool)] \\ V^{\pi_0}(warm) &= 0.5 \cdot [1 + 0.5 \cdot V^{\pi_0}(cool)] \\ &+ 0.5 \cdot [1 + 0.5 \cdot V^{\pi_0}(warm)] \end{aligned}\]求解 \(V^{\pi_0}(cool)\) 和 \(V^{\pi_0}(warm)\) 的这个方程组得出:
| cool | warm | overheated | |
|---|---|---|---|
| \(V^{\pi_0}\) | 2 | 2 | 0 |
我们现在可以使用这些值运行策略提取:
\[\begin{aligned} \pi_{1}(cool) &= {\operatorname{argmax}}\{slow: 1 \cdot [1 + 0.5 \cdot 2],\:\: fast: 0.5 \cdot [2 + 0.5 \cdot 2] + 0.5 \cdot [2 + 0.5 \cdot 2]\} \\ &= {\operatorname{argmax}}\{slow: 2,\:\: fast: 3\} \\ &= \boxed{fast}\\ \pi_{1}(warm) &= {\operatorname{argmax}}\{slow: 0.5 \cdot [1 + 0.5 \cdot 2] + 0.5 \cdot [1 + 0.5 \cdot 2] ,\:\: fast: 1 \cdot [-10 + 0.5 \cdot 0]\} \\ &= {\operatorname{argmax}}\{slow: 2,\:\: fast: -10\} \\ &= \boxed{slow} \end{aligned}\]运行第二轮策略迭代得出 \(\pi_2(cool) = fast\) 和 \(\pi_2(warm) = slow\)。由于这与 \(\pi_1\) 是相同的策略,我们可以得出结论 \(\pi_1 = \pi_2 = \pi^*\)。为了练习,请验证这一点!
| cool | warm | |
|---|---|---|
| \(\pi_0\) | slow | slow |
| \(\pi_1\) | fast | slow |
| \(\pi_2\) | fast | slow |
这个例子展示了策略迭代的真正威力:仅仅两次迭代,我们就已经达到了赛车 MDP 的最优策略!这比我们在同一个 MDP 上运行值迭代时所能说的要多,值迭代在我们执行两次更新后距离收敛还有几次迭代。