5.3 Aprendizaje libre de modelos
¡Adelante con el aprendizaje libre de modelos! Hay varios algoritmos de aprendizaje libre de modelos, y cubriremos tres de ellos: evaluación directa, aprendizaje por diferencia temporal y Q-learning. La evaluación directa y el aprendizaje por diferencia temporal caen bajo una clase de algoritmos conocidos como aprendizaje por refuerzo pasivo. En el aprendizaje por refuerzo pasivo, a un agente se le da una política a seguir y aprende el valor de los estados bajo esa política a medida que experimenta episodios, que es exactamente lo que hace la evaluación de políticas para los MDP cuando se conocen \(T\) y \(R\). Q-learning cae bajo una segunda clase de algoritmos de aprendizaje libre de modelos conocidos como aprendizaje por refuerzo activo, durante el cual el agente de aprendizaje puede usar la retroalimentación que recibe para actualizar iterativamente su política mientras aprende hasta que finalmente determina la política óptima después de suficiente exploración.
5.3.1 Evaluación directa
La primera técnica de aprendizaje por refuerzo pasivo que cubriremos se conoce como evaluación directa, un método que es tan aburrido y simple como su nombre lo indica. Todo lo que hace la evaluación directa es fijar alguna política \(\pi\) y hacer que el agente experimente varios episodios mientras sigue \(\pi\). A medida que el agente recopila muestras a través de estos episodios, mantiene recuentos de la utilidad total obtenida de cada estado y el número de veces que visitó cada estado. En cualquier momento, podemos calcular el valor estimado de cualquier estado \(s\) dividiendo la utilidad total obtenida de \(s\) por el número de veces que se visitó \(s\). Ejecutemos una evaluación directa en nuestro ejemplo anterior, recordando que \(\gamma = 1\).
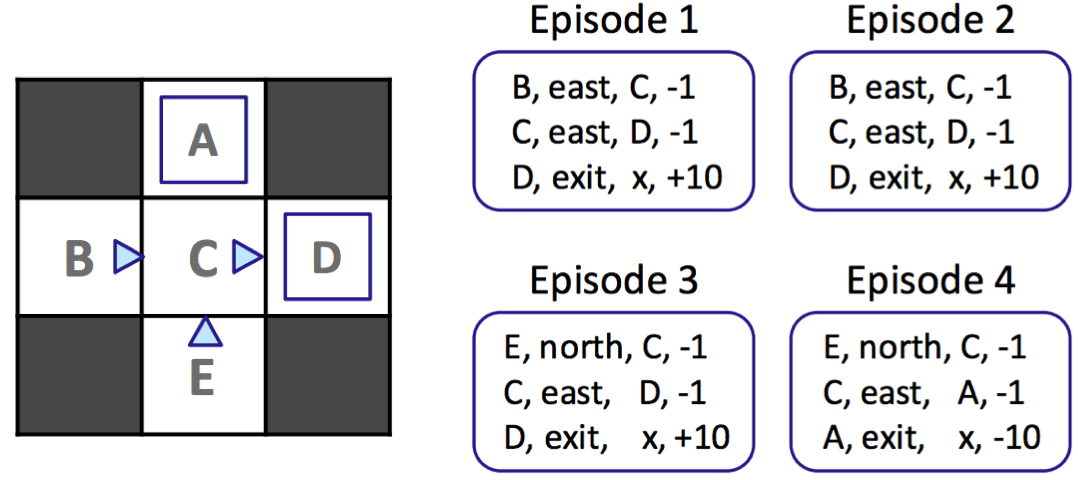
Caminando a través del primer episodio, podemos ver que desde el estado \(D\) hasta la terminación adquirimos una recompensa total de \(10\), desde el estado \(C\) adquirimos una recompensa total de \((-1) + 10 = 9\), y desde el estado \(B\) adquirimos una recompensa total de \((-1) + (-1) + 10 = 8\). Completar este proceso produce la recompensa total a través de los episodios para cada estado y los valores estimados resultantes de la siguiente manera:
| \(\mathbf{s}\) | \(\mathbf{Recompensa\ Total}\) | \(\mathbf{Veces\ Visitado}\) | \(\mathbf{V^{\pi}(s)}\) |
|---|---|---|---|
| \(A\) | \(-10\) | \(1\) | \(-10\) |
| \(B\) | \(16\) | \(2\) | \(8\) |
| \(C\) | \(16\) | \(4\) | \(4\) |
| \(D\) | \(30\) | \(3\) | \(10\) |
| \(E\) | \(-4\) | \(2\) | \(-2\) |
Aunque la evaluación directa finalmente aprende los valores de estado para cada estado, a menudo es innecesariamente lenta para converger porque desperdicia información sobre las transiciones entre estados.
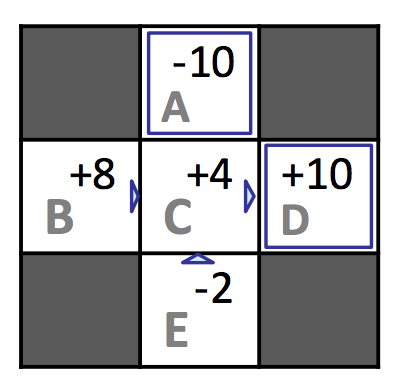
En nuestro ejemplo, calculamos \(V^{\pi}(E) = -2\) y \(V^{\pi}(B) = 8\), aunque según la retroalimentación que recibimos, ambos estados solo tienen \(C\) como estado sucesor e incurren en la misma recompensa de \(-1\) al hacer la transición a \(C\). Según la ecuación de Bellman, esto significa que tanto \(B\) como \(E\) deberían tener el mismo valor bajo \(\pi\). Sin embargo, de las 4 veces que nuestro agente estuvo en el estado \(C\), hizo la transición a \(D\) y obtuvo una recompensa de \(10\) tres veces e hizo la transición a \(A\) y obtuvo una recompensa de \(-10\) una vez. Fue pura casualidad que la única vez que recibió la recompensa de \(-10\) comenzó en el estado \(E\) en lugar de \(B\), pero esto sesgó gravemente el valor estimado para \(E\). Con suficientes episodios, los valores para \(B\) y \(E\) convergerán a sus valores verdaderos, pero casos como este hacen que el proceso tome más tiempo del que nos gustaría. Este problema se puede mitigar eligiendo usar nuestro segundo algoritmo de aprendizaje por refuerzo pasivo, el aprendizaje por diferencia temporal.
5.3.2 Aprendizaje por diferencia temporal
El aprendizaje por diferencia temporal (aprendizaje TD) utiliza la idea de aprender de cada experiencia, en lugar de simplemente realizar un seguimiento de las recompensas totales y la cantidad de veces que se visitan los estados y aprender al final como lo hace la evaluación directa. En la evaluación de políticas, usamos el sistema de ecuaciones generado por nuestra política fija y la ecuación de Bellman para determinar los valores de los estados bajo esa política (o usamos actualizaciones iterativas como con la iteración de valor).
\[V^{\pi}(s) = \sum_{s'}T(s, \pi(s), s')[R(s, \pi(s), s') + \gamma V^{\pi}(s')]\]Cada una de estas ecuaciones iguala el valor de un estado al promedio ponderado sobre los valores descontados de los sucesores de ese estado más las recompensas obtenidas al hacer la transición a ellos. El aprendizaje TD intenta responder a la pregunta de cómo calcular este promedio ponderado sin los pesos, haciéndolo inteligentemente con un promedio móvil exponencial. Comenzamos inicializando \(\forall s, \:\: V^{\pi}(s) = 0\). En cada paso de tiempo, un agente toma una acción \(\pi(s)\) desde un estado \(s\), hace la transición a un estado \(s'\), y recibe una recompensa \(R(s, \pi(s), s')\). Podemos obtener un valor de muestra sumando la recompensa recibida con el valor actual descontado de \(s'\) bajo \(\pi\):
\[\text{muestra} = R(s, \pi(s), s') + \gamma V^{\pi}(s')\]Esta muestra es una nueva estimación para \(V^{\pi}(s)\). El siguiente paso es incorporar esta estimación muestreada en nuestro modelo existente para \(V^{\pi}(s)\) con el promedio móvil exponencial, que se adhiere a la siguiente regla de actualización:
\[V^{\pi}(s) \leftarrow (1-\alpha)V^{\pi}(s) + \alpha \cdot \text{muestra}\]Arriba, \(\alpha\) es un parámetro restringido por \(0 \leq \alpha \leq 1\) conocido como la tasa de aprendizaje que especifica el peso que queremos asignar a nuestro modelo existente para \(V^{\pi}(s)\), \(1 - \alpha\), y el peso que queremos asignar a nuestra nueva estimación muestreada, \(\alpha\). Es típico comenzar con una tasa de aprendizaje de \(\alpha = 1\), asignando en consecuencia \(V^{\pi}(s)\) a lo que sea la primera \(\text{muestra}\), y reduciéndola lentamente hacia 0, momento en el cual todas las muestras posteriores se pondrán a cero y dejarán de afectar nuestro modelo de \(V^{\pi}(s)\).
Detengámonos y analicemos la regla de actualización por un minuto. Anotando el estado de nuestro modelo en diferentes puntos en el tiempo definiendo \(V^{\pi}_k(s)\) y \(\text{muestra}_k\) como el valor estimado del estado \(s\) después de la \(k\)-ésima actualización y la \(k\)-ésima muestra respectivamente, podemos volver a expresar nuestra regla de actualización:
\[V^{\pi}_{k}(s) \leftarrow (1-\alpha)V^{\pi}_{k-1}(s) + \alpha \cdot \text{muestra}_k\]Esta definición recursiva para \(V^{\pi}_k(s)\) resulta ser muy interesante de expandir:
\[V^{\pi}_{k}(s) \leftarrow \alpha \cdot [(1-\alpha)^{k-1} \cdot \text{muestra}_1 + ... + (1-\alpha) \cdot \text{muestra}_{k-1} + \text{muestra}_k]\]Debido a que \(0 \leq (1 - \alpha) \leq 1\), a medida que elevamos la cantidad \((1 - \alpha)\) a potencias cada vez mayores, se acerca cada vez más a 0. Por la expansión de la regla de actualización que derivamos, esto significa que a las muestras más antiguas se les da exponencialmente menos peso, ¡exactamente lo que queremos ya que estas muestras más antiguas se calculan utilizando versiones más antiguas (y por lo tanto peores) de nuestro modelo para \(V^{\pi}(s)\)! Esta es la belleza del aprendizaje por diferencia temporal: con una sola regla de actualización sencilla, podemos:
- Aprender en cada paso de tiempo, por lo tanto, usar información sobre las transiciones de estado a medida que las obtenemos, ya que estamos usando versiones actualizadas iterativamente de \(V^{\pi}(s')\) en nuestras muestras en lugar de esperar hasta el final para realizar cualquier cálculo.
- Dar exponencialmente menos peso a muestras más antiguas y potencialmente menos precisas.
- Converger al aprendizaje de valores de estado verdaderos mucho más rápido con menos episodios que la evaluación directa.
5.3.3 Q-Learning
Tanto la evaluación directa como el aprendizaje TD finalmente aprenderán el valor verdadero de todos los estados bajo la política que siguen. Sin embargo, ambos tienen un problema inherente importante: queremos encontrar una política óptima para nuestro agente, lo que requiere conocimiento de los valores Q de los estados. Para calcular los valores Q a partir de los valores que tenemos, requerimos una función de transición y una función de recompensa según lo dictado por la ecuación de Bellman.
\[Q^*(s, a) = \sum_{s'} T(s, a, s')[R(s, a, s') + \gamma V^*(s')]\]Como resultado, el aprendizaje TD o la evaluación directa se utilizan típicamente junto con algún aprendizaje basado en modelos para adquirir estimaciones de \(T\) y \(R\) con el fin de actualizar eficazmente la política seguida por el agente de aprendizaje. Esto se volvió evitable mediante una idea nueva y revolucionaria conocida como Q-learning, que propuso aprender los valores Q de los estados directamente, evitando la necesidad de conocer valores, funciones de transición o funciones de recompensa. Como resultado, Q-learning es completamente libre de modelos. Q-learning utiliza la siguiente regla de actualización para realizar lo que se conoce como iteración de valor Q:
\[Q_{k+1}(s, a) \leftarrow \sum_{s'}T(s, a, s')[R(s, a, s') + \gamma \max_{a'} Q_k(s', a')]\]Tenga en cuenta que esta actualización es solo una ligera modificación sobre la regla de actualización para la iteración de valor. De hecho, la única diferencia real es que la posición del operador \(\max\) sobre las acciones ha cambiado ya que seleccionamos una acción antes de la transición cuando estamos en un estado, pero hacemos la transición antes de seleccionar una nueva acción cuando estamos en un estado Q.
Con esta nueva regla de actualización en nuestro haber, Q-learning se deriva esencialmente de la misma manera que el aprendizaje TD, adquiriendo muestras de valor Q:
\[\text{muestra} = R(s, a, s') + \gamma \max_{a'}Q(s', a')\]e incorporándolas en un promedio móvil exponencial.
\[Q(s, a) \leftarrow (1-\alpha)Q(s, a) + \alpha \cdot \text{muestra}\]Siempre que pasemos suficiente tiempo en exploración y disminuyamos la tasa de aprendizaje \(\alpha\) a un ritmo apropiado, Q-learning aprende los valores Q óptimos para cada estado Q. Esto es lo que hace que Q-learning sea tan revolucionario: mientras que el aprendizaje TD y la evaluación directa aprenden los valores de los estados bajo una política siguiendo la política antes de determinar la optimalidad de la política a través de otras técnicas, Q-learning puede aprender la política óptima directamente incluso tomando acciones subóptimas o aleatorias. Esto se llama aprendizaje fuera de política (contrario a la evaluación directa y el aprendizaje TD, que son ejemplos de aprendizaje en política).
5.3.4 Q-Learning aproximado
Q-learning es una técnica de aprendizaje increíble que continúa estando en el centro de los desarrollos en el campo del aprendizaje por refuerzo. Sin embargo, todavía tiene margen de mejora. Tal como está, Q-learning simplemente almacena todos los valores Q para los estados en forma tabular, lo cual no es particularmente eficiente dado que la mayoría de las aplicaciones de aprendizaje por refuerzo tienen varios miles o incluso millones de estados. Esto significa que no podemos visitar todos los estados durante el entrenamiento y no podemos almacenar todos los valores Q incluso si pudiéramos por falta de memoria.



Arriba, si Pacman aprendiera que la Figura 1 es desfavorable después de ejecutar Q-learning vainilla, todavía no tendría idea de que la Figura 2 o incluso la Figura 3 también son desfavorables. Q-learning aproximado intenta dar cuenta de esto aprendiendo sobre algunas situaciones generales y extrapolando a muchas situaciones similares. La clave para generalizar las experiencias de aprendizaje es la representación basada en características de los estados, que representa cada estado como un vector conocido como vector de características. Por ejemplo, un vector de características para Pacman puede codificar:
- la distancia al fantasma más cercano.
- la distancia a la bolita de comida más cercana.
- el número de fantasmas.
- ¿está Pacman atrapado? 0 o 1.
Con vectores de características, podemos tratar los valores de los estados y los estados Q como funciones de valor lineal:
\[V(s) = w_1 \cdot f_1(s) + w_2 \cdot f_2(s) + ... + w_n \cdot f_n(s) = \vec{w} \cdot \vec{f}(s)\] \[Q(s, a) = w_1 \cdot f_1(s, a) + w_2 \cdot f_2(s, a) + ... + w_n \cdot f_n(s, a) = \vec{w} \cdot \vec{f}(s, a)\]donde
\[\vec{f}(s) = \begin{bmatrix}f_1(s)&f_2(s)&...&f_n(s)\end{bmatrix}^T\]y
\[\vec{f}(s, a) = \begin{bmatrix}f_1(s, a)&f_2(s, a)&...&f_n(s, a)\end{bmatrix}^T\]representan los vectores de características para el estado \(s\) y el estado Q \((s, a)\) respectivamente y \(\vec{w} = \begin{bmatrix}w_1&w_2&...&w_n\end{bmatrix}\) representa un vector de pesos. Definiendo diferencia como
\[\text{diferencia} = [R(s, a, s') + \gamma \max_{a'}Q(s', a')] - Q(s, a)\]Q-learning aproximado funciona casi idénticamente a Q-learning, utilizando la siguiente regla de actualización:
\[w_i \leftarrow w_i + \alpha \cdot \text{diferencia} \cdot f_i(s, a)\]En lugar de almacenar valores Q para todos y cada uno de los estados, con Q-learning aproximado solo necesitamos almacenar un solo vector de pesos y podemos calcular valores Q bajo demanda según sea necesario. Como resultado, esto nos da no solo una versión más generalizada de Q-learning, sino también una significativamente más eficiente en memoria.
Como nota final sobre Q-learning, podemos volver a expresar la regla de actualización para Q-learning exacto usando diferencia de la siguiente manera:
\[Q(s, a) \leftarrow Q(s, a) + \alpha \cdot \text{diferencia}\]Esta segunda notación nos da una interpretación ligeramente diferente pero igualmente valiosa de la actualización: está calculando la diferencia entre la estimación muestreada y el modelo actual de \(Q(s, a)\), y desplazando el modelo en la dirección de la estimación con la magnitud del desplazamiento siendo proporcional a la magnitud de la diferencia.