5.1 强化学习 (Reinforcement Learning)
在之前的笔记中,我们讨论了马尔可夫决策过程,我们使用值迭代和策略迭代等技术来计算状态的最优值并提取最优策略。解决马尔可夫决策过程是离线规划 (offline planning) 的一个例子,其中代理完全了解转移函数和奖励函数,这是它们在 MDP 编码的世界中预先计算最优动作所需的所有信息,而无需实际采取任何动作。
在本笔记中,我们将讨论在线规划 (online planning),在此期间,代理对世界中的奖励或转移(仍表示为 MDP)没有先验知识。在在线规划中,代理必须尝试探索 (exploration),在此期间它执行动作并以它到达的后继状态和它获得的相应奖励的形式接收反馈 (feedback)。代理利用这些反馈通过称为强化学习 (reinforcement learning) 的过程来估计最优策略,然后使用该估计策略进行利用 (exploitation) 或奖励最大化。
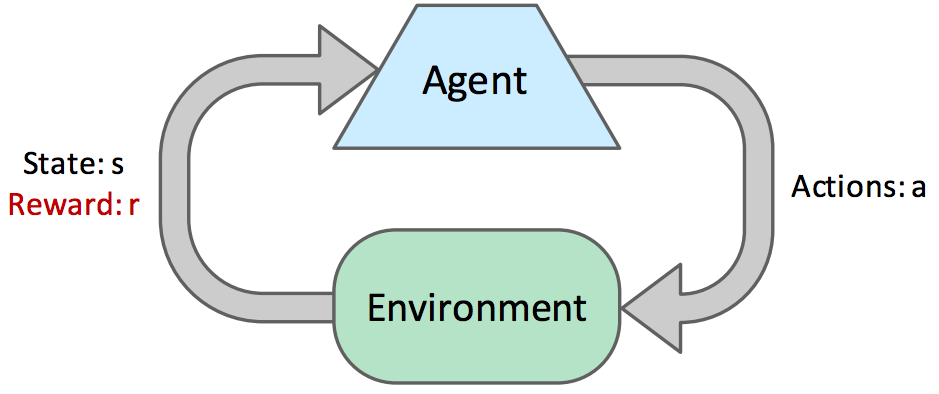
让我们从一些基本术语开始。在在线规划的每个时间步中,代理从状态 \(s\) 开始,然后采取动作 \(a\) 并最终到达后继状态 \(s'\),获得一些奖励 \(r\)。每个 \((s, a, s', r)\) 元组被称为一个样本 (sample)。通常,代理会连续采取动作并收集样本,直到到达终止状态。这样的样本集合被称为一个情节 (episode)。代理通常在探索过程中经历许多情节,以便收集学习所需的足够数据。
有两种类型的强化学习:基于模型的学习 (model-based learning) 和 无模型学习 (model-free learning)。基于模型的学习试图在探索过程中使用获得的样本来估计转移和奖励函数,然后使用这些估计值通过值迭代或策略迭代正常解决 MDP。另一方面,无模型学习试图直接估计状态的值或 Q-值,而无需使用任何内存来构建 MDP 中奖励和转移的模型。