7.3 El valor de la información perfecta
En todo lo que hemos cubierto hasta este punto, generalmente siempre hemos asumido que nuestro agente tiene toda la información que necesita para un problema en particular y/o no tiene forma de adquirir nueva información. En la práctica, este no suele ser el caso, y una de las partes más importantes de la toma de decisiones es saber si vale la pena o no reunir más evidencia para ayudar a decidir qué acción tomar. Observar nueva evidencia casi siempre tiene algún costo, ya sea en términos de tiempo, dinero o algún otro medio. En esta sección, hablaremos sobre un concepto muy importante: el valor de la información perfecta (VPI), que cuantifica matemáticamente la cantidad que se espera que aumente la utilidad máxima esperada de un agente si observa alguna nueva evidencia. Podemos comparar el VPI de aprender alguna información nueva con el costo asociado con observar esa información para tomar decisiones sobre si vale la pena o no observar.
7.3.1 Fórmula general
En lugar de simplemente presentar la fórmula para calcular el valor de la información perfecta para nueva evidencia, caminemos a través de una derivación intuitiva. Sabemos por nuestra definición anterior que el valor de la información perfecta es la cantidad que se espera que aumente nuestra utilidad máxima esperada si decidimos observar nueva evidencia. Conocemos nuestra utilidad máxima actual dada nuestra evidencia actual \(e\):
\[MEU(e) = \max_a\sum_sP(s \mid e)U(s, a)\]Además, sabemos que si observamos alguna nueva evidencia \(e'\) antes de actuar, la utilidad máxima esperada de nuestra acción en ese punto se convertiría en
\[MEU(e, e') = \max_a\sum_sP(s \mid e, e')U(s, a)\]Sin embargo, tenga en cuenta que no sabemos qué nueva evidencia obtendremos. Por ejemplo, si no conocíamos el pronóstico del tiempo de antemano y elegimos observarlo, el pronóstico que observamos podría ser bueno o malo. Debido a que no sabemos qué nueva evidencia \(e'\) obtendremos, debemos representarla como una variable aleatoria \(E'\). ¿Cómo representamos la nueva MEU que obtendremos si elegimos observar una nueva variable si no sabemos qué nos dirá la evidencia obtenida de la observación? La respuesta es calcular el valor esperado de la utilidad máxima esperada que, si bien es un trabalenguas, es el camino natural a seguir:
\[MEU(e, E') = \sum_{e'}P(e' \mid e)MEU(e, e')\]Observar una nueva variable de evidencia produce una MEU diferente con probabilidades correspondientes a las probabilidades de observar cada valor para la variable de evidencia, y así al calcular \(MEU(e, E')\) como se indicó anteriormente, calculamos lo que esperamos que sea nuestra nueva MEU si elegimos observar nueva evidencia. Ya casi hemos terminado: volviendo a nuestra definición de VPI, queremos encontrar la cantidad que se espera que aumente nuestra MEU si elegimos observar nueva evidencia. Conocemos nuestra MEU actual y el valor esperado de la nueva MEU si elegimos observar, ¡así que el aumento esperado de MEU es simplemente la diferencia de estos dos términos! De hecho,
\[\boxed{VPI(E' \mid e) = MEU(e, E') - MEU(e)}\]donde podemos leer \(VPI(E' \mid e)\) como “el valor de observar nueva evidencia E’ dada nuestra evidencia actual e”. Trabajemos a través de un ejemplo revisando nuestro escenario meteorológico por última vez:
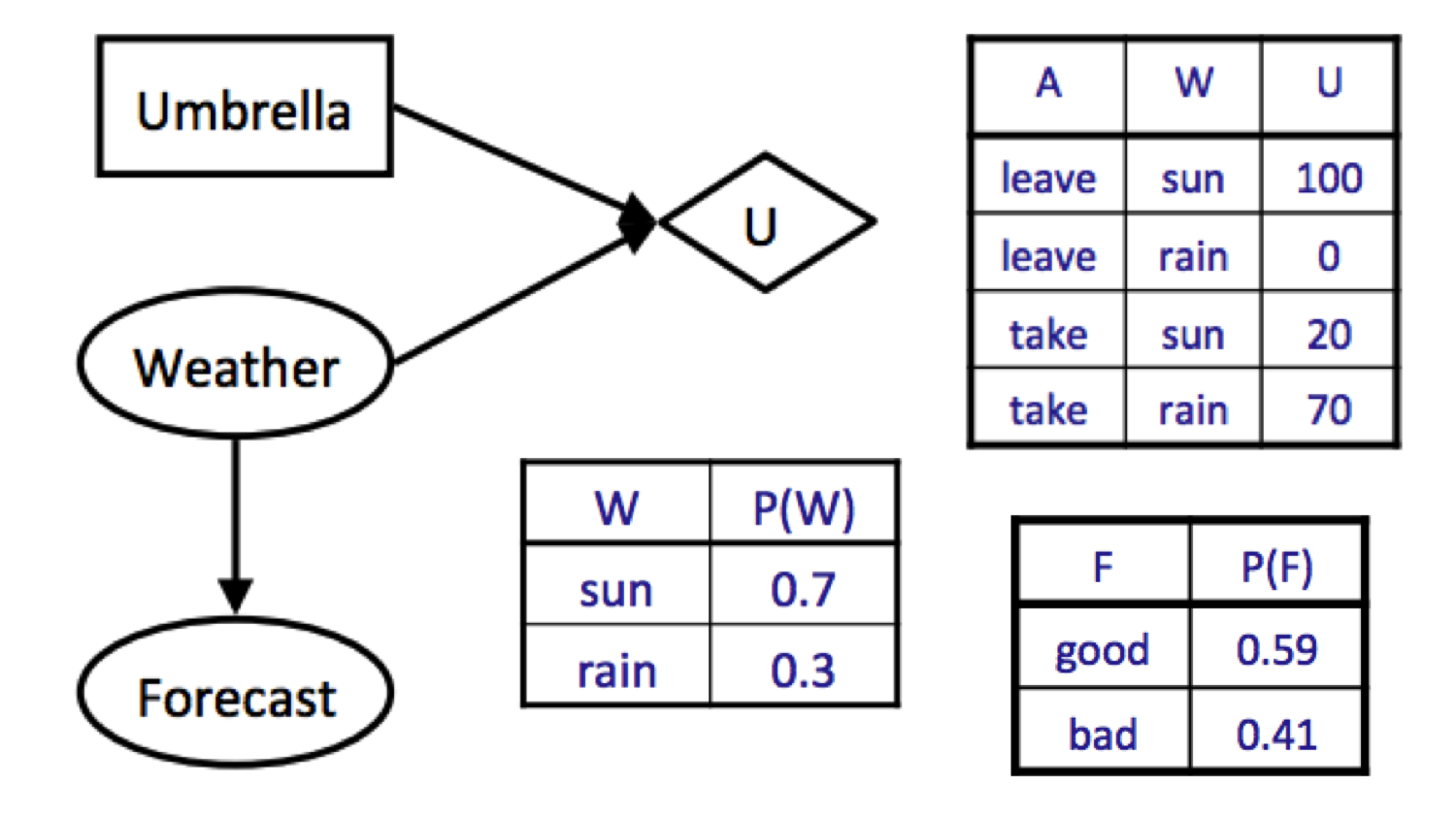
Si no observamos ninguna evidencia, entonces nuestra utilidad máxima esperada se puede calcular de la siguiente manera:
\[\begin{aligned} MEU(\varnothing) &= \max_aEU(a) \\ &= \max_a\sum_wP(w)U(a, w) \\ &= \max\{0.7 \cdot 100 + 0.3 \cdot 0, 0.7 \cdot 20 + 0.3 \cdot 70\} \\ &= \max\{70, 35\} \\ &= 70 \end{aligned}\]Tenga en cuenta que la convención cuando no tenemos evidencia es escribir \(MEU(\varnothing)\), lo que denota que nuestra evidencia es el conjunto vacío. Ahora digamos que estamos decidiendo si observar o no el pronóstico del tiempo. Ya hemos calculado que \(MEU(F = \text{malo}) = 53\), y supongamos que ejecutar un cálculo idéntico para \(F = \text{bueno}\) produce \(MEU(F = \text{bueno}) = 95\). Ahora estamos listos para calcular \(MEU(e, E')\):
\[\begin{aligned} MEU(e, E') &= MEU(F) \\ &= \sum_{e'}P(e' \mid e)MEU(e, e') \\ &= \sum_{f}P(F = f)MEU(F = f) \\ &= P(F = \text{bueno})MEU(F = \text{bueno}) + P(F = \text{malo})MEU(F = \text{malo}) \\ &= 0.59 \cdot 95 + 0.41 \cdot 53 \\ &= 77.78 \end{aligned}\]Por lo tanto, concluimos \(VPI(F) = MEU(F) - MEU(\varnothing) = 77.78 - 70 = \boxed{7.78}\).
7.3.2 Propiedades de VPI
El valor de la información perfecta tiene varias propiedades muy importantes, a saber:
-
No negatividad. \(\forall E', e\:\: VPI(E' \mid e) \geq 0\)
Observar nueva información siempre le permite tomar una decisión más informada, por lo que su utilidad máxima esperada solo puede aumentar (o permanecer igual si la información es irrelevante para la decisión que debe tomar). -
No aditividad. \(VPI(E_j, E_k \mid e) \neq VPI(E_j \mid e) + VPI(E_k \mid e)\) en general.
Esta es probablemente la más difícil de entender intuitivamente de las tres propiedades. Es cierto porque generalmente observar alguna nueva evidencia \(E_j\) podría cambiar cuánto nos importa \(E_k\); por lo tanto, no podemos simplemente sumar el VPI de observar \(E_j\) al VPI de observar \(E_k\) para obtener el VPI de observar ambos. Más bien, el VPI de observar dos nuevas variables de evidencia es equivalente a observar una, incorporarla a nuestra evidencia actual y luego observar la otra. Esto está encapsulado por la propiedad de independencia de orden de VPI, descrita más abajo. -
Independencia de orden. \(VPI(E_j, E_k \mid e) = VPI(E_j \mid e) + VPI(E_k \mid e, E_j) = VPI(E_k \mid e) + VPI(E_j \mid e, E_k)\)
Observar múltiples evidencias nuevas produce la misma ganancia en la utilidad máxima esperada independientemente del orden de observación. Esta debería ser una suposición bastante sencilla: debido a que en realidad no tomamos ninguna acción hasta después de observar cualquier variable de evidencia nueva, en realidad no importa si observamos las nuevas variables de evidencia juntas o en algún orden secuencial arbitrario.