4.4 Iteración de políticas
| La iteración de valor puede ser bastante lenta. En cada iteración, debemos actualizar los valores de todos los $$ | S | \(estados (donde\) | n | \(se refiere al operador de cardinalidad), cada uno de los cuales requiere iteración sobre todas las\) | A | \(acciones mientras calculamos el valor Q para cada acción. El cálculo de cada uno de estos valores Q, a su vez, requiere una iteración sobre cada uno de los\) | S | \(estados nuevamente, lo que lleva a un tiempo de ejecución deficiente de\)O( | S | ^2 | A | )$$. Además, cuando todo lo que queremos determinar es la política óptima para el MDP, la iteración de valor tiende a hacer mucho cálculo excesivo ya que la política calculada por la extracción de políticas generalmente converge significativamente más rápido que los valores mismos. La solución para estos defectos es utilizar la iteración de políticas como alternativa, un algoritmo que mantiene la optimalidad de la iteración de valor al tiempo que proporciona ganancias de rendimiento significativas. La iteración de políticas funciona de la siguiente manera: |
- Defina una política inicial. Esto puede ser arbitrario, pero la iteración de políticas convergerá más rápido cuanto más cerca esté la política inicial de la política óptima final.
- Repita lo siguiente hasta la convergencia:
- Evalúe la política actual con evaluación de políticas. Para una política \(\pi\), la evaluación de políticas significa calcular \(V^{\pi}(s)\) para todos los estados \(s\), donde \(V^{\pi}(s)\) es la utilidad esperada de comenzar en el estado \(s\) al seguir \(\pi\): \(V^{\pi}(s) = \sum_{s'}T(s, \pi(s), s')[R(s, \pi(s), s') + \gamma V^{\pi}(s')]\) Defina la política en la iteración \(i\) de la iteración de políticas como \(\pi_i\). Dado que estamos fijando una sola acción para cada estado, ya no necesitamos el operador \(\max\), lo que efectivamente nos deja con un sistema de \(|S|\) ecuaciones generadas por la regla anterior. Cada \(V^{\pi_i}(s)\) se puede calcular simplemente resolviendo este sistema. Alternativamente, también podemos calcular \(V^{\pi_i}(s)\) utilizando la siguiente regla de actualización hasta la convergencia, al igual que en la iteración de valor: \(V^{\pi_i}_{k+1}(s) \leftarrow \sum_{s'}T(s, \pi_i(s), s')[R(s, \pi_i(s), s') + \gamma V^{\pi_i}_k(s')]\) Sin embargo, este segundo método suele ser más lento en la práctica.
- Una vez que hayamos evaluado la política actual, use la mejora de políticas para generar una mejor política. La mejora de políticas utiliza la extracción de políticas en los valores de los estados generados por la evaluación de políticas para generar esta política nueva y mejorada: \(\pi_{i+1}(s) = \underset{a}{\operatorname{argmax}}\: \sum_{s'}T(s, a, s')[R(s, a, s') + \gamma V^{\pi_i}(s')]\) Si \(\pi_{i+1} = \pi_i\), el algoritmo ha convergido y podemos concluir que \(\pi_{i+1} = \pi_i = \pi^*\).
Repasemos nuestro ejemplo de auto de carreras por última vez (¿ya te estás cansando de él?) para ver si obtenemos la misma política usando la iteración de políticas que con la iteración de valor. Recuerde que estábamos usando un factor de descuento de \(\gamma = 0.5\).
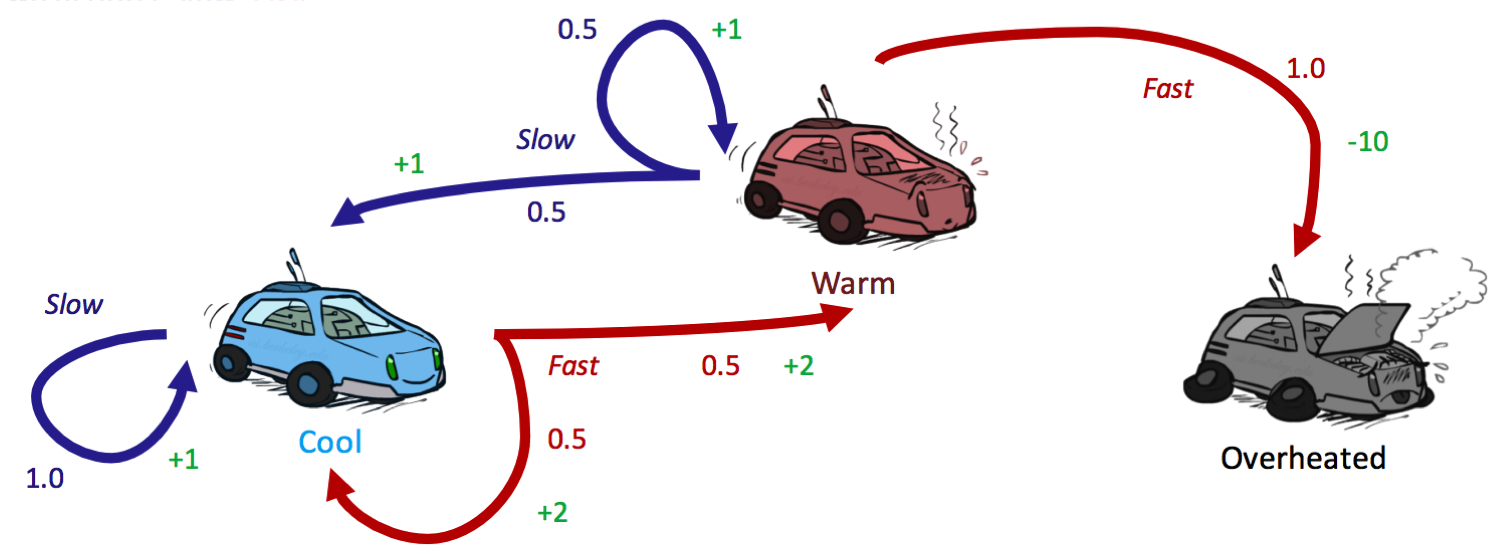
Comenzamos con una política inicial de Siempre ir lento:
| frío | tibio | sobrecalentado | |
|---|---|---|---|
| \(\pi_0\) | lento | lento | — |
Debido a que los estados terminales no tienen acciones salientes, ninguna política puede asignar un valor a uno. Por lo tanto, es razonable ignorar el estado sobrecalentado de la consideración como lo hemos hecho, y simplemente asignar \(\forall i, \:\: V^{\pi_i}(s) = 0\) para cualquier estado terminal \(s\). El siguiente paso es ejecutar una ronda de evaluación de políticas en \(\pi_0\):
\[\begin{aligned} V^{\pi_0}(frío) &= 1 \cdot [1 + 0.5 \cdot V^{\pi_0}(frío)] \\ V^{\pi_0}(tibio) &= 0.5 \cdot [1 + 0.5 \cdot V^{\pi_0}(frío)] \\ &+ 0.5 \cdot [1 + 0.5 \cdot V^{\pi_0}(tibio)] \end{aligned}\]Resolver este sistema de ecuaciones para \(V^{\pi_0}(frío)\) y \(V^{\pi_0}(tibio)\) produce:
| frío | tibio | sobrecalentado | |
|---|---|---|---|
| \(V^{\pi_0}\) | 2 | 2 | 0 |
Ahora podemos ejecutar la extracción de políticas con estos valores:
\[\begin{aligned} \pi_{1}(frío) &= {\operatorname{argmax}}\{lento: 1 \cdot [1 + 0.5 \cdot 2],\:\: rápido: 0.5 \cdot [2 + 0.5 \cdot 2] + 0.5 \cdot [2 + 0.5 \cdot 2]\} \\ &= {\operatorname{argmax}}\{lento: 2,\:\: rápido: 3\} \\ &= \boxed{rápido}\\ \pi_{1}(tibio) &= {\operatorname{argmax}}\{lento: 0.5 \cdot [1 + 0.5 \cdot 2] + 0.5 \cdot [1 + 0.5 \cdot 2] ,\:\: rápido: 1 \cdot [-10 + 0.5 \cdot 0]\} \\ &= {\operatorname{argmax}}\{lento: 2,\:\: rápido: -10\} \\ &= \boxed{lento} \end{aligned}\]Ejecutar la iteración de políticas para una segunda ronda produce \(\pi_2(frío) = rápido\) y \(\pi_2(tibio) = lento\). Dado que esta es la misma política que \(\pi_1\), podemos concluir que \(\pi_1 = \pi_2 = \pi^*\). ¡Verifique esto para practicar!
| frío | tibio | |
|---|---|---|
| \(\pi_0\) | lento | lento |
| \(\pi_1\) | rápido | lento |
| \(\pi_2\) | rápido | lento |
Este ejemplo muestra el verdadero poder de la iteración de políticas: con solo dos iteraciones, ¡ya hemos llegado a la política óptima para nuestro MDP de auto de carreras! Esto es más de lo que podemos decir para cuando ejecutamos la iteración de valor en el mismo MDP, que todavía estaba a varias iteraciones de la convergencia después de las dos actualizaciones que realizamos.