5.2 基于模型的学习 (Model-Based Learning)
在基于模型的学习中,代理通过记录在进入每个 Q-状态 \((s, a)\) 后到达每个状态 \(s'\) 的次数,来生成转移函数 \(\hat{T}(s, a, s')\) 的近似值。然后,代理可以通过归一化 (normalizing) 它收集的计数来根据请求生成近似转移函数 \(\hat{T}\)——将每个观察到的元组 \((s, a, s')\) 的计数除以代理处于 Q-状态 \((s, a)\) 的所有实例的计数之和。计数的归一化对它们进行缩放,使它们的和为 1,从而允许它们被解释为概率。
考虑以下具有状态 \(S = \{A, B, C, D, E, x\}\) 的 MDP 示例,其中 \(x\) 代表终止状态,折扣因子 \(\gamma = 1\):
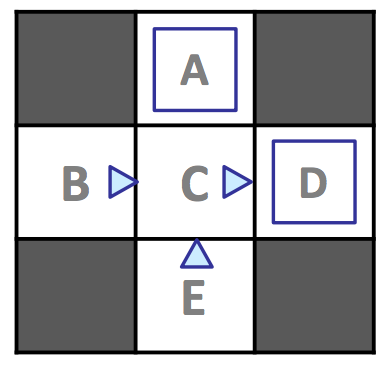
假设我们允许我们的代理在上述策略 \(\pi_{explore}\) 下探索 MDP 四个情节(方向三角形表示朝三角形指向的方向运动,蓝色方块表示选择 exit 作为动作),产生以下结果:

我们现在总共有 12 个样本,每个情节 3 个,计数如下:
| \(s\) | \(a\) | \(s'\) | \(count\) | |——–|———|——–|———–| | \(A\) | \(exit\) | \(x\) | 1 | | \(B\) | \(east\) | \(C\) | 2 | | \(C\) | \(east\) | \(A\) | 1 | | \(C\) | \(east\) | \(D\) | 3 | | \(D\) | \(exit\) | \(x\) | 3 | | \(E\) | \(north\) | \(C\) | 2 |
回想一下 \(T(s, a, s') = P(s' | a, s)\),我们可以通过将每个元组 \((s, a, s')\) 的计数除以我们处于 Q-状态 \((s, a)\) 的总次数来使用这些计数估计转移函数,并直接从我们在探索期间获得的奖励中估计奖励函数:
转移函数: \(\hat{T}(s, a, s')\)
\[\hat{T}(A, exit, x) = \frac{\#(A, exit, x)}{\#(A, exit)} = \frac{1}{1} = 1\] \[\hat{T}(B, east, C) = \frac{\#(B, east, C)}{\#(B, east)} = \frac{2}{2} = 1\] \[\hat{T}(C, east, A) = \frac{\#(C, east, A)}{\#(C, east)} = \frac{1}{4} = 0.25\] \[\hat{T}(C, east, D) = \frac{\#(C, east, D)}{\#(C, east)} = \frac{3}{4} = 0.75\] \[\hat{T}(D, exit, x) = \frac{\#(D, exit, x)}{\#(D, exit)} = \frac{3}{3} = 1\] \[\hat{T}(E, north, C) = \frac{\#(E, north, C)}{\#(E, north)} = \frac{2}{2} = 1\]奖励函数: \(\hat{R}(s, a, s')\)
\[\hat{R}(A, exit, x) = -10\] \[\hat{R}(B, east, C) = -1\] \[\hat{R}(C, east, A) = -1\] \[\hat{R}(C, east, D) = -1\] \[\hat{R}(D, exit, x) = +10\] \[\hat{R}(E, north, C) = -1\]根据大数定律 (law of large numbers),随着我们通过让代理经历更多情节来收集越来越多的样本,我们的 \(\hat{T}\) 和 \(\hat{R}\) 模型将得到改进,\(\hat{T}\) 向 \(T\) 收敛,\(\hat{R}\) 随着我们发现新的 \((s, a, s')\) 元组而获得先前未发现的奖励的知识。只要我们认为合适,我们就可以结束代理的训练,通过使用我们当前的 \(\hat{T}\) 和 \(\hat{R}\) 模型运行值迭代或策略迭代来生成策略 \(\pi_{exploit}\),并使用 \(\pi_{exploit}\) 进行利用,让我们的代理遍历 MDP,采取寻求奖励最大化而不是寻求学习的动作。
我们很快将讨论如何有效地在探索和利用之间分配时间的方法。基于模型的学习非常简单直观,但非常有效,仅通过计数和归一化即可生成 \(\hat{T}\) 和 \(\hat{R}\)。然而,维护每个看到的 \((s, a, s')\) 元组的计数可能很昂贵,因此在下一节关于无模型学习的内容中,我们将开发完全绕过维护计数并避免基于模型的学习所需的内存开销的方法。