9.3 感知器 (Perceptron)
9.3.1 线性分类器 (Linear Classifiers)
朴素贝叶斯背后的核心思想是提取训练数据的某些属性(称为特征),然后估计给定特征的标签概率:\(P(y|f_1, f_2, \ldots, f_n)\)。因此,给定一个新的数据点,我们可以提取相应的特征,并将新的数据点分类为给定特征概率最高的标签。然而,这需要我们估计分布,我们是用 MLE 做的。如果我们决定不估计概率分布呢?让我们从一个简单的线性分类器开始,我们可以将其用于二元分类 (binary classification),其中标签有两种可能性:正或负。
线性分类器 (linear classifier) 的基本思想是使用特征的线性组合来进行分类——我们称之为激活 (activation) 的值。具体来说,激活函数接收一个数据点,将我们数据点的每个特征 \(f_i(\mathbf{x})\) 乘以相应的权重 \(w_i\),并输出所有结果值的总和。以向量形式,我们也可以将其写为我们的权重向量 \(\mathbf{w}\) 和我们的特征化数据点向量 \(\mathbf{f}(\mathbf{x})\) 的点积:
\[\text{activation}_w(\mathbf{x}) = h_{\mathbf{w}}(\mathbf{x}) = \sum_i w_i f_i(\mathbf{x}) = \mathbf{w}^T \mathbf{f}(\mathbf{x}) = \mathbf{w} \cdot \mathbf{f}(\mathbf{x})\]
如何使用激活进行分类?对于二元分类,当数据点的激活为正时,我们将该数据点分类为正标签,如果是负的,我们将它分类为负标签:
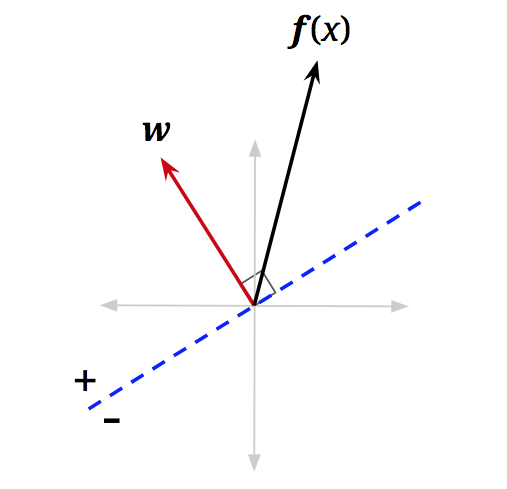
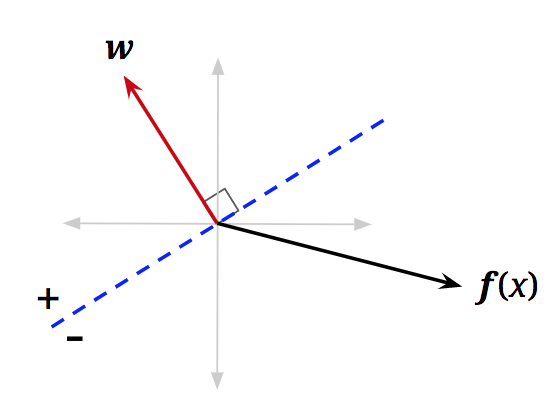
\[\text{classify}(\mathbf{x}) = \begin{cases} + & \text{if } h_{\mathbf{w}}(\mathbf{x}) > 0 \\ - & \text{if } h_{\mathbf{w}}(\mathbf{x}) < 0 \end{cases}\]为了从几何上理解这一点,让我们重新检查向量化的激活函数。我们可以如下重写点积,其中 \(\|\cdot\|\) 是模运算符,\(\theta\) 是 \(\mathbf{w}\) 和 \(\mathbf{f}(\mathbf{x})\) 之间的角度:
\[h_{\mathbf{w}}(\mathbf{x}) = \mathbf{w} \cdot \mathbf{f}(\mathbf{x}) = \|\mathbf{w}\| \|\mathbf{f}(\mathbf{x})\| \cos(\theta)\]

由于模总是非负的,并且我们的分类规则查看激活的符号,因此决定类别的唯一重要项是 \(\cos(\theta)\):
\[\text{classify}(\mathbf{x}) = \begin{cases} + & \text{if } \cos(\theta) > 0 \\ - & \text{if } \cos(\theta) < 0 \end{cases}\]因此,我们要关注 \(\cos(\theta)\) 何时为负或正。很容易看出,对于 \(\theta < \frac{\pi}{2}\),\(\cos(\theta)\) 将在区间 \((0, 1]\) 内,这是正的。对于 \(\theta > \frac{\pi}{2}\),\(\cos(\theta)\) 将在区间 \([-1, 0)\) 内,这是负的。你可以通过查看单位圆来确认这一点。本质上,我们简单的线性分类器正在检查新数据点的特征向量是否大致与预定义的权重向量“指向”相同的方向,如果是,则应用正标签:
\[\text{classify}(\mathbf{x}) = \begin{cases} + & \text{if } \theta < \frac{\pi}{2} \text{ (即当 } \theta \text{ 小于 90°,或锐角)} \\ - & \text{if } \theta > \frac{\pi}{2} \text{ (即当 } \theta \text{ 大于 90°,或钝角)} \end{cases}\]到目前为止,我们还没有考虑 \(\text{activation}_w(\mathbf{x}) = \mathbf{w}^T \mathbf{f}(\mathbf{x}) = 0\) 的点。遵循所有相同的逻辑,我们将看到这些点的 \(\cos(\theta) = 0\)。此外,对于这些点,\(\theta = \frac{\pi}{2}\)(即 \(\theta\) 是 90\textdegree)。换句话说,这些是特征向量与 \(\mathbf{w}\) 正交的数据点。我们可以添加一条与 \(\mathbf{w}\) 正交的虚线蓝线,任何位于这条线上的特征向量的激活都将等于 \(0\):

决策边界 (Decision Boundary)
我们称这条蓝线为决策边界 (decision boundary),因为它是分隔我们将数据点分类为正的区域和负的区域的边界。在更高维度中,线性决策边界通常被称为超平面 (hyperplane)。超平面是一个比潜在空间低一维的线性表面,从而将表面分为两部分。对于一般分类器(非线性分类器),决策边界可能不是线性的,而只是定义为特征向量空间中分隔类别的表面。为了对最终位于决策边界上的点进行分类,我们可以应用任一标签,因为两个类别同样有效(在下面的算法中,我们将把线上的点分类为正)。