3.2 Minimax
El primer algoritmo de juego de suma cero que consideraremos es minimax, que se ejecuta bajo el supuesto motivador de que el oponente al que nos enfrentamos se comporta de manera óptima y siempre realizará el movimiento que sea peor para nosotros. Para introducir este algoritmo, primero debemos formalizar la noción de utilidades terminales y valor de estado. El valor de un estado es la puntuación óptima alcanzable por el agente que controla ese estado. Para tener una idea de lo que esto significa, observe el siguiente tablero de juego de Pacman trivialmente simple:

Supongamos que Pacman comienza con 10 puntos y pierde 1 punto por movimiento hasta que come la bolita, momento en el que el juego llega a un estado terminal y termina. Podemos comenzar a construir un árbol de juego para este tablero de la siguiente manera, donde los hijos de un estado son estados sucesores al igual que en los árboles de búsqueda para problemas de búsqueda normales:
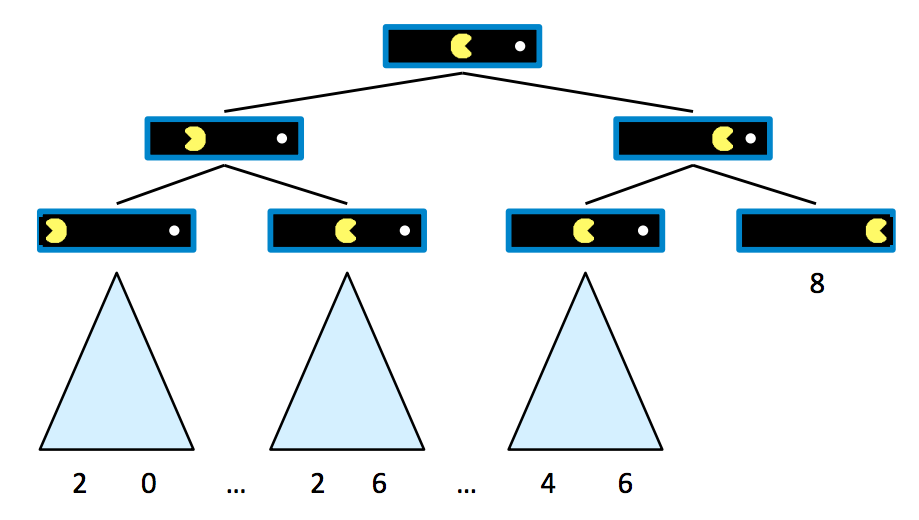
Es evidente a partir de este árbol que si Pacman va directamente a la bolita, termina el juego con una puntuación de 8 puntos, mientras que si retrocede en cualquier punto, termina con una puntuación de menor valor. Ahora que hemos generado un árbol de juego con varios estados terminales e intermedios, estamos listos para formalizar el significado del valor de cualquiera de estos estados.
El valor de un estado se define como el mejor resultado posible (utilidad) que un agente puede lograr desde ese estado. Formalizaremos el concepto de utilidad de manera más concreta más adelante, pero por ahora es suficiente pensar simplemente en la utilidad de un agente como su puntuación o número de puntos que alcanza. El valor de un estado terminal, llamado utilidad terminal, es siempre un valor conocido determinista y una propiedad inherente del juego. En nuestro ejemplo de Pacman, el valor del estado terminal más a la derecha es simplemente 8, la puntuación que obtiene Pacman al ir directamente a la bolita. Además, en este ejemplo, el valor de un estado no terminal se define como el máximo de los valores de sus hijos. Definiendo \(V(s)\) como la función que define el valor de un estado \(s\), podemos resumir la discusión anterior:
\[\forall \text{estados no terminales}, V(s) = \max_{s' \in \text{sucesores}(s)} V(s')\] \[\forall \text{estados terminales}, V(s) = \text{conocido}\]Esto establece una regla recursiva muy simple, de la cual debería tener sentido que el valor del hijo derecho directo del nodo raíz sea 8, y el hijo izquierdo directo del nodo raíz sea 6, ya que estas son las puntuaciones máximas posibles que el agente puede obtener si se mueve a la derecha o a la izquierda, respectivamente, desde el estado inicial. De ello se deduce que al ejecutar dicho cálculo, un agente puede determinar que es óptimo moverse a la derecha, ya que el hijo derecho tiene un valor mayor que el hijo izquierdo del estado inicial.
Presentemos ahora un nuevo tablero de juego con un fantasma adversario que quiere evitar que Pacman coma la bolita.

Las reglas del juego dictan que los dos agentes se turnan para realizar movimientos, lo que lleva a un árbol de juego donde los dos agentes se alternan en capas del árbol que “controlan”. Que un agente tenga control sobre un nodo simplemente significa que ese nodo corresponde a un estado donde es el turno de ese agente, por lo que es su oportunidad de decidir sobre una acción y cambiar el estado del juego en consecuencia. Aquí está el árbol de juego que surge del nuevo tablero de juego de dos agentes de arriba:
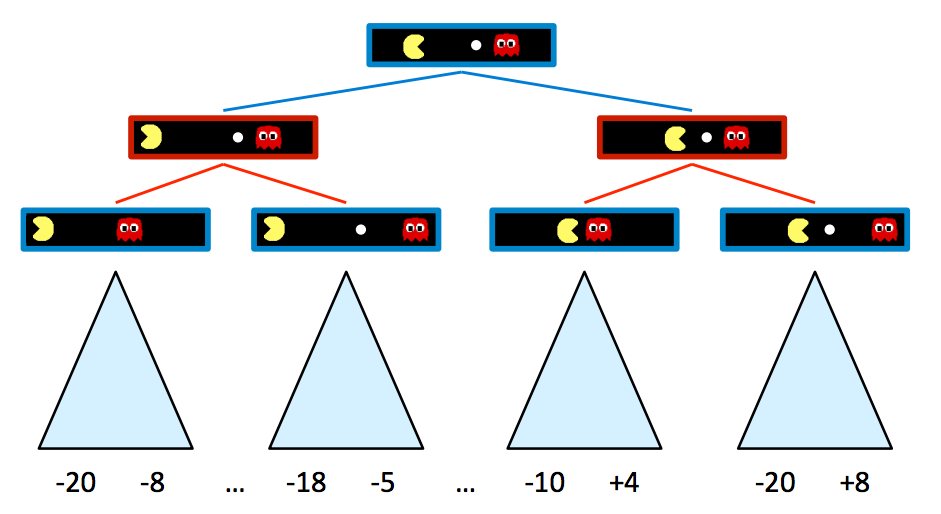
Los nodos azules corresponden a nodos que Pacman controla y puede decidir qué acción tomar, mientras que los nodos rojos corresponden a nodos controlados por fantasmas. Tenga en cuenta que todos los hijos de los nodos controlados por fantasmas son nodos donde el fantasma se ha movido hacia la izquierda o hacia la derecha desde su estado en el padre, y viceversa para los nodos controlados por Pacman. Para simplificar, trunquemos este árbol de juego a un árbol de profundidad 2 y asignemos valores falsificados a los estados terminales de la siguiente manera:
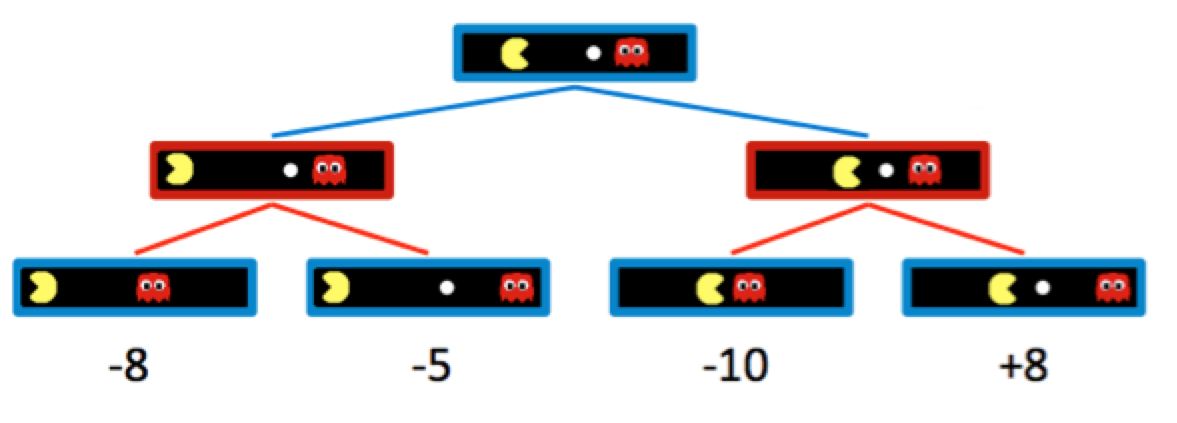
Naturalmente, agregar nodos controlados por fantasmas cambia el movimiento que Pacman cree que es óptimo, y el nuevo movimiento óptimo se determina con el algoritmo minimax. En lugar de maximizar la utilidad sobre los hijos en cada nivel del árbol, el algoritmo minimax solo maximiza sobre los hijos de los nodos controlados por Pacman, mientras minimiza sobre los hijos de los nodos controlados por fantasmas. Por lo tanto, los dos nodos fantasma anteriores tienen valores de \(\min(-8, -5) = -8\) y \(\min(-10, +8) = -10\) respectivamente. Correspondientemente, el nodo raíz controlado por Pacman tiene un valor de \(\max(-8, -10) = -8\). Dado que Pacman quiere maximizar su puntuación, irá a la izquierda y tomará la puntuación de \(-8\) en lugar de intentar ir por la bolita y anotar \(-10\). Este es un excelente ejemplo del surgimiento del comportamiento a través de la computación: aunque Pacman quiere la puntuación de \(+8\) que puede obtener si termina en el estado hijo más a la derecha, a través de minimax “sabe” que un fantasma que se desempeña de manera óptima no le permitirá tenerla. Para actuar de manera óptima, Pacman se ve obligado a cubrir sus apuestas y moverse contraintuitivamente lejos de la bolita para minimizar la magnitud de su derrota. Podemos resumir la forma en que minimax asigna valores a los estados de la siguiente manera:
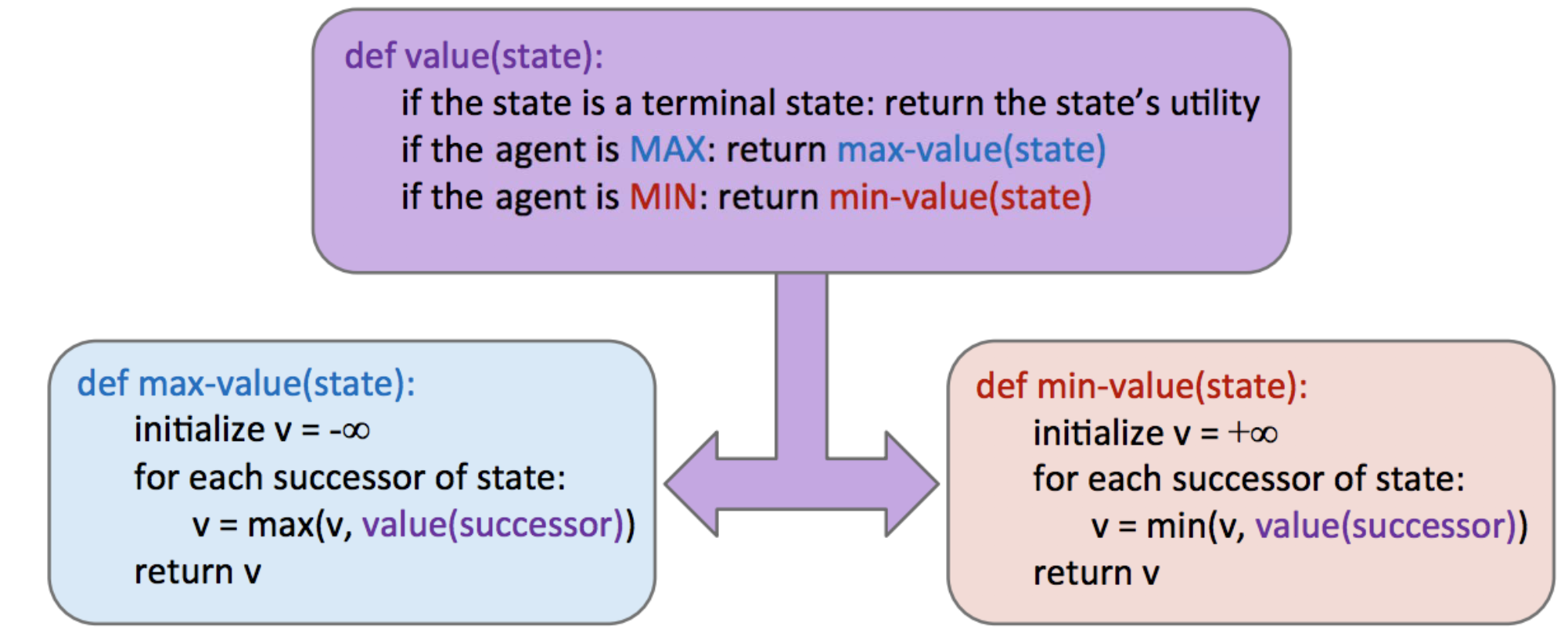
\[\forall \text{estados controlados por el agente}, V(s) = \max_{s'\in sucesores(s)} V(s')\] \[\forall \text{estados controlados por el oponente}, V(s) = \min_{s'\in sucesores(s)}V(s')\] \[\forall \text{estados terminales}, V(s) = \text{conocido}\]En la implementación, minimax se comporta de manera similar a la búsqueda en profundidad, calculando los valores de los nodos en el mismo orden que lo haría DFS, comenzando con el nodo terminal más a la izquierda y trabajando iterativamente hacia la derecha. Más precisamente, realiza un recorrido posterior (postorder traversal) del árbol de juego. El pseudocódigo resultante para minimax es elegante e intuitivamente simple, y se presenta a continuación. Tenga en cuenta que minimax devolverá una acción, que corresponde a la rama del nodo raíz al hijo del que ha tomado su valor.
3.2.1 Poda Alfa-Beta
Minimax parece casi perfecto: es simple, es óptimo y es intuitivo. Sin embargo, su ejecución es muy similar a la búsqueda en profundidad y su complejidad temporal es idéntica, un pésimo \(O(b^m)\). Recordando que \(b\) es el factor de ramificación y \(m\) es la profundidad aproximada del árbol en la que se pueden encontrar los nodos terminales, esto produce un tiempo de ejecución demasiado grande para muchos juegos. Por ejemplo, el ajedrez tiene un factor de ramificación \(b \approx 35\) y una profundidad de árbol \(m \approx 100\). Para ayudar a mitigar este problema, minimax tiene una optimización: poda alfa-beta.
Conceptualmente, la poda alfa-beta es esto: si está tratando de determinar el valor de un nodo \(n\) mirando a sus sucesores, deje de mirar tan pronto como sepa que el valor de \(n\) puede ser, en el mejor de los casos, igual al valor óptimo del padre de \(n\). Desentrañemos lo que significa esta declaración complicada con un ejemplo. Considere el siguiente árbol de juego, con nodos cuadrados correspondientes a estados terminales, triángulos que apuntan hacia abajo correspondientes a nodos minimizadores y triángulos que apuntan hacia arriba correspondientes a nodos maximizadores:
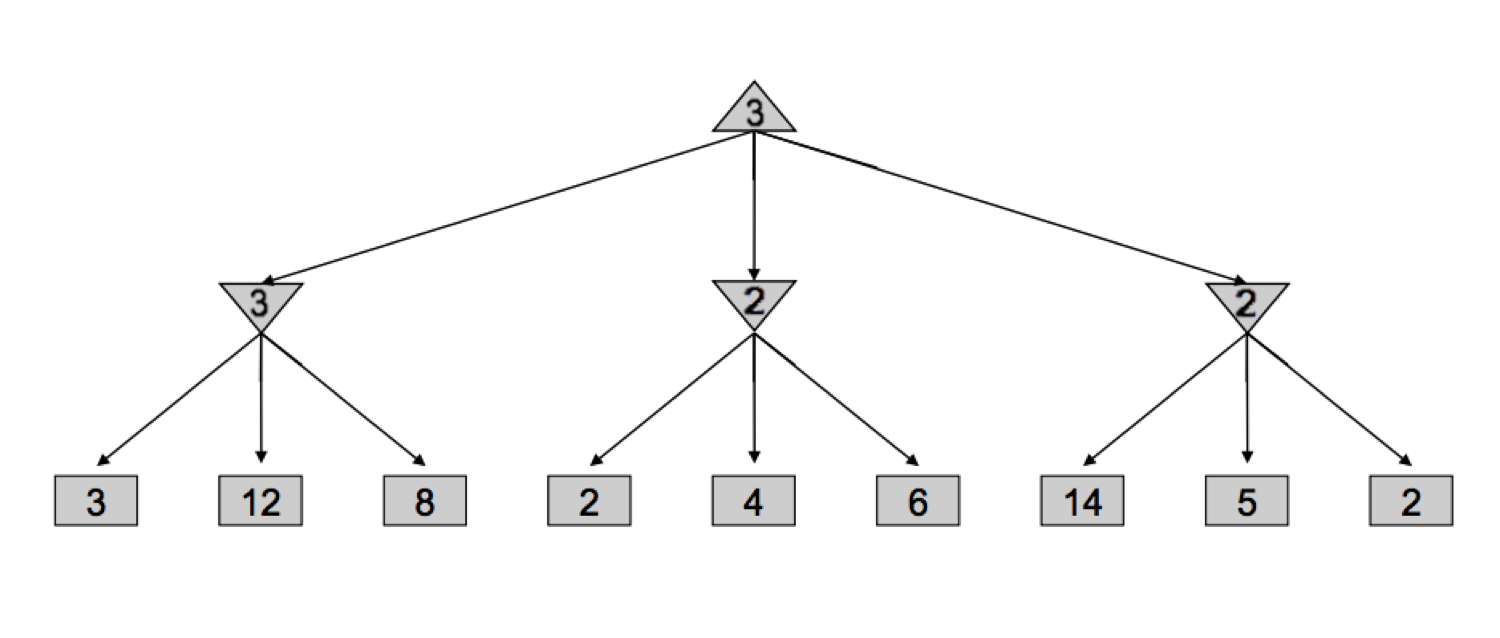
Veamos cómo minimax derivó este árbol: comenzó iterando a través de los nodos con valores 3, 12 y 8, y asignando el valor \(\min(3, 12, 8) = 3\) al minimizador más a la izquierda. Luego, asignó \(\min(2, 4, 6) = 2\) al minimizador del medio, y \(\min(14, 5, 2) = 2\) al minimizador más a la derecha, antes de finalmente asignar \(\max(3, 2, 2) = 3\) al maximizador en la raíz. Sin embargo, si pensamos en esta situación, podemos darnos cuenta de que tan pronto como visitamos al hijo del minimizador del medio con valor \(2\), ya no necesitamos mirar a los otros hijos del minimizador del medio. ¿Por qué? Dado que hemos visto un hijo del minimizador del medio con valor 2, sabemos que no importa qué valores tengan los otros hijos, el valor del minimizador del medio puede ser como máximo 2. Ahora que esto se ha establecido, pensemos un paso más allá: el maximizador en la raíz está decidiendo entre el valor de 3 del minimizador izquierdo y el valor que es \(\leq 2\), se garantiza que preferirá el 3 devuelto por el minimizador izquierdo sobre el valor devuelto por el minimizador del medio, independientemente de los valores de sus hijos restantes. Es precisamente por eso que podemos podar el árbol de búsqueda, sin mirar nunca a los hijos restantes del minimizador del medio:
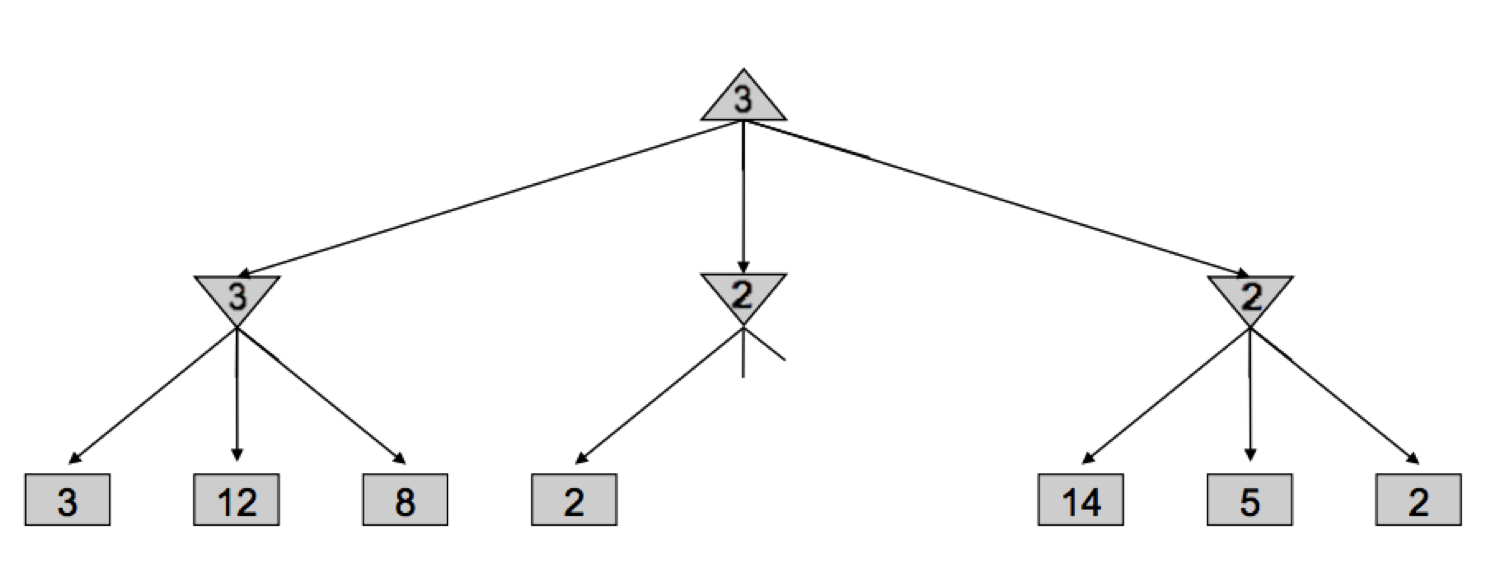
La implementación de tal poda puede reducir nuestro tiempo de ejecución a tan bueno como \(O(b^{m/2})\), duplicando efectivamente nuestra profundidad “resoluble”. En la práctica, a menudo es mucho menos, pero generalmente puede hacer que sea factible buscar hasta al menos uno o dos niveles más. Esto sigue siendo bastante significativo, ya que el jugador que piensa 3 movimientos por delante tiene más probabilidades de ganar que el jugador que piensa 2 movimientos por delante. Esta poda es exactamente lo que hace el algoritmo minimax con poda alfa-beta, y se implementa de la siguiente manera:
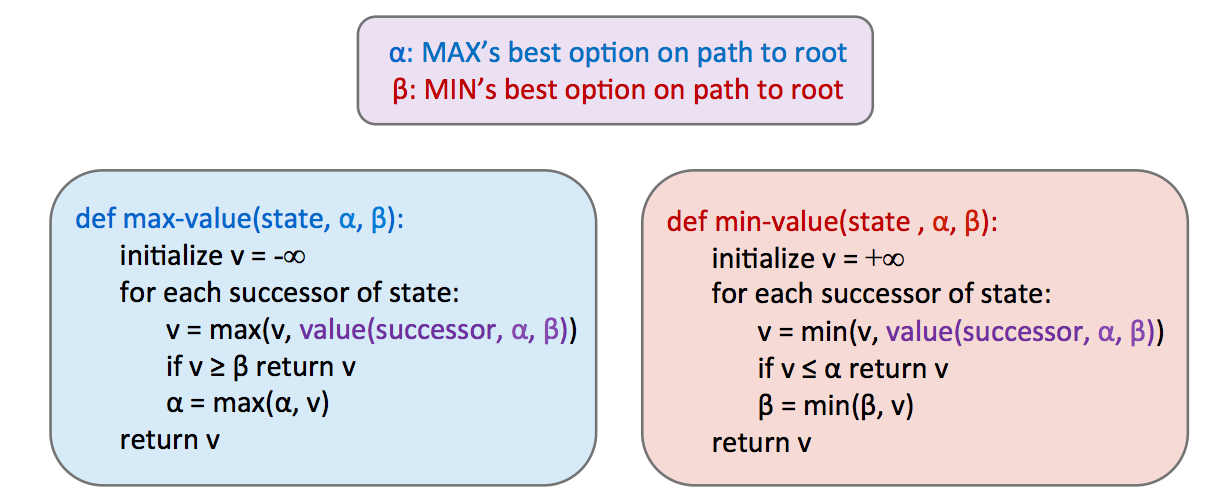
Tómese un tiempo para comparar esto con el pseudocódigo para minimax vainilla, y observe que ahora podemos regresar temprano sin buscar a través de cada sucesor.
3.2.2 Funciones de evaluación
Aunque la poda alfa-beta puede ayudar a aumentar la profundidad para la que podemos ejecutar minimax de manera factible, esto generalmente no es ni siquiera lo suficientemente bueno para llegar al fondo de los árboles de búsqueda para una gran mayoría de juegos. Como resultado, recurrimos a las funciones de evaluación, funciones que toman un estado y generan una estimación del verdadero valor minimax de ese nodo. Por lo general, esto se interpreta claramente como que los estados “mejores” reciben valores más altos por una buena función de evaluación que los estados “peores”. Las funciones de evaluación se emplean ampliamente en minimax de profundidad limitada, donde tratamos los nodos no terminales ubicados en nuestra profundidad máxima resoluble como nodos terminales, dándoles utilidades terminales simuladas según lo determinado por una función de evaluación cuidadosamente seleccionada. Debido a que las funciones de evaluación solo pueden generar estimaciones de los valores de las utilidades no terminales, esto elimina la garantía de juego óptimo al ejecutar minimax.
Por lo general, se pone mucho pensamiento y experimentación en la selección de una función de evaluación al diseñar un agente que ejecuta minimax, y cuanto mejor sea la función de evaluación, más cerca estará el agente de comportarse de manera óptima. Además, profundizar en el árbol antes de usar una función de evaluación también tiende a darnos mejores resultados: enterrar su cálculo más profundamente en el árbol de juego mitiga el compromiso de la optimalidad. Estas funciones tienen un propósito muy similar en los juegos al que tienen las heurísticas en los problemas de búsqueda estándar.
El diseño más común para una función de evaluación es una combinación lineal de características.
\[Eval(s) = w_1f_1(s) + w_2f_2(s) + ... + w_nf_n(s)\]Cada ( f_i(s) ) corresponde a una característica extraída del estado de entrada ( s ), y a cada característica se le asigna un peso correspondiente \(w_i\). Las características son simplemente algún elemento de un estado de juego que podemos extraer y asignar un valor numérico. Por ejemplo, en un juego de damas podríamos construir una función de evaluación con 4 características: número de peones del agente, número de reyes del agente, número de peones del oponente y número de reyes del oponente. Luego seleccionaríamos los pesos apropiados basándonos vagamente en su importancia. En nuestro ejemplo de damas, tiene más sentido seleccionar pesos positivos para los peones/reyes de nuestro agente y pesos negativos para los peones/reyes de nuestro oponente. Además, podríamos decidir que, dado que los reyes son piezas más valiosas en las damas que los peones, las características correspondientes a los reyes de nuestro agente/oponente merecen pesos con mayor magnitud que las características relativas a los peones. A continuación se muestra una posible función de evaluación que se ajusta a las características y pesos que acabamos de intercambiar ideas:
\[Eval(s) = 2 \cdot agent\_kings(s) + agent\_pawns(s) - 2 \cdot opponent\_kings(s) - opponent\_pawns(s)\]Como puede ver, el diseño de la función de evaluación puede ser bastante libre y no necesariamente tiene que ser funciones lineales tampoco. Por ejemplo, las funciones de evaluación no lineales basadas en redes neuronales son muy comunes en las aplicaciones de aprendizaje por refuerzo. Lo más importante a tener en cuenta es que la función de evaluación produce puntuaciones más altas para mejores posiciones con la mayor frecuencia posible. Esto puede requerir mucho ajuste fino y experimentación sobre el rendimiento de los agentes que utilizan funciones de evaluación con una multitud de características y pesos diferentes.