8.2 Modelos Ocultos de Markov
Con los modelos de Markov, vimos cómo podíamos incorporar el cambio a lo largo del tiempo a través de una cadena de variables aleatorias. Por ejemplo, si queremos saber el clima en el día 10 con nuestro modelo de Markov estándar de arriba, podemos comenzar con la distribución inicial \(P(W_0)\) y usar el algoritmo mini-forward con nuestro modelo de transición para calcular \(P(W_{10})\). Sin embargo, entre el tiempo \(t = 0\) y el tiempo \(t = 10\), podemos recopilar nueva evidencia meteorológica que podría afectar nuestra creencia de la distribución de probabilidad sobre el clima en cualquier paso de tiempo dado. En términos más simples, si el clima pronostica un 80% de probabilidad de lluvia en el día 10, pero hay cielos despejados en la noche del día 9, esa probabilidad del 80% podría caer drásticamente. Esto es exactamente con lo que nos ayuda el Modelo Oculto de Markov: nos permite observar alguna evidencia en cada paso de tiempo, lo que potencialmente puede afectar la distribución de creencias en cada uno de los estados. El Modelo Oculto de Markov para nuestro modelo meteorológico se puede describir utilizando una estructura de red bayesiana que se parece a la siguiente:
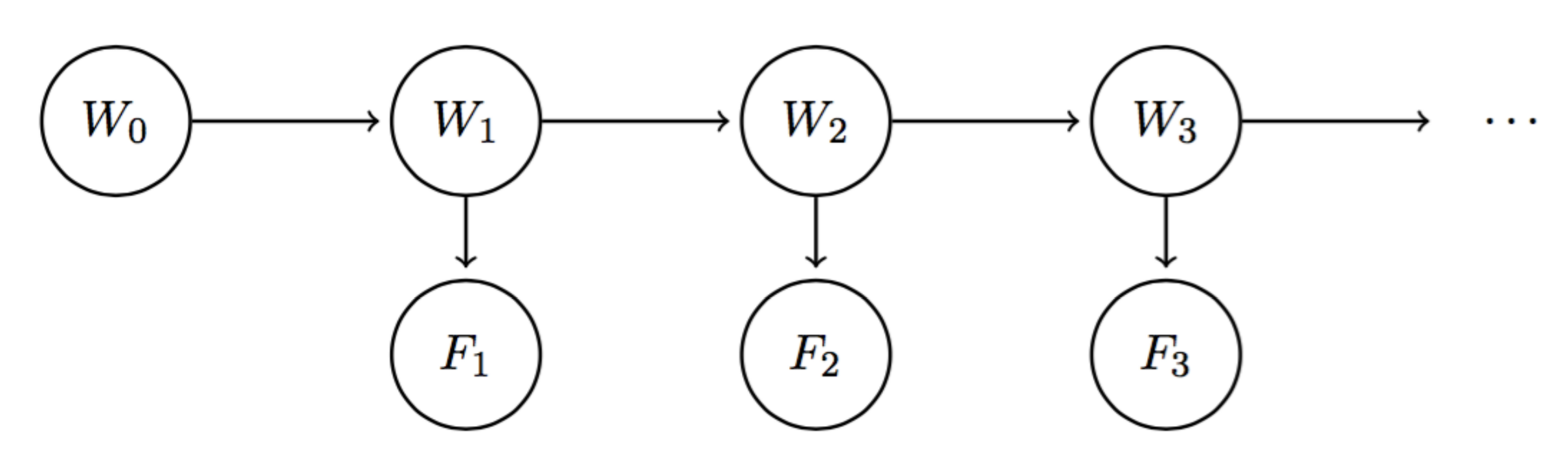
A diferencia de los modelos de Markov vainilla, ahora tenemos dos tipos diferentes de nodos. Para hacer esta distinción, llamaremos a cada \(W_i\) una variable de estado y a cada pronóstico del tiempo \(F_i\) una variable de evidencia. Dado que \(W_i\) codifica nuestra creencia de la distribución de probabilidad para el clima en el día \(i\), debería ser un resultado natural que el pronóstico del tiempo para el día \(i\) sea condicionalmente dependiente de esta creencia. El modelo implica relaciones de independencia condicional similares a las de los modelos de Markov estándar, con un conjunto adicional de relaciones para las variables de evidencia:
\[F_1 \perp W_0 \mid W_1\] \[\forall i = 2, \dots, n; \quad W_i \perp \{W_0, \dots, W_{i-2}, F_1, \dots, F_{i-1}\} \mid W_{i-1}\] \[\forall i = 2, \dots, n; \quad F_i \perp \{W_0, \dots, W_{i-1}, F_1, \dots, F_{i-1}\} \mid W_i\]Al igual que los modelos de Markov, los Modelos Ocultos de Markov hacen la suposición de que el modelo de transición \(P(W_{i+1} \mid W_i)\) es estacionario. Los Modelos Ocultos de Markov hacen la suposición simplificadora adicional de que el modelo de sensor \(P(F_i \mid W_i)\) también es estacionario. Por lo tanto, cualquier Modelo Oculto de Markov se puede representar de forma compacta con solo tres tablas de probabilidad: la distribución inicial, el modelo de transición y el modelo de sensor.
Como punto final sobre la notación, definiremos la distribución de creencias en el tiempo \(i\) con toda la evidencia \(F_1, \dots, F_i\) observada hasta la fecha:
\[B(W_i) = P(W_i \mid f_1, \dots, f_i)\]De manera similar, definiremos \(B'(W_i)\) como la distribución de creencias en el tiempo \(i\) con evidencia \(f_1, \dots, f_{i-1}\) observada:
\[B'(W_i) = P(W_i \mid f_1, \dots, f_{i-1})\]Definiendo \(e_i\) como evidencia observada en el paso de tiempo \(i\), a veces puede ver la evidencia agregada de los pasos de tiempo \(1 \leq i \leq t\) reexpresada en la siguiente forma:
\[e_{1:t} = e_1, \dots, e_t\]Bajo esta notación, \(P(W_i \mid f_1, \dots, f_{i-1})\) se puede escribir como \(P(W_i \mid f_{1:(i-1)})\). Esta notación será relevante en las próximas secciones, donde discutiremos las actualizaciones de lapso de tiempo que incorporan iterativamente nueva evidencia en nuestro modelo meteorológico.
8.2.1 El algoritmo forward
Usando las suposiciones de probabilidad condicional establecidas anteriormente y las propiedades de marginación de las tablas de probabilidad condicional, podemos derivar una relación entre \(B(W_i)\) y \(B'(W_{i+1})\) que tiene la misma forma que la regla de actualización para el algoritmo mini-forward. Comenzamos usando la marginación:
\[B'(W_{i+1}) = P(W_{i+1} \mid f_1, \dots, f_i) = \sum_{w_i}P(W_{i+1}, w_i \mid f_1, \dots, f_i)\]Esto se puede volver a expresar entonces con la regla de la cadena de la siguiente manera:
\[B'(W_{i+1}) = P(W_{i+1} \mid f_1, \dots, f_i) = \sum_{w_i}P(W_{i+1} \mid w_i, f_1, \dots, f_i)P(w_i \mid f_1, \dots, f_i)\]Observando que \(P(w_i \mid f_1, \dots, f_i)\) es simplemente \(B(w_i)\) y que \(W_{i+1} \perp \{f_1, \dots f_i\} \mid W_i\), esto se simplifica a nuestra relación final entre \(B(W_i)\) y \(B'(W_{i+1})\):
\[\boxed{B'(W_{i+1}) = \sum_{w_i}P(W_{i+1} \mid w_i)B(w_i)}\]Ahora consideremos cómo podemos derivar una relación entre \(B'(W_{i+1})\) y \(B(W_{i+1})\). Mediante la aplicación de la definición de probabilidad condicional (con condicionamiento adicional), podemos ver que \(B(W_{i+1}) = P(W_{i+1} | f_1, ..., f_{i+1}) = \frac{P(W_{i+1}, f_{i+1} | f_1, ..., f_i)}{P(f_{i+1} | f_1, ..., f_i)}\) Cuando se trata de probabilidades condicionales, un truco comúnmente utilizado es retrasar la normalización hasta que necesitemos las probabilidades normalizadas, un truco que emplearemos ahora. Más específicamente, dado que el denominador en la expansión anterior de \(B(W_{i+1})\) es común a cada término en la tabla de probabilidad representada por \(B(W_{i+1})\), podemos omitir dividir realmente por \(P(f_{i+1} | f_1, ..., f_i)\). En cambio, simplemente podemos notar que \(B(W_{i+1})\) es proporcional a \(P(W_{i+1}, f_{i+1} | f_1, ..., f_i)\): \(B(W_{i+1}) \propto P(W_{i+1}, f_{i+1} | f_1, ..., f_i)\) con una constante de proporcionalidad igual a \(P(f_{i+1} | f_1, ..., f_i)\). Siempre que decidamos que queremos recuperar la distribución de creencias \(B(W_{i+1})\), podemos dividir cada valor calculado por esta constante de proporcionalidad. Ahora, usando la regla de la cadena podemos observar lo siguiente: \(B(W_{i+1}) \propto P(W_{i+1}, f_{i+1} | f_1, ..., f_i) = P(f_{i+1} | W_{i+1}, f_1, ..., f_i)P(W_{i+1} | f_1, ..., f_i)\) Por las suposiciones de independencia condicional asociadas con los Modelos Ocultos de Markov establecidas anteriormente, \(P(f_{i+1} | W_{i+1}, f_1, ..., f_i)\) es equivalente a simplemente \(P(f_{i+1} | W_{i+1})\) y por definición \(P(W_{i+1} | f_1, ..., f_i) = B'(W_{i+1})\). Esto nos permite expresar la relación entre \(B'(W_{i+1})\) y \(B(W_{i+1})\) en su forma final: \(\boxed{B(W_{i+1}) \propto P(f_{i+1} | W_{i+1})B'(W_{i+1})}\) Combinando las dos relaciones que acabamos de derivar se obtiene un algoritmo iterativo conocido como el algoritmo forward, el análogo del Modelo Oculto de Markov del algoritmo mini-forward de antes: \(\boxed{B(W_{i+1}) \propto P(f_{i+1} | W_{i+1})\sum_{w_i}P(W_{i+1} | w_i)B(w_i)}\) El algoritmo forward se puede considerar como compuesto por dos pasos distintivos: la actualización de lapso de tiempo, que corresponde a determinar \(B'(W_{i+1})\) a partir de \(B(W_i)\), y la actualización de observación, que corresponde a determinar \(B(W_{i+1})\) a partir de \(B'(W_{i+1})\). Por lo tanto, para avanzar nuestra distribución de creencias en un paso de tiempo (es decir, calcular \(B(W_{i+1})\) a partir de \(B(W_i)\)), primero debemos avanzar el estado de nuestro modelo en un paso de tiempo con la actualización de lapso de tiempo, luego incorporar nueva evidencia de ese paso de tiempo con la actualización de observación. Considere la siguiente distribución inicial, modelo de transición y modelo de sensor:
| \(W_0\) | \(B(W_0)\) |
|---|---|
| sol | 0.8 |
| lluvia | 0.2 |
| \(W_{i+1}\) | \(W_i\) | \(P(W_{i+1} \mid W_i)\) |
|---|---|---|
| sol | sol | 0.6 |
| lluvia | sol | 0.4 |
| sol | lluvia | 0.1 |
| lluvia | lluvia | 0.9 |
| \(F_i\) | \(W_i\) | \(P(F_i \mid W_i)\) |
|---|---|---|
| bueno | sol | 0.8 |
| malo | sol | 0.2 |
| bueno | lluvia | 0.3 |
| malo | lluvia | 0.7 |
Para calcular \(B(W_1)\), comenzamos realizando una actualización de tiempo para obtener \(B'(W_1)\):
\[B'(W_1 = sol) = \sum_{w_0}P(W_1 = sol | w_0)B(w_0) = P(W_1 = sol | W_0 = sol)B(W_0 = sol) + P(W_1 = sol | W_0 = lluvia)B(W_0 = lluvia)\] \[B'(W_1 = sol) = 0.6 \cdot 0.8 + 0.1 \cdot 0.2 = \boxed{0.5}\] \[B'(W_1 = lluvia) = \sum_{w_0}P(W_1 = lluvia | w_0)B(w_0) = P(W_1 = lluvia | W_0 = sol)B(W_0 = sol) + P(W_1 = lluvia | W_0 = lluvia)B(W_0 = lluvia)\] \[B'(W_1 = lluvia) = 0.4 \cdot 0.8 + 0.9 \cdot 0.2 = \boxed{0.5}\]Por lo tanto:
| \(W_1\) | \(B'(W_1)\) |
|---|---|
| sol | 0.5 |
| lluvia | 0.5 |
A continuación, asumiremos que el pronóstico del tiempo para el día 1 fue bueno (es decir, \(F_1 = bueno\)), y realizaremos una actualización de observación para obtener \(B(W_1)\):
\[B(W_1 = sol) \propto P(F_1 = bueno | W_1 = sol)B'(W_1 = sol) = 0.8 \cdot 0.5 = \boxed{0.4}\] \[B(W_1 = lluvia) \propto P(F_1 = bueno | W_1 = lluvia)B'(W_1 = lluvia) = 0.3 \cdot 0.5 = \boxed{0.15}\]El último paso es normalizar \(B(W_1)\), observando que las entradas en la tabla para \(B(W_1)\) suman \(0.4 + 0.15 = 0.55\):
\[B(W_1 = sol) = 0.4 / 0.55 = \frac{8}{11}\] \[B(W_1 = lluvia) = 0.15 / 0.55 = \frac{3}{11}\]Nuestra tabla final para \(B(W_1)\) es, por lo tanto, la siguiente:
| \(W_1\) | \(B(W_1)\) |
|---|---|
| sol | \(\frac{8}{11}\) |
| lluvia | \(\frac{3}{11}\) |
Tenga en cuenta el resultado de observar el pronóstico del tiempo. Debido a que el meteorólogo predijo buen tiempo, nuestra creencia de que estaría soleado aumentó de \(\frac{1}{2}\) después de la actualización de tiempo a \(\frac{8}{11}\) después de la actualización de observación.
Como nota de despedida, el truco de normalización discutido anteriormente puede simplificar significativamente el cálculo cuando se trabaja con Modelos Ocultos de Markov. Si comenzamos con alguna distribución inicial y estuviéramos interesados en calcular la distribución de creencias en el tiempo \(t\), podríamos usar el algoritmo forward para calcular iterativamente \(B(W_1), ..., B(W_t)\) y normalizar solo una vez al final dividiendo cada entrada en la tabla para \(B(W_t)\) por la suma de sus entradas.