5.1 Aprendizaje por Refuerzo
En la nota anterior, discutimos los procesos de decisión de Markov, que resolvimos utilizando técnicas como la iteración de valor y la iteración de políticas para calcular los valores óptimos de los estados y extraer políticas óptimas. Resolver procesos de decisión de Markov es un ejemplo de planificación fuera de línea, donde los agentes tienen pleno conocimiento tanto de la función de transición como de la función de recompensa, toda la información que necesitan para precalcular acciones óptimas en el mundo codificado por el MDP sin realizar ninguna acción.
En esta nota, discutiremos la planificación en línea, durante la cual un agente no tiene conocimiento previo de las recompensas o transiciones en el mundo (aún representado como un MDP). En la planificación en línea, un agente debe intentar la exploración, durante la cual realiza acciones y recibe retroalimentación en forma de los estados sucesores a los que llega y las recompensas correspondientes que obtiene. El agente utiliza esta retroalimentación para estimar una política óptima a través de un proceso conocido como aprendizaje por refuerzo antes de usar esta política estimada para la explotación o maximización de recompensas.
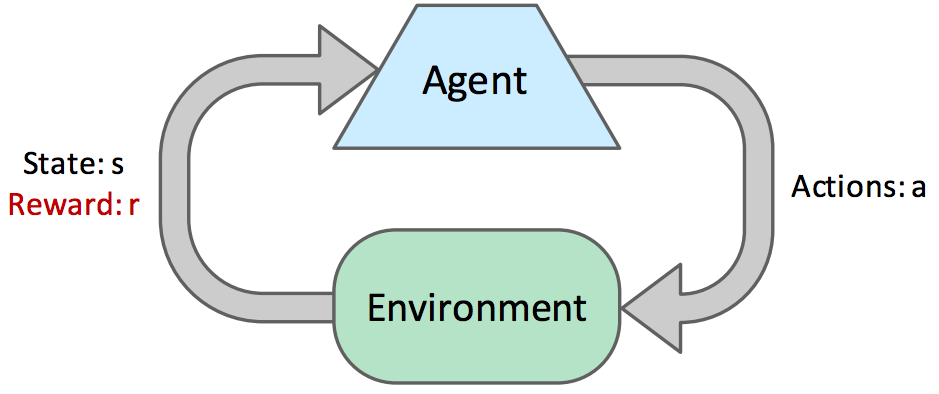
Comencemos con alguna terminología básica. En cada paso de tiempo durante la planificación en línea, un agente comienza en un estado \(s\), luego toma una acción \(a\) y termina en un estado sucesor \(s'\), obteniendo alguna recompensa \(r\). Cada tupla \((s, a, s', r)\) se conoce como una muestra. A menudo, un agente continúa tomando acciones y recolectando muestras en sucesión hasta llegar a un estado terminal. Tal colección de muestras se conoce como un episodio. Los agentes suelen pasar por muchos episodios durante la exploración para recopilar suficientes datos necesarios para el aprendizaje.
Hay dos tipos de aprendizaje por refuerzo, aprendizaje basado en modelos y aprendizaje libre de modelos. El aprendizaje basado en modelos intenta estimar las funciones de transición y recompensa con las muestras obtenidas durante la exploración antes de usar estas estimaciones para resolver el MDP normalmente con iteración de valor o política. El aprendizaje libre de modelos, por otro lado, intenta estimar los valores o valores Q de los estados directamente, sin usar ninguna memoria para construir un modelo de las recompensas y transiciones en el MDP.