1.5 Local Search (局部搜索)
在上一节中,我们想要找到目标状态,以及到达那里的最佳路径。但在某些问题中,我们只关心找到目标状态——重建路径可能是微不足道的。例如,在数独中,最佳配置就是目标。一旦你知道了它,你就知道如何通过逐个填充方块来到达那里。
局部搜索算法允许我们在不担心到达路径的情况下找到目标状态。在局部搜索问题中,状态空间由“完整”解决方案的集合组成。我们使用这些算法来尝试找到满足某些约束或优化某些目标函数的配置。
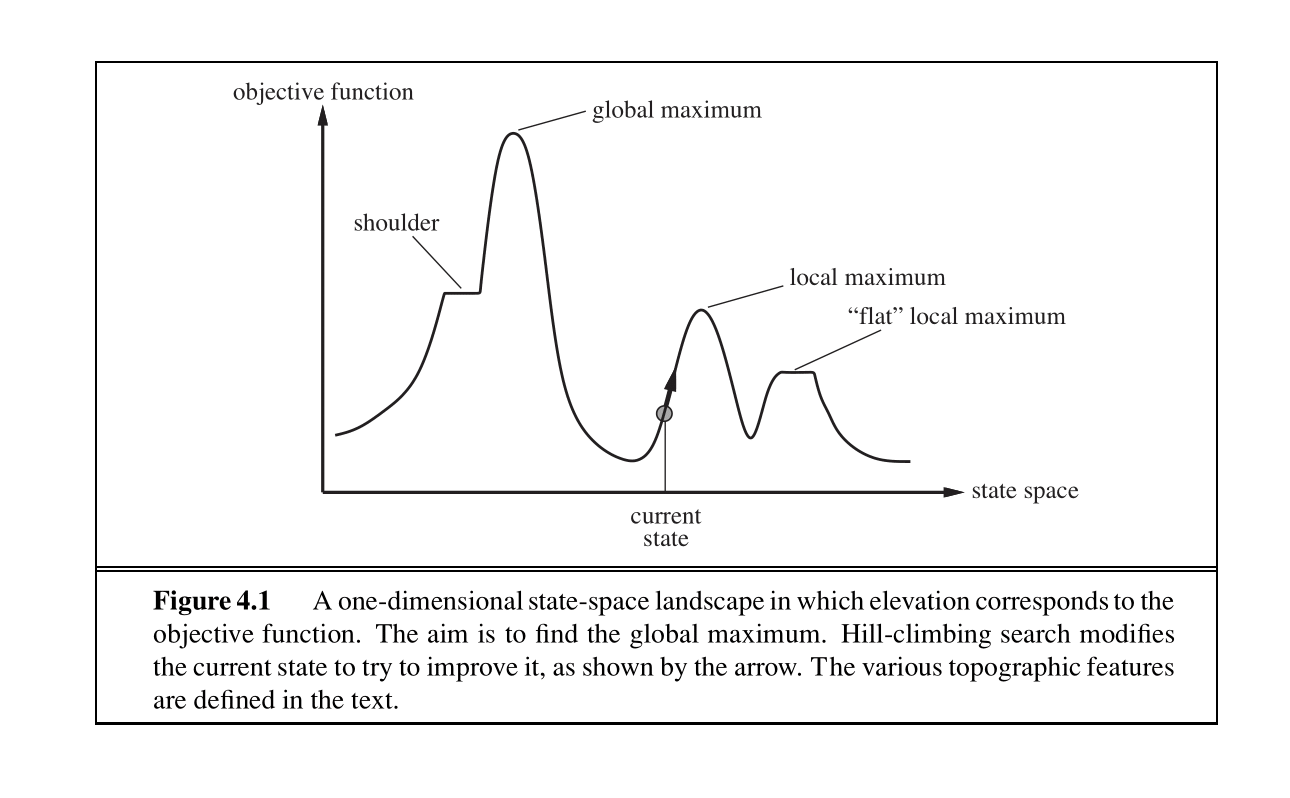
上图显示了状态空间上目标函数的一维图。对于该函数,我们希望找到对应于最高目标值的状态。局部搜索算法的基本思想是,从每个状态开始,它们局部地向具有更高目标值的状态移动,直到达到最大值(希望是全局最大值)。我们将介绍四种这样的算法:hill-climbing(爬山法)、simulated annealing(模拟退火)、local beam search(局部束搜索)和 genetic algorithms(遗传算法)。所有这些算法也用于优化任务,以最大化或最小化目标函数。
1.5.1 Hill-Climbing Search (爬山搜索)
爬山搜索算法(或 steepest-ascent(最陡上升))从当前状态向增加目标值最多的相邻状态移动。该算法不维护搜索树,只跟踪状态和相应的目标值。爬山法的“贪婪”使其容易陷入 local maxima(局部最大值)(见图 4.1),因为在局部这些点对算法来说就像全局最大值,以及 plateaus(高原)(见图 4.1)。高原可以分为“平坦”区域(没有方向导致改进,“平坦局部最大值”)或进展缓慢的平坦区域(“肩部”)。
爬山法的变体,如 stochastic hill-climbing(随机爬山法)(在可能的上坡移动中随机选择一个动作),已经被提出。随机爬山法在实践中已被证明可以收敛到更高的最大值,但代价是更多的迭代。另一个变体,random sideways moves(随机侧向移动),允许不严格增加目标的移动,帮助算法逃离“肩部”。
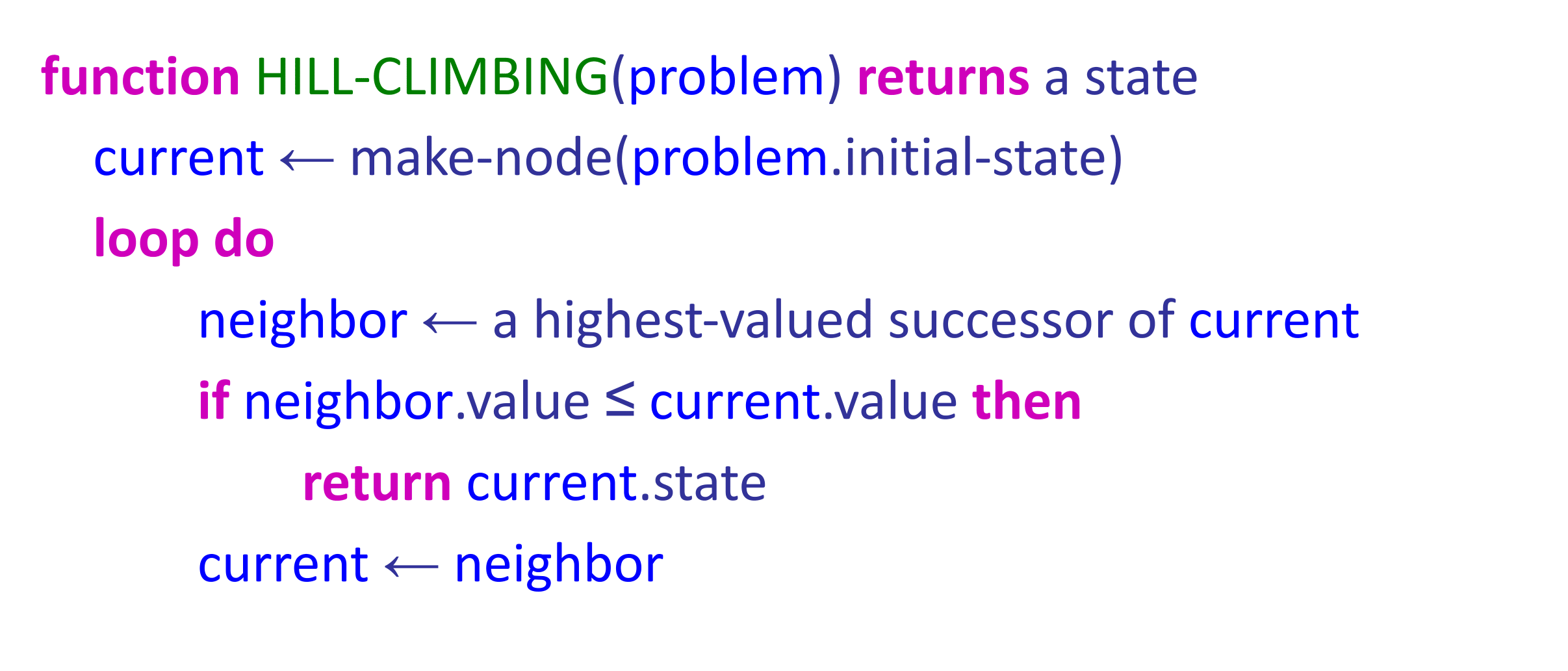
爬山法的伪代码如上所示。顾名思义,该算法迭代地移动到具有更高目标值的状态,直到无法取得此类进展。爬山法是不完备的。另一方面,Random-restart hill-climbing(随机重启爬山法)从随机选择的初始状态进行多次爬山搜索,使其在某种意义上是完备的,因为在某个时刻,随机选择的初始状态可能会收敛到全局最大值。
作为一个注记,在本课程的后面,你将遇到术语“梯度下降”。它与爬山法是完全相同的想法,只是我们想要最小化成本函数而不是最大化目标函数。
1.5.2 Simulated Annealing Search (模拟退火搜索)
我们将介绍的第二个局部搜索算法是模拟退火。模拟退火旨在结合随机游走(随机移动到附近状态)和爬山法,以获得完备且高效的搜索算法。在模拟退火中,我们允许移动到可能降低目标的状态。
该算法在每个时间步选择一个随机移动。如果移动导致更高的目标值,则总是被接受。如果它导致更小的目标值,则以一定的概率接受该移动。这个概率由温度参数决定,该参数最初很高(允许更多“坏”移动),并根据某种“时间表”降低。理论上,如果温度降低得足够慢,模拟退火算法将以接近 1 的概率达到全局最大值。

1.5.3 Local Beam Search (局部束搜索)
局部束搜索是爬山搜索算法的另一个变体。两者之间的主要区别在于,局部束搜索在每次迭代中跟踪 \(k\) 个状态(线程)。该算法从随机初始化的 \(k\) 个状态开始,并且在每次迭代中,它选择 \(k\) 个新状态,就像在爬山法中所做的那样。这些不仅仅是常规爬山算法的 \(k\) 个副本。至关重要的是,该算法从所有线程的所有后继状态的完整列表中选择 \(k\) 个最佳后继状态。如果任何线程找到最优值,算法就会停止。
这 \(k\) 个线程可以在它们之间共享信息,允许“好”线程(目标值高)将其他线程也“吸引”到该区域。
局部束搜索也容易像爬山法一样陷入“平坦”区域。Stochastic beam search(随机束搜索),类似于随机爬山法,可以缓解这个问题。
1.5.4 Genetic Algorithms (遗传算法)
最后,我们介绍 genetic algorithms(遗传算法),它是局部束搜索的一种变体,广泛用于许多优化任务。正如名称所示,遗传算法从进化中汲取灵感。遗传算法开始时作为具有 \(k\) 个随机初始化状态的束搜索,称为 population(种群)。状态(称为 individuals(个体))表示为有限字母表上的字符串。
让我们回顾一下讲座中介绍的 \(8\)-Queens problem(八皇后问题)。作为回顾,八皇后问题是一个约束满足问题,我们的目标是将 \(8\) 个皇后放置在 \(8\)-by-\(8\) 的棋盘上。满足约束的解决方案将没有任何 attacking pairs(攻击对)皇后,即处于同一行、列或对角线上的皇后。所有前面介绍的算法都可以用来解决八皇后问题。

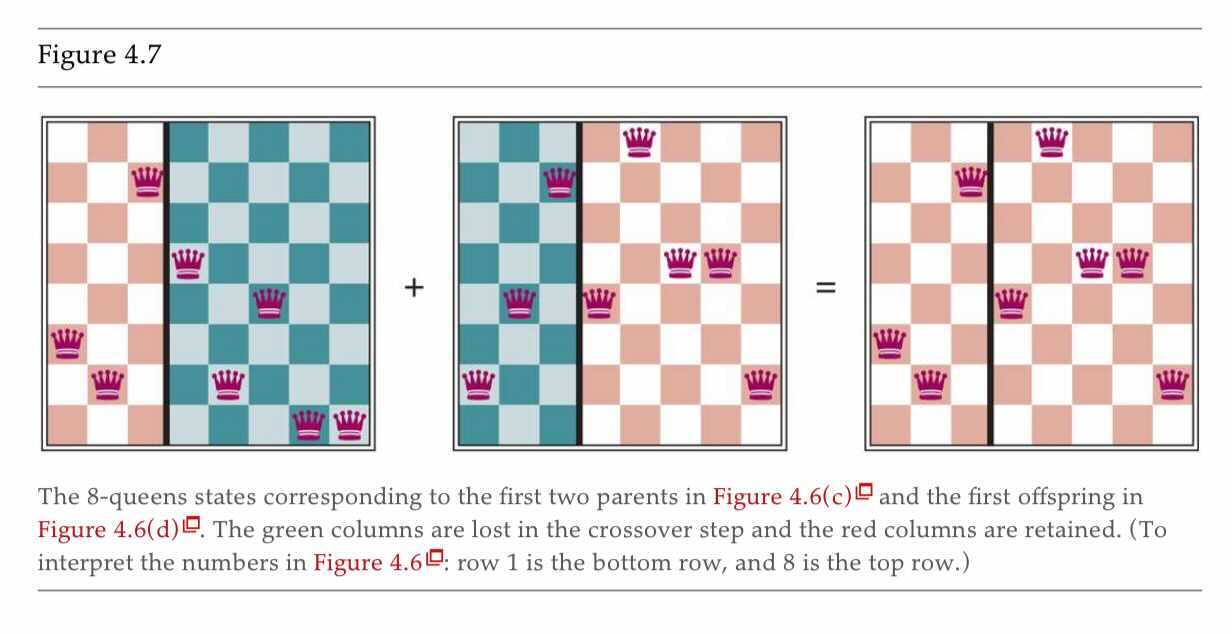
对于遗传算法,我们用 \(1-8\) 的数字表示八个皇后中的每一个,表示每个皇后在其列中的位置(图 4.6 中的列 (a))。每个个体都使用评估函数(fitness function(适应度函数))进行评估,并根据该函数的值对它们进行排名。对于八皇后问题,这是不攻击(不冲突)皇后对的数量。
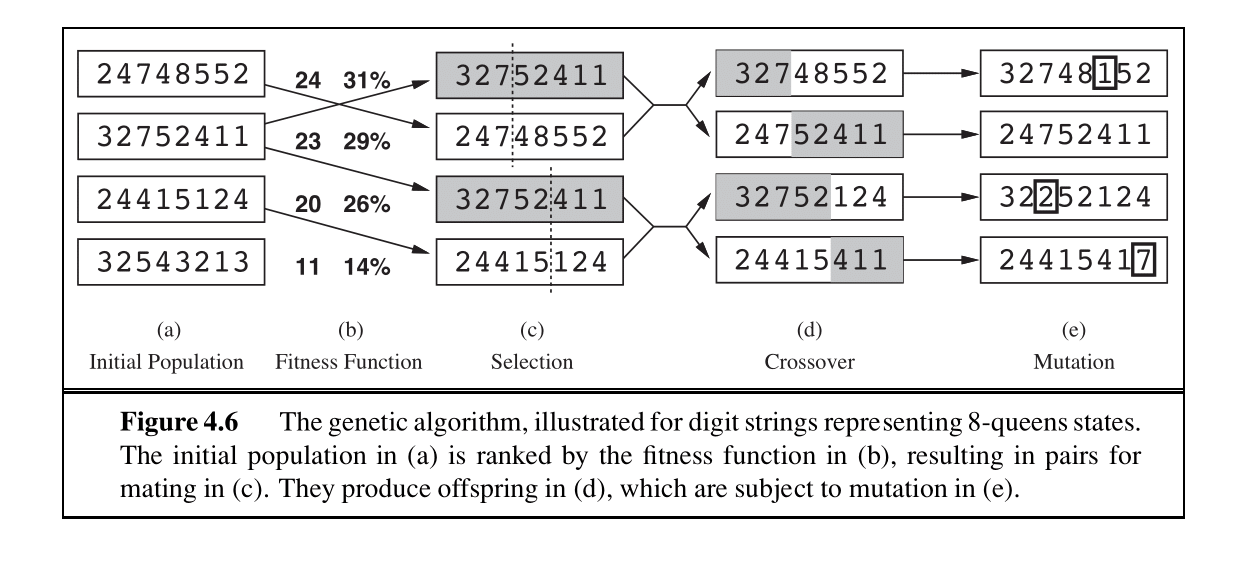
选择一个状态进行“繁殖”的概率与该状态的值成正比。我们继续通过从这些概率中采样来选择要繁殖的状态对(图 4.6 中的列 (c))。后代是通过在交叉点交叉父字符串生成的。每个对的交叉点是随机选择的。最后,每个后代都容易以独立概率发生某种随机突变。遗传算法的伪代码如下所示。

类似于随机束搜索,遗传算法试图在上坡的同时探索状态空间并在线程之间交换信息。它们的主要优势是使用交叉——已经进化并导致高估值的字母大块可以与其他此类块组合以产生具有高总分的解决方案。