1.4 Búsqueda informada
La búsqueda de costo uniforme es buena porque es completa y óptima, pero puede ser bastante lenta porque se expande en todas las direcciones desde el estado inicial mientras busca un objetivo. Si tenemos alguna noción de la dirección en la que debemos enfocar nuestra búsqueda, podemos mejorar significativamente el rendimiento y “afinar” un objetivo mucho más rápidamente. Este es exactamente el enfoque de la búsqueda informada.
1.4.1 Heurísticas
Las heurísticas son la fuerza impulsora que permite la estimación de la distancia a los estados objetivo: son funciones que toman un estado como entrada y generan una estimación correspondiente. El cálculo realizado por dicha función es específico del problema de búsqueda que se está resolviendo. Por razones que veremos en la búsqueda A* a continuación, generalmente queremos que las funciones heurísticas sean un límite inferior de esta distancia restante al objetivo, por lo que las heurísticas suelen ser soluciones a problemas relajados (donde se han eliminado algunas de las restricciones del problema original). Volviendo a nuestro ejemplo de Pacman, consideremos el problema de ruta descrito anteriormente. Una heurística común que se usa para resolver este problema es la distancia de Manhattan, que para dos puntos (\(x_1\), \(y_1\)) y (\(x_2\), \(y_2\)) se define de la siguiente manera:
\[Manhattan(x_1, y_1, x_2, y_2) = |x_1 - x_2| + |y_1 - y_2|\]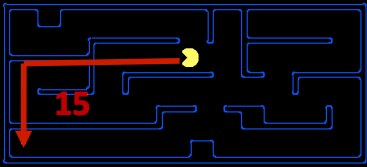
La visualización anterior muestra el problema relajado que la distancia de Manhattan ayuda a resolver: asumiendo que Pacman desea llegar a la esquina inferior izquierda del laberinto, calcula la distancia desde la ubicación actual de Pacman hasta la ubicación deseada de Pacman asumiendo la ausencia de paredes en el laberinto. Esta distancia es la distancia exacta al objetivo en el problema de búsqueda relajado y, correspondientemente, es la distancia estimada al objetivo en el problema de búsqueda real. Con las heurísticas, se vuelve muy fácil implementar lógica en nuestro agente que les permita “preferir” expandir estados que se estima que están más cerca de los estados objetivo al decidir qué acción realizar. Este concepto de preferencia es muy poderoso y es utilizado por los siguientes dos algoritmos de búsqueda que implementan funciones heurísticas: búsqueda voraz y A*.
1.4.2 Búsqueda voraz (Greedy Search)
- Descripción - La búsqueda voraz es una estrategia de exploración que siempre selecciona el nodo de frontera con el valor heurístico más bajo para la expansión, lo que corresponde al estado que cree que está más cerca de un objetivo.
- Representación de la frontera - La búsqueda voraz funciona de manera idéntica a UCS, con una representación de frontera de cola de prioridad. La diferencia es que en lugar de usar el costo hacia atrás calculado (la suma de los pesos de los bordes en el camino al estado) para asignar prioridad, la búsqueda voraz usa el costo hacia adelante estimado en forma de valores heurísticos.
- Completitud y Optimalidad - No se garantiza que la búsqueda voraz encuentre un estado objetivo si existe uno, ni es óptima, particularmente en casos donde se selecciona una función heurística muy mala. Generalmente actúa de manera bastante impredecible de un escenario a otro, y puede variar desde ir directamente a un estado objetivo hasta actuar como un DFS mal guiado y explorar todas las áreas incorrectas.
1.4.3 Búsqueda A*
- Descripción - La búsqueda A* es una estrategia de exploración que siempre selecciona el nodo de frontera con el costo total estimado más bajo para la expansión, donde el costo total es el costo completo desde el nodo inicial hasta el nodo objetivo.
- Representación de la frontera - Al igual que la búsqueda voraz y UCS, la búsqueda A* también utiliza una cola de prioridad para representar su frontera. Nuevamente, la única diferencia es el método de selección de prioridad. A* combina el costo total hacia atrás (suma de los pesos de los bordes en el camino al estado) utilizado por UCS con el costo hacia adelante estimado (valor heurístico) utilizado por la búsqueda voraz sumando estos dos valores, produciendo efectivamente un costo total estimado desde el inicio hasta el objetivo. Dado que queremos minimizar el costo total desde el inicio hasta el objetivo, esta es una excelente opción.
- Completitud y Optimalidad - La búsqueda A* es completa y óptima, dada una heurística adecuada (que cubriremos en un minuto). ¡Es una combinación de lo bueno de todas las otras estrategias de búsqueda que hemos cubierto hasta ahora, incorporando la velocidad generalmente alta de la búsqueda voraz con la optimalidad y completitud de UCS!
1.4.4. Admisibilidad
Ahora que hemos discutido las heurísticas y cómo se aplican tanto en la búsqueda voraz como en la búsqueda A, dediquemos un tiempo a discutir qué constituye una buena heurística. Para hacerlo, primero reformulemos los métodos utilizados para determinar el orden de la cola de prioridad en UCS, búsqueda voraz y A con las siguientes definiciones:
- \(g(n)\) - La función que representa el costo total hacia atrás calculado por UCS.
- \(h(n)\) - La función de valor heurístico, o costo hacia adelante estimado, utilizada por la búsqueda voraz.
- \(f(n)\) - La función que representa el costo total estimado, utilizada por la búsqueda A*. \(f(n) = g(n) + h(n)\).
Antes de atacar la pregunta de qué constituye una “buena” heurística, primero debemos responder a la pregunta de si A* mantiene sus propiedades de completitud y optimalidad independientemente de la función heurística que usemos. De hecho, es muy fácil encontrar heurísticas que rompan estas dos codiciadas propiedades. Como ejemplo, considere la función heurística \(h(n) = 1 - g(n)\). Independientemente del problema de búsqueda, el uso de esta heurística produce:
\[f(n) = g(n) + h(n) = g(n) + (1 - g(n)) = 1\]Por lo tanto, tal heurística reduce la búsqueda A* a BFS, donde todos los costos de los bordes son equivalentes. Como ya hemos demostrado, no se garantiza que BFS sea óptima en el caso general donde los pesos de los bordes no son constantes.
La condición requerida para la optimalidad cuando se usa la búsqueda en árbol A* se conoce como admisibilidad. La restricción de admisibilidad establece que el valor estimado por una heurística admisible no es negativo ni una sobreestimación. Definiendo \(h^*(n)\) como el costo óptimo verdadero hacia adelante para alcanzar un estado objetivo desde un nodo dado n, podemos formular la restricción de admisibilidad matemáticamente de la siguiente manera:
\[\forall n, 0 \leq h(n) \leq h^*(n)\]Teorema. Para un problema de búsqueda dado, si la restricción de admisibilidad es satisfecha por una función heurística h, el uso de la búsqueda en árbol A* con h en ese problema de búsqueda producirá una solución óptima.
Prueba. Supongamos que dos estados objetivo alcanzables se encuentran en el árbol de búsqueda para un problema de búsqueda dado, un objetivo óptimo \(A\) y un objetivo subóptimo \(B\). Algún antepasado \(n\) de \(A\) (incluyendo quizás \(A\) mismo) debe estar actualmente en la frontera, ya que \(A\) es alcanzable desde el estado inicial. Afirmamos que \(n\) será seleccionado para expansión antes que \(B\), utilizando las siguientes tres declaraciones:
- \(g(A) < g(B)\). Porque se da que \(A\) es óptimo y \(B\) es subóptimo, podemos concluir que \(A\) tiene un costo hacia atrás menor al estado inicial que \(B\).
- \(h(A) = h(B) = 0\), porque se nos da que nuestra heurística satisface la restricción de admisibilidad. Dado que tanto \(A\) como \(B\) son estados objetivo, el costo óptimo verdadero a un estado objetivo desde \(A\) o \(B\) es simplemente \(h^*(n) = 0\); por lo tanto \(0 \leq h(n) \leq 0\).
- \(f(n) \leq f(A)\), porque, a través de la admisibilidad de \(h\), \(f(n)=g(n)+h(n) \leq g(n) + h^*(n) = g(A) = f(A)\). El costo total a través del nodo \(n\) es como máximo el costo verdadero hacia atrás de \(A\), que también es el costo total de \(A\).
Podemos combinar las declaraciones 1. y 2. para concluir que \(f(A) < f(B)\) de la siguiente manera:
\[f(A) = g(A) + h(A) = g(A) < g(B) = g(B) + h(B) = f(B)\]Una consecuencia simple de combinar la desigualdad derivada anterior con la declaración 3. es la siguiente:
\[f(n) \leq f(A) \land f(A) < f(B) \rightarrow f(n) < f(B)\]Por lo tanto, podemos concluir que \(n\) se expande antes que \(B\). Debido a que hemos demostrado esto para \(n\) arbitrario, podemos concluir que todos los antepasados de \(A\) (incluido \(A\) mismo) se expanden antes que \(B\).
Un problema que encontramos anteriormente con la búsqueda en árbol fue que en algunos casos podría fallar en encontrar una solución, quedándose atascada buscando el mismo ciclo en el grafo del espacio de estados infinitamente. Incluso en situaciones donde nuestra técnica de búsqueda no implica tal bucle infinito, a menudo es el caso de que volvemos a visitar el mismo nodo varias veces porque hay múltiples formas de llegar a ese mismo nodo. Esto conduce a un trabajo exponencialmente mayor, y la solución natural es simplemente realizar un seguimiento de qué estados ya ha expandido y nunca volver a expandirlos. Más explícitamente, mantenga un conjunto “alcanzado” de nodos expandidos mientras utiliza su método de búsqueda de elección. Luego, asegúrese de que cada nodo no esté ya en el conjunto antes de la expansión y agréguelo al conjunto después de la expansión si no lo está. La búsqueda en árbol con esta optimización agregada se conoce como búsqueda en grafo.1 Además, hay otro factor clave que se requiere para mantener la optimalidad. Considere el siguiente grafo de espacio de estados simple y el árbol de búsqueda correspondiente, anotado con pesos y valores heurísticos:
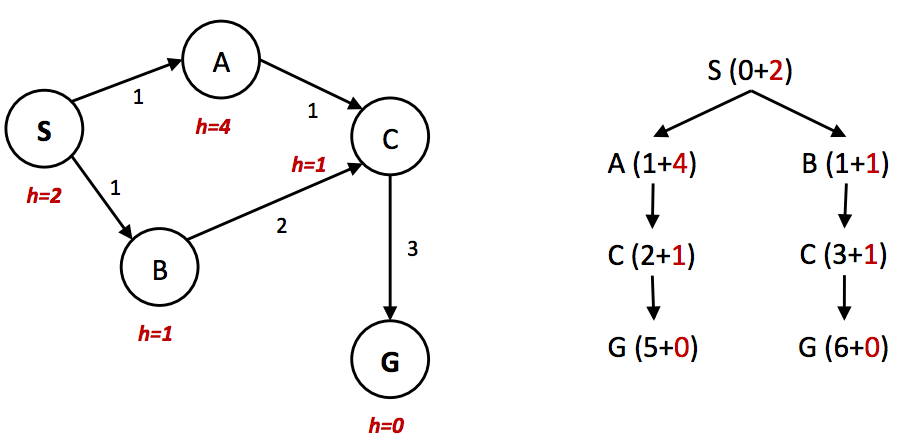
En el ejemplo anterior, está claro que la ruta óptima es seguir \(S → A → C → G\), produciendo un costo total de ruta de 1 + 1 + 3 = 5. La única otra ruta al objetivo, \(S → B → C → G\) tiene un costo de ruta de 1 + 2 + 3 = 6. Sin embargo, debido a que el valor heurístico del nodo A es mucho mayor que el valor heurístico del nodo \(B\), el nodo \(C\) se expande primero a lo largo de la segunda ruta subóptima como hijo del nodo \(B\). Luego se coloca en el conjunto “alcanzado”, por lo que la búsqueda en grafo A* no lo vuelve a expandir cuando lo visita como hijo de \(A\), por lo que nunca encuentra la solución óptima. Por lo tanto, para mantener la optimalidad bajo la búsqueda en grafo A, no solo necesitamos verificar si A ya ha visitado un nodo, sino también si ha encontrado un camino más barato hacia él.
function A*-GRAPH-SEARCH(problem, frontier) return a solution or failure
reached ← an empty dict mapping nodes to the cost to each one
frontier ← INSERT((MAKE-NODE(INITIAL-STATE[problem]),0), frontier)
while not IS-EMPTY(frontier) do
node, node.CostToNode ← POP(frontier)
if problem.IS-GOAL(node.STATE) then return node
if node.STATE is not in reached or reached[node.STATE] > node.CostToNode then
reached[node.STATE] = node.CostToNode
for each child-node in EXPAND(problem, node) do
frontier ← INSERT((child-node, child-node.COST + CostToNode), frontier)
return failure
Tenga en cuenta que en la implementación, es críticamente importante almacenar el conjunto alcanzado como un conjunto disjunto y no como una lista. Almacenarlo como una lista requiere costos de \(O(n)\) operaciones para verificar la pertenencia, lo que elimina la mejora de rendimiento que la búsqueda en grafo pretende proporcionar.
Un par de puntos destacados importantes de la discusión anterior antes de continuar: para que las heurísticas que son admisibles sean válidas, debe ser por definición el caso de que \(h(G) = 0\) para cualquier estado objetivo \(G\).
1.4.5 Dominancia
Ahora que hemos establecido la propiedad de admisibilidad y su papel en el mantenimiento de la optimalidad de la búsqueda A*, podemos volver a nuestro problema original de crear “buenas” heurísticas y cómo saber si una heurística es mejor que otra. La métrica estándar para esto es la de dominancia. Si la heurística \(a\) es dominante sobre la heurística \(b\), entonces la distancia estimada al objetivo para \(a\) es mayor que la distancia estimada al objetivo para \(b\) para cada nodo en el grafo del espacio de estados. Matemáticamente,
\[\forall n: h_a(n) \geq h_b(n)\]La dominancia captura muy intuitivamente la idea de que una heurística es mejor que otra: si una heurística admisible es dominante sobre otra, debe ser mejor porque siempre estimará más de cerca la distancia a un objetivo desde cualquier estado dado. Además, la heurística trivial se define como \(h(n) = 0\), y su uso reduce la búsqueda A* a UCS. Todas las heurísticas admisibles dominan la heurística trivial. La heurística trivial a menudo se incorpora en la base de un semirretículo para un problema de búsqueda, una jerarquía de dominancia de la cual se encuentra en la parte inferior. A continuación se muestra un ejemplo de un semirretículo que incorpora varias heurísticas \(h_a\), \(h_b\) y \(h_c\) que van desde la heurística trivial en la parte inferior hasta la distancia exacta al objetivo en la parte superior:
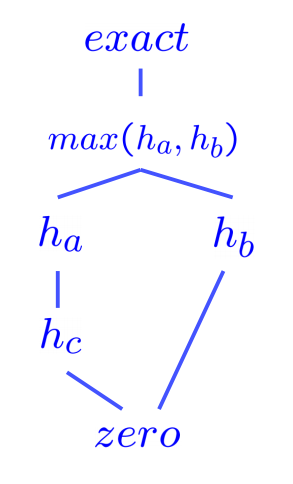
Como regla general, la función max aplicada a múltiples heurísticas admisibles también será siempre admisible. Esto es simplemente una consecuencia de que todos los valores generados por las heurísticas para cualquier estado dado están restringidos por la condición de admisibilidad, \(0 \leq h(n) \leq h^*(n)\). El máximo de números en este rango también debe caer en el mismo rango. Es una práctica común generar múltiples heurísticas admisibles para cualquier problema de búsqueda dado y calcular el máximo sobre los valores generados por ellas para generar una heurística que domine (y por lo tanto sea mejor que) todas ellas individualmente.
-
En otros cursos, como CS70 y CS170, es posible que se le haya introducido a “árboles” y “grafos” en el contexto de la teoría de grafos. Específicamente, un árbol es un tipo de grafo que satisface ciertas restricciones (conectado y acíclico). Esta no es la distinción entre búsqueda en árbol y búsqueda en grafo que hacemos en este curso. ↩