4.2 Resolver Procesos de Decisión de Markov
Recuerde que en la búsqueda determinista y no adversaria, resolver un problema de búsqueda significa encontrar un plan óptimo para llegar a un estado objetivo. Resolver un proceso de decisión de Markov, por otro lado, significa encontrar una política óptima \(\pi^*: S \rightarrow A\), una función que asigna cada estado \(s \in S\) a una acción \(a \in A\). Una política explícita \(\pi\) define un agente reflejo: dado un estado \(s\), un agente en \(s\) que implementa \(\pi\) seleccionará \(a = \pi(s)\) como la acción apropiada a realizar sin considerar las consecuencias futuras de sus acciones. Una política óptima es aquella que, si es seguida por el agente implementador, producirá la máxima recompensa o utilidad total esperada.
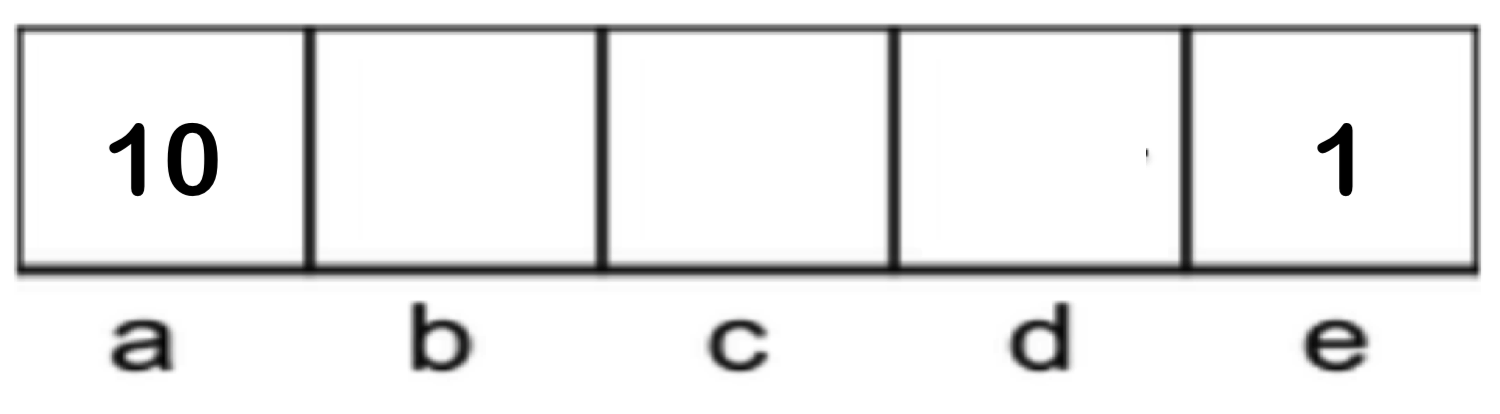
Considere el siguiente MDP con \(S = \{a, b, c, d, e\}\), \(A = \{Este, Oeste, Salir\}\) (con \(Salir\) siendo una acción válida solo en los estados \(a\) y \(e\) y produciendo recompensas de 10 y 1 respectivamente), un factor de descuento \(\gamma = 0.1\) y transiciones deterministas:
Dos políticas potenciales para este MDP son las siguientes:
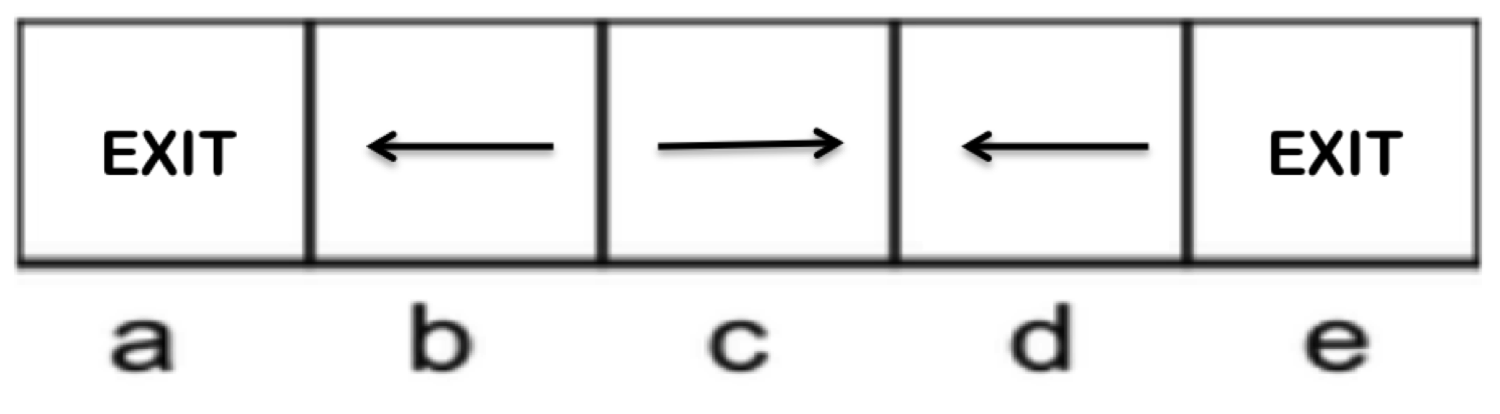 | 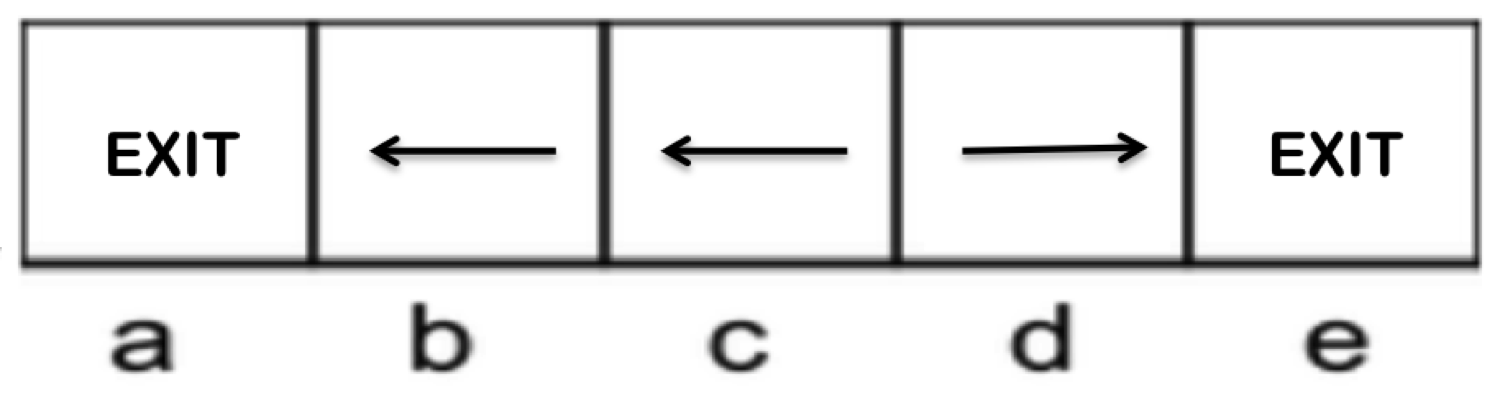 |
|---|---|
| Política 1 | Política 2 |
Con un poco de investigación, no es difícil determinar que la Política 2 es óptima. Seguir la política hasta realizar la acción \(a = Salir\) produce las siguientes recompensas para cada estado inicial:
| Estado Inicial | Recompensa |
|---|---|
| a | 10 |
| b | 1 |
| c | 0.1 |
| d | 0.1 |
| e | 1 |
Ahora aprenderemos a resolver tales MDP (¡y otros mucho más complejos!) algorítmicamente utilizando la ecuación de Bellman para procesos de decisión de Markov.
4.2.1 La ecuación de Bellman
Para hablar sobre la ecuación de Bellman para MDP, primero debemos introducir dos nuevas cantidades matemáticas:
- El valor óptimo de un estado \(s\), \(V^*(s)\) — el valor óptimo de \(s\) es el valor esperado de la utilidad que recibirá un agente que se comporta de manera óptima y comienza en \(s\), durante el resto de la vida del agente. Tenga en cuenta que con frecuencia en la literatura la misma cantidad se denota con \(V^*(s)\).
- El valor óptimo de un estado Q \((s, a)\), \(Q^*(s, a)\) — el valor óptimo de \((s, a)\) es el valor esperado de la utilidad que recibe un agente después de comenzar en \(s\), tomar \(a\) y actuar de manera óptima en adelante.
Usando estas dos nuevas cantidades y las otras cantidades de MDP discutidas anteriormente, la ecuación de Bellman se define de la siguiente manera:
\[V^*(s) = \max_a \sum_{s'}T(s, a, s')[R(s, a, s') + \gamma V^*(s')]\]Antes de comenzar a interpretar lo que esto significa, definamos también la ecuación para el valor óptimo de un estado Q (más comúnmente conocido como un valor Q óptimo):
\[Q^*(s, a) = \sum_{s'}T(s, a, s')[R(s, a, s') + \gamma V^*(s')]\]Tenga en cuenta que esta segunda definición nos permite volver a expresar la ecuación de Bellman como
\[V^*(s) = \max_a Q^*(s, a)\]que es una cantidad dramáticamente más simple. La ecuación de Bellman es un ejemplo de una ecuación de programación dinámica, una ecuación que descompone un problema en subproblemas más pequeños a través de una estructura recursiva inherente. Podemos ver esta recursividad inherente en la ecuación para el valor Q de un estado, en el término \([R(s, a, s') + \gamma V^*(s')]\). Este término representa la utilidad total que recibe un agente al tomar primero \(a\) desde \(s\) y llegar a \(s'\) y luego actuar de manera óptima en adelante. La recompensa inmediata de la acción \(a\) tomada, \(R(s, a, s')\), se suma a la suma descontada óptima de recompensas alcanzables desde \(s'\), \(V^*(s')\), que se descuenta por \(\gamma\) para tener en cuenta el paso de un paso de tiempo al tomar la acción \(a\). Aunque en la mayoría de los casos existe una gran cantidad de secuencias posibles de estados y acciones desde \(s'\) hasta algún estado terminal, todo este detalle se abstrae y encapsula en un solo valor recursivo, \(V^*(s')\).
Ahora podemos dar otro paso hacia afuera y considerar la ecuación completa para el valor Q. Sabiendo que \([R(s, a, s') + \gamma V^*(s')]\) representa la utilidad alcanzada al actuar de manera óptima después de llegar al estado \(s'\) desde el estado Q \((s, a)\), se hace evidente que la cantidad
\[\sum_{s'}T(s, a, s')[R(s, a, s') + \gamma V^*(s')]\]es simplemente una suma ponderada de utilidades, con cada utilidad ponderada por su probabilidad de ocurrencia. ¡Esto es, por definición, la utilidad esperada de actuar de manera óptima desde el estado Q \((s, a)\) en adelante! Esto completa nuestro análisis y nos da suficiente información para interpretar la ecuación de Bellman completa: el valor óptimo de un estado, \(V^*(s)\), es simplemente la utilidad esperada máxima sobre todas las acciones posibles desde \(s\). Calcular la utilidad esperada máxima para un estado \(s\) es esencialmente lo mismo que ejecutar expectimax: primero calculamos la utilidad esperada de cada estado Q \((s, a)\) (equivalente a calcular el valor de los nodos de azar), luego calculamos el máximo sobre estos nodos para calcular la utilidad esperada máxima (equivalente a calcular el valor de un nodo maximizador).
Una nota final sobre la ecuación de Bellman: su uso es como una condición para la optimalidad. En otras palabras, si de alguna manera podemos determinar un valor \(V(s)\) para cada estado \(s \in S\) tal que la ecuación de Bellman sea verdadera para cada uno de estos estados, podemos concluir que estos valores son los valores óptimos para sus respectivos estados. De hecho, satisfacer esta condición implica \(\forall s \in S, \: V(s) = V^*(s)\).