4.1 马尔可夫决策过程 (Markov Decision Processes)
马尔可夫决策过程由几个属性定义:
- 一组状态 \(S\)。MDPs 中的状态表示方式与传统搜索问题中的状态相同。
- 一组动作 \(A\)。MDPs 中的动作表示方式也与传统搜索问题中的相同。
- 一个开始状态。
- 可能有一个或多个终止状态。
- 可能有一个折扣因子 (discount factor) \(\gamma\)。我们稍后会介绍折扣因子。
- 一个转移函数 (transition function) \(T(s, a, s')\)。由于我们引入了非确定性动作的可能性,我们需要一种方法来描述从任何给定状态采取任何给定动作后可能结果的可能性。MDP 的转移函数正是做这个的——它是一个概率函数,表示代理从状态 \(s \in S\) 采取动作 \(a \in A\) 最终到达状态 \(s' \in S\) 的概率。
- 一个奖励函数 (reward function) \(R(s, a, s')\)。通常,MDPs 在每一步都设有小的“生存”奖励以奖励代理的生存,并在到达终止状态时给予大额奖励。奖励可以是正的也可以是负的,取决于它们是否对相关代理有利,代理的目标自然是在到达某个终止状态之前获得尽可能大的奖励。
为某种情况构建 MDP 与为搜索问题构建状态空间图非常相似,但有一些额外的注意事项。考虑赛车的激励示例:
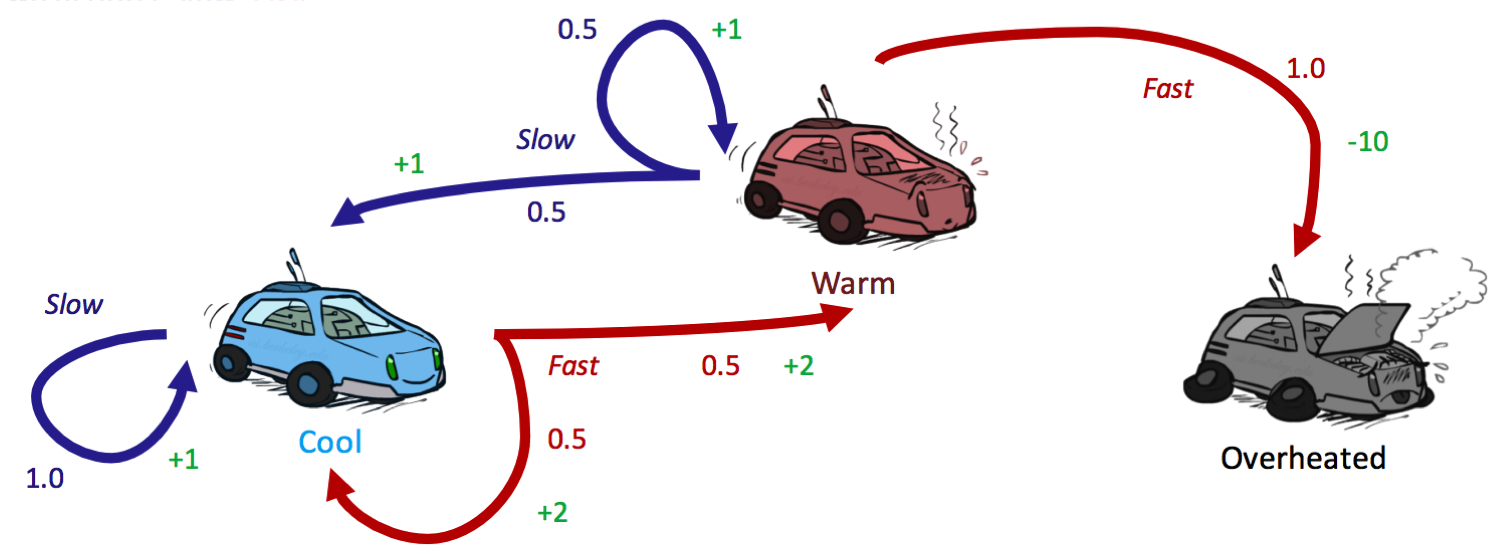
有三种可能的状态,\(S = \{cool, warm, overheated\}\),和两种可能的动作 \(A = \{slow, fast\}\)。就像在状态空间图中一样,三个状态中的每一个都由一个节点表示,边表示动作。Overheated 是一个终止状态,因为一旦赛车代理到达这个状态,它就不能再执行任何动作来获得进一步的奖励(它是 MDP 中的一个汇点状态 (sink state),没有出边)。值得注意的是,对于非确定性动作,从同一状态出发代表同一动作的边有多条,指向不同的后继状态。每条边不仅标注了它所代表的动作,还标注了转移概率和相应的奖励。这些总结如下:
转移函数: \(T(s, a, s')\)
- \[T(cool, slow, cool) = 1\]
- \[T(warm, slow, cool) = 0.5\]
- \[T(warm, slow, warm) = 0.5\]
- \[T(cool, fast, cool) = 0.5\]
- \[T(cool, fast, warm) = 0.5\]
- \[T(warm, fast, overheated) = 1\]
奖励函数: \(R(s, a, s')\)
- \[R(cool, slow, cool) = 1\]
- \[R(warm, slow, cool) = 1\]
- \[R(warm, slow, warm) = 1\]
- \[R(cool, fast, cool) = 2\]
- \[R(cool, fast, warm) = 2\]
- \[R(warm, fast, overheated) = -10\]
我们用离散的时间步 (timesteps) 来表示代理随时间在不同 MDP 状态中的移动,定义 \(s_t \in S\) 和 \(a_t \in A\) 分别为代理在时间步 \(t\) 所在的状态和采取的动作。代理在时间步 0 从状态 \(s_0\) 开始,并在每个时间步采取一个动作。因此,代理在 MDP 中的移动可以建模如下:
\[s_0 \xrightarrow{a_0} s_1 \xrightarrow{a_1} s_2 \xrightarrow{a_2} s_3 \xrightarrow{a_3}...\]此外,知道代理的目标是在所有时间步中最大化其奖励,我们可以相应地将其数学表达为最大化以下效用函数:
\[U([s_0, a_0, s_1, a_1, s_2, ...]) = R(s_0, a_0, s_1) + R(s_1, a_1, s_2) + R(s_2, a_2, s_3) + ...\]马尔可夫决策过程,像状态空间图一样,可以展开成搜索树。不确定性在这些搜索树中用 Q-状态 (Q-states)(也称为动作状态 (action states))建模,本质上与 expectimax 机会节点相同。这是一个恰当的选择,因为 Q-状态使用概率来模拟环境将代理置于给定状态的不确定性,就像 expectimax 机会节点使用概率来模拟对抗代理通过他们选择的移动将我们的代理置于给定状态的不确定性一样。表示从状态 \(s\) 采取动作 \(a\) 的 Q-状态记为元组 \((s, a)\)。
观察我们的赛车展开的搜索树,截断到深度 2:
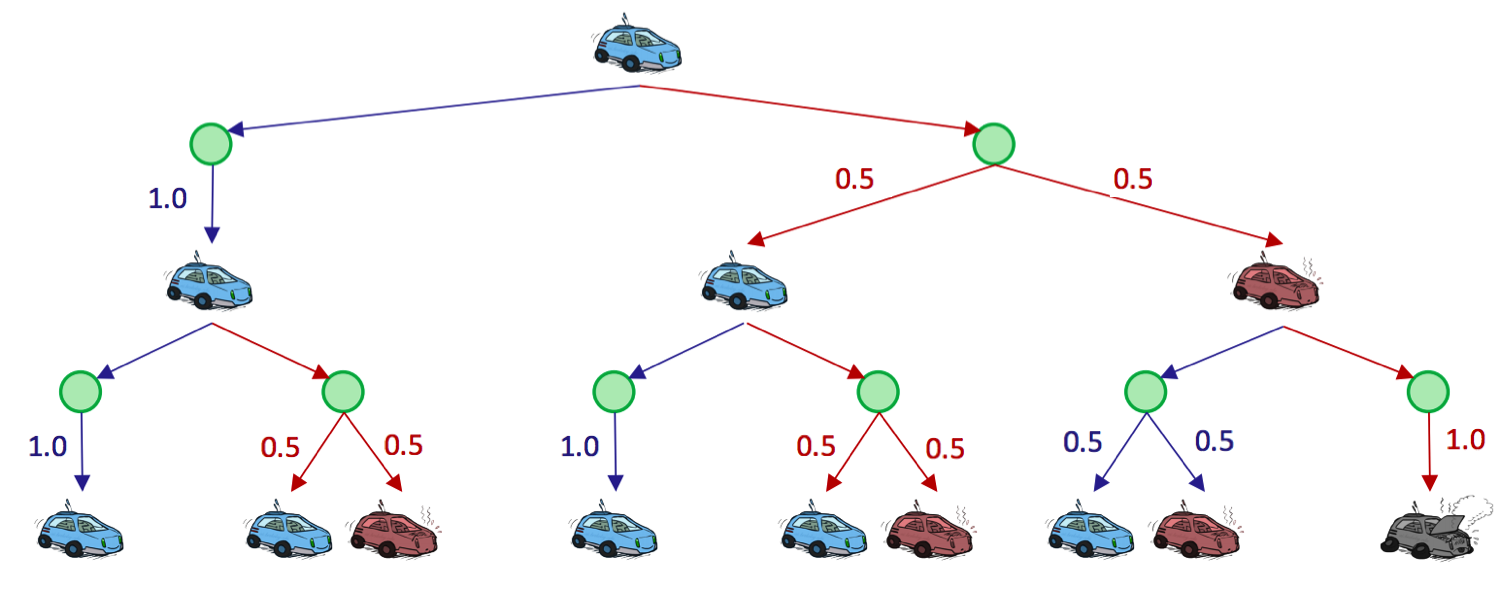
绿色节点表示 Q-状态,其中已从状态采取动作,但尚未解析为后继状态。重要的是要理解代理在 Q-状态中花费零个时间步,它们只是为了便于表示和开发 MDP 算法而创建的构造。
4.1.1 有限视界和折扣 (Finite Horizons and Discounting)
我们的赛车 MDP 存在一个固有的问题——我们没有对赛车可以采取动作和收集奖励的时间步数施加任何时间限制。按照目前的公式,它可以例行公事地在每个时间步永远选择 \(a = slow\),安全有效地获得无限奖励,而没有任何过热的风险。这通过引入有限视界 (finite horizons) 和/或 折扣因子 (discount factors) 来防止。强制执行有限视界的 MDP 很简单——它本质上定义了代理的“寿命”,这给了它们一定数量的时间步 \(n\) 来积累尽可能多的奖励,然后自动终止。我们将很快回到这个概念。
折扣因子稍微复杂一些,引入它是为了模拟奖励价值随时间呈指数衰减。具体来说,对于折扣因子 \(\gamma\),在时间步 \(t\) 从状态 \(s_t\) 采取动作 \(a_t\) 并最终到达状态 \(s_{t+1}\) 导致的奖励是 \(\gamma^t R(s_t, a_t, s_{t+1})\),而不是仅仅 \(R(s_t, a_t, s_{t+1})\)。现在,我们不再最大化加性效用 (additive utility)
\[U([s_0, a_0, s_1, a_1, s_2, ...]) = R(s_0, a_0, s_1) + R(s_1, a_1, s_2) + R(s_2, a_2, s_3) + ...\]而是尝试最大化折扣效用 (discounted utility)
\(U([s_0, a_0, s_1, a_1, s_2, ...]) = R(s_0, a_0, s_1) + \gamma R(s_1, a_1, s_2) + \gamma^2 R(s_2, a_2, s_3) + ...\)
注意到上述折扣效用函数的定义看起来类似于比率为 \(\gamma\) 的等比数列 (geometric series),我们可以证明只要满足约束 \(|\gamma| < 1\)(其中 \(|n|\) 表示绝对值运算符),它就保证是有限值的,逻辑如下:
\[U([s_0, s_1, s_2, ...]) = R(s_0, a_0, s_1) + \gamma R(s_1, a_1, s_2) + \gamma^2 R(s_2, a_2, s_3) + ...\] \[= \sum_{t=0}^{\infty} \gamma^t R(s_t, a_t, s_{t+1}) \leq \sum_{t=0}^{\infty} \gamma^t R_{max} = \boxed{\frac{R_{max}}{1 - \gamma}}\]其中 \(R_{max}\) 是 MDP 中任何给定时间步可能获得的最大奖励。通常,\(\gamma\) 严格选自范围 \(0 < \gamma < 1\),因为范围 \(-1 < \gamma \leq 0\) 中的值在大多数现实世界情况中根本没有意义——\(\gamma\) 为负值意味着状态 \(s\) 的奖励将在交替的时间步在正值和负值之间翻转。
4.1.2 马尔可夫性 (Markovianess)
马尔可夫决策过程是“马尔可夫的”,因为它们满足马尔可夫性质 (Markov property),或无记忆性质 (memoryless property),即给定现在,未来和过去是条件独立的。直观地说,这意味着,如果我们知道当前状态,知道过去并不能给我们更多关于未来的信息。为了用数学表达这一点,考虑一个代理在某个 MDP 中采取动作 \(a_0, a_1, ..., a_{t-1}\) 后访问了状态 \(s_0, s_1, ..., s_t\),并且刚刚采取了动作 \(a_t\)。给定其访问过的先前状态和采取的动作的历史,该代理随后到达状态 \(s_{t+1}\) 的概率可以写成如下: \(P(S_{t+1} = s_{t+1} \mid S_t = s_t, A_t = a_t, S_{t-1} = s_{t-1}, A_{t-1} = a_{t-1}, ..., S_0 = s_0)\)
其中每个 \(S_t\) 表示代表我们代理状态的随机变量,\(A_t\) 表示代表我们代理在时间 \(t\) 采取的动作的随机变量。马尔可夫性质指出,上述概率可以简化如下: \(P(S_{t+1} = s_{t+1} \mid S_t = s_t, A_t = a_t, S_{t-1} = s_{t-1}, A_{t-1} = a_{t-1}, ..., S_0 = s_0) = P(S_{t+1} = s_{t+1} \mid S_t = s_t, A_t = a_t)\)
这是“无记忆的”,因为在时间 \(t+1\) 到达状态 \(s'\) 的概率仅取决于时间 \(t\) 的状态 \(s\) 和采取的动作 \(a\),而不取决于任何更早的状态或动作。事实上,正是这些无记忆概率由转移函数编码:\(\boxed{T(s, a, s') = P(s' \mid s, a)}\)。