7.2 决策网络 (Decision Networks)
之前我们学习了博弈树和诸如 minimax 和 expectimax 之类的算法,我们使用它们来确定最大化我们期望效用的最佳动作。然后在第五篇笔记中,我们讨论了贝叶斯网络以及我们如何使用我们知道的证据来运行概率推理以进行预测。现在我们将讨论贝叶斯网络和 expectimax 的结合,称为决策网络 (decision network),我们可以使用它基于总体图形概率模型来模拟各种动作对效用的影响。让我们直接深入了解决策网络的解剖结构:
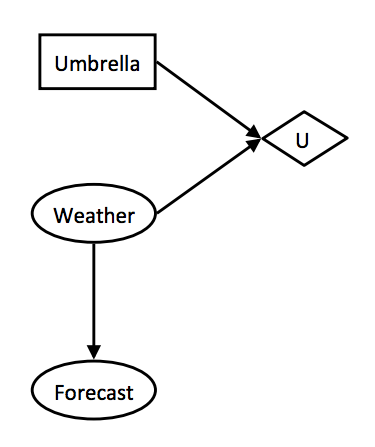
- 机会节点 (Chance nodes) - 决策网络中的机会节点与贝叶斯网络中的行为相同。机会节点中的每个结果都有一个相关的概率,可以通过在其所属的底层贝叶斯网络上运行推理来确定。我们将用椭圆表示这些节点。
- 动作节点 (Action nodes) - 动作节点是我们完全控制的节点;它们代表在我们可以选择的多个动作之间进行选择的节点。我们将用矩形表示动作节点。
- 效用节点 (Utility nodes) - 效用节点是动作节点和机会节点某种组合的子节点。它们根据其父节点取的值输出效用,并在我们的决策网络中表示为菱形。
考虑这样一种情况:当你早上离开去上课时,你正在决定是否带伞,你知道预报有 30% 的降雨概率。你应该带伞吗?如果有 80% 的降雨概率,你的答案会改变吗?这种情况非常适合用决策网络建模,我们这样做如下:
正如我们在本课程中讨论的各种建模技术和算法所做的那样,我们使用决策网络的目标再次是选择产生最大期望效用 (maximum expected utility) (MEU) 的动作。这可以通过一个相当直接和直观的过程来完成:
- 首先实例化所有已知的证据,并运行推理以计算动作节点馈入的效用节点的所有机会节点父节点的后验概率。
-
遍历每个可能的动作,并计算在给定前一步计算的后验概率的情况下采取该动作的期望效用。给定证据 \(e\) 和 \(n\) 个机会节点,采取动作 \(a\) 的期望效用使用以下公式计算:
\[EU(a \mid e) = \sum_{x_1, ..., x_n}P(x_1, ..., x_n \mid e)U(a, x_1, ..., x_n)\]其中每个 \(x_i\) 代表第 \(i\) 个机会节点可以取的值。我们只是对给定动作下每个结果的效用进行加权求和,权重对应于每个结果的概率。
- 最后,选择产生最高效用的动作以获得 MEU。
让我们看看这实际上是什么样子的,通过计算我们的天气示例的最佳动作(我们应该不带还是带伞),使用给定恶劣天气预报的天气的条件概率表(预报是我们的证据变量)和给定我们的动作和天气的效用表:
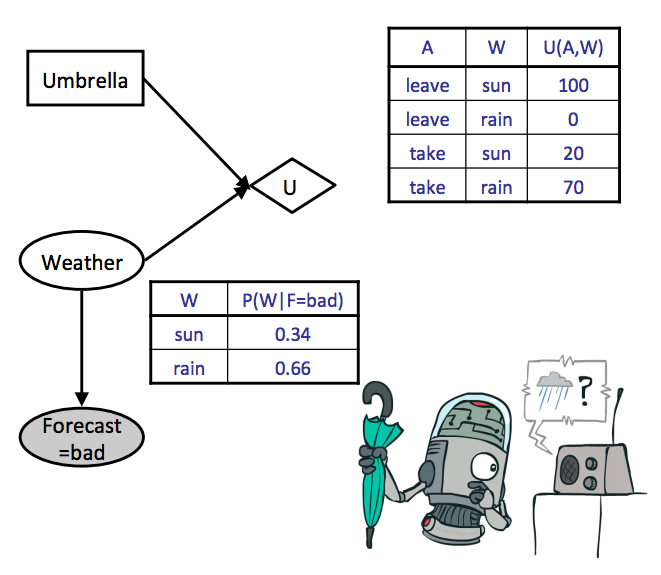
注意我们省略了后验概率 $P(W \mid F = \text{bad})$ 的推理计算,但我们可以使用我们为贝叶斯网络讨论的任何推理算法来计算这些。相反,在这里我们简单地假设上述后验概率表 $P(W \mid F = \text{bad})$ 是给定的。遍历我们的两个动作并计算期望效用得出:
\[\begin{aligned} EU(\text{leave} \mid \text{bad}) &= \sum_{w}P(w \mid \text{bad})U(\text{leave}, w) \\ &= 0.34 \cdot 100 + 0.66 \cdot 0 = \boxed{34} \\ EU(\text{take} \mid \text{bad}) &= \sum_{w}P(w \mid \text{bad})U(\text{take}, w) \\ &= 0.34 \cdot 20 + 0.66 \cdot 70 = \boxed{53} \end{aligned}\]剩下的就是取这些计算出的效用的最大值来确定 MEU:
\[MEU(F = \text{bad}) = \max_aEU(a \mid \text{bad}) = \boxed{53}\]产生最大期望效用的动作是带伞 (take),所以这是决策网络向我们推荐的动作。更正式地说,产生 MEU 的动作可以通过对期望效用取 argmax 来确定。
7.2.1 结果树 (Outcome Trees)
我们在本笔记的开头提到决策网络涉及一些类似 expectimax 的元素,所以让我们讨论一下这到底意味着什么。我们可以将决策网络中对应于最大化期望效用的动作的选择解开为结果树 (outcome tree)。我们上面的天气预报示例解开为以下结果树:
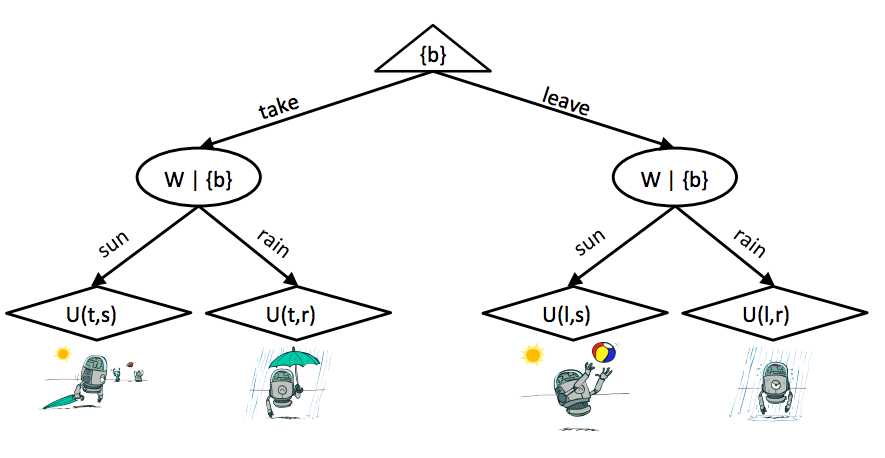
顶部的根节点是一个最大化器节点,就像在 expectimax 中一样,由我们控制。我们选择一个动作,这把我们带到树的下一层,由机会节点控制。在这一层,机会节点以对应于从底层贝叶斯网络上运行的概率推理得出的后验概率的概率,解析为最后一层的不同效用节点。这与普通的 expectimax 究竟有什么不同?唯一的真正区别是,对于结果树,我们在节点上注释了我们在任何给定时刻所知道的内容(在大括号内)。